Kimi k2.5 Review: Native Multimodality and Agent Swarms at 1 Trillion Parameters
The KIMI K2.5 represents a significant step forward for open-source multimodal AI by tackling two converging frontiers simultaneously: native text-vision integration and scalable agentic intelligence. Unlike many contemporary models that augment a predominantly text-based backbone with vision tokens late in training, K2.5 adopts joint pre-training and reinforcement learning across text and visual data — enabling both modalities to mutually strengthen one another rather than competing for capacity. This design choice, along with novel techniques like zero-vision supervised fine-tuning, positions the model as a unified multimodal system capable of complex perception and reasoning tasks.
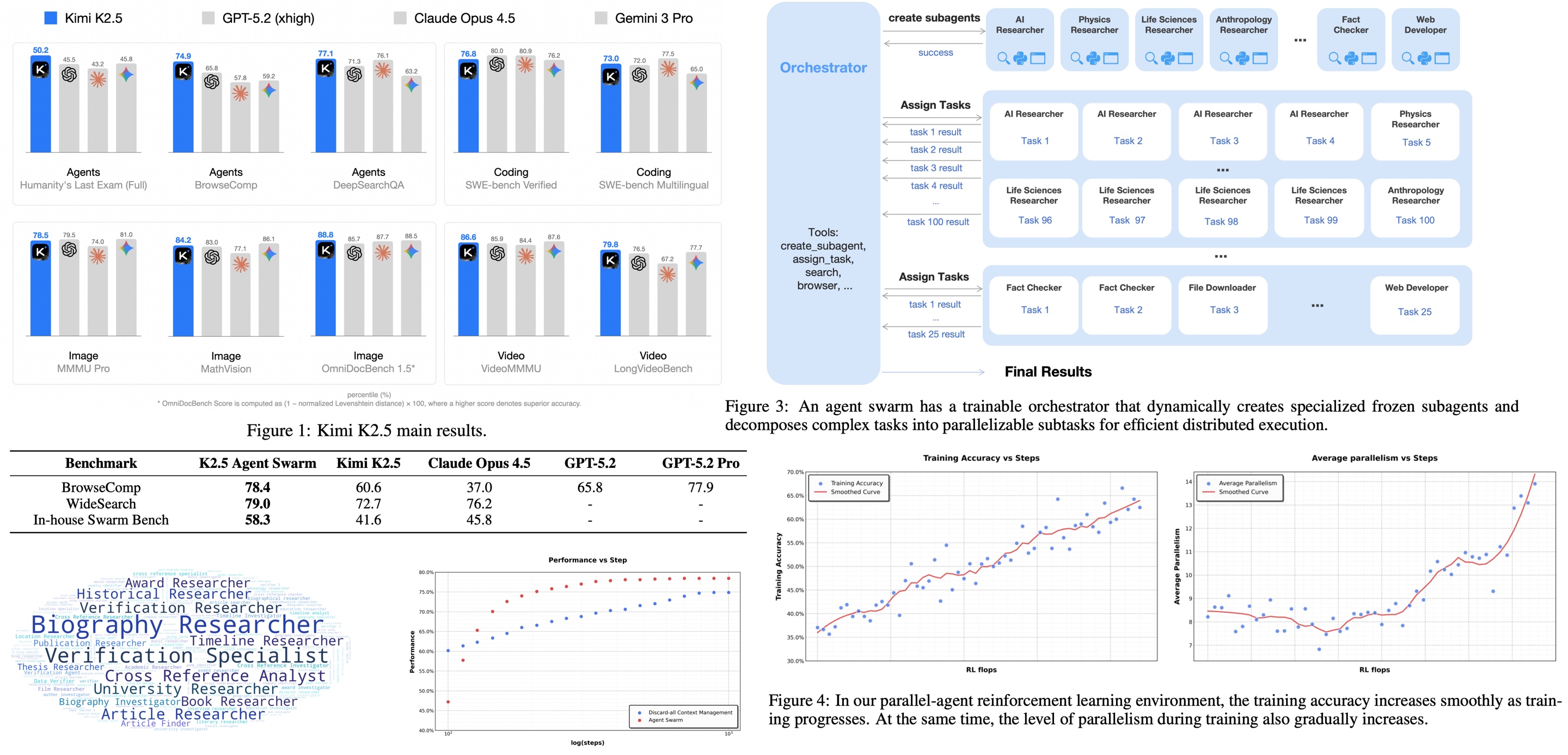
Finally, K2.5 introduces Agent Swarm, a dynamic framework for parallel agent orchestration that yields up to ~4.5x reduction in inference latency and higher task performance compared to traditional sequential agent execution. It allows the model to dynamically decompose a prompt into a graph of heterogeneous sub-tasks, instantiate specialized agents for each, and execute them concurrently
Benchmark results show Kimi k2.5 achieving state-of-the-art (SOTA) performance in coding, math, and visual agentic tasks, outperforming comparable open-source models and rivaling proprietary giants like GPT-5.2 in specific high-reasoning domains.
Joint Optimization of Text and Vision
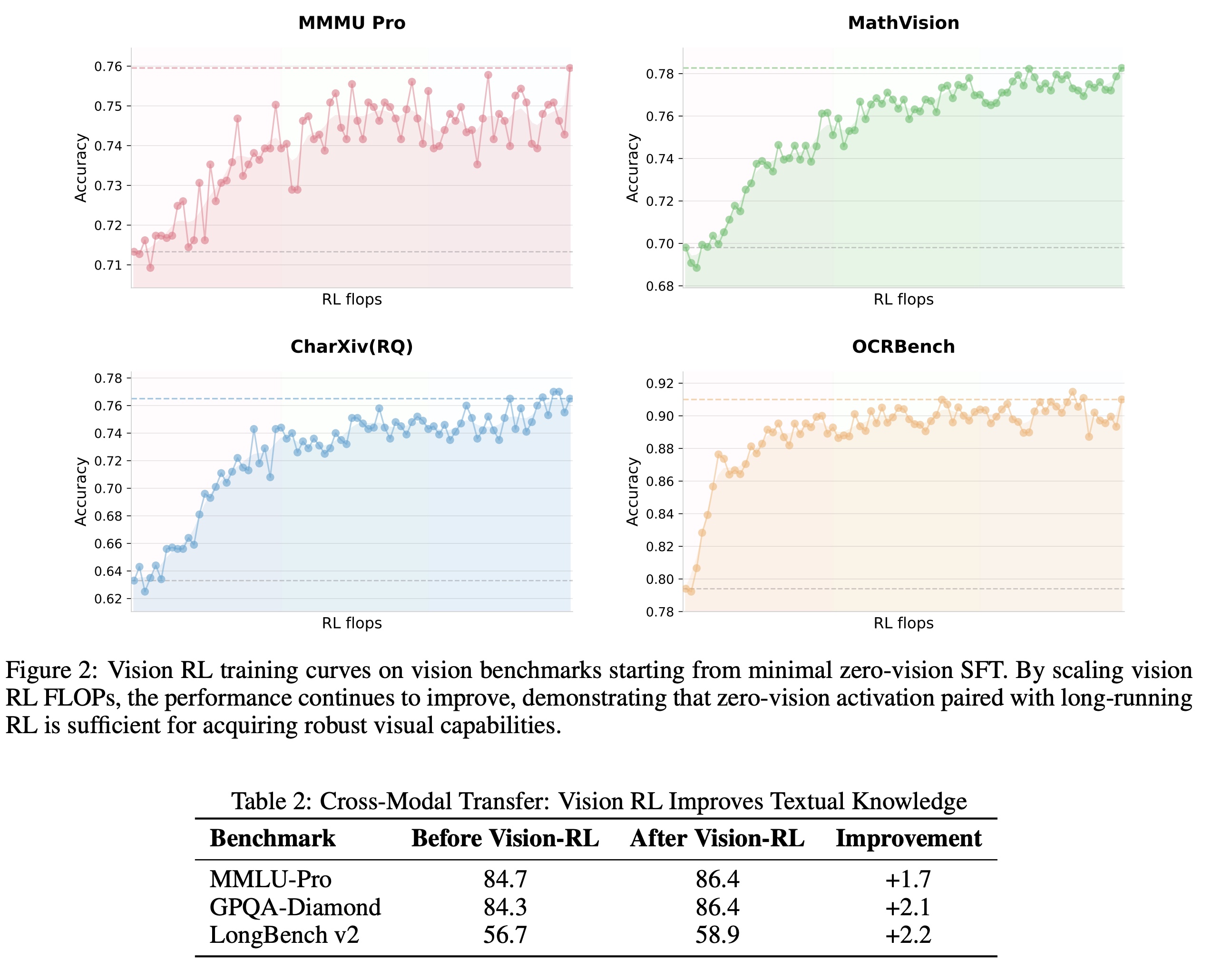
Kimi K2.5 is trained as a native multimodal model via large-scale joint pre-training on ~15T mixed text and vision tokens. Contrary to common practice, the authors show that aggressively injecting large amounts of vision data late in training is unnecessary. With a fixed token budget, early fusion with a moderate vision ratio performs better than late, vision-heavy training. This results in a novel design choice: integrate vision early and co-optimize both modalities throughout training to learn balanced multimodal representations.
To address the cold-start problem in multimodal reinforcement learning, the authors introduce zero-vision SFT. Instead of using scarce, hand-annotated vision SFT data, K2.5 uses high-quality text-only SFT, with visual operations proxied via programmatic operations in IPython. Experiments show that this is sufficient to activate visual and agentic behaviors, likely due to prior joint pre-training. And the usual text–vision SFT performs worse due to limited data quality.
Finally, K2.5 applies outcome-based visual RL on tasks that explicitly require vision (grounding, counting, charts, STEM problems). This improves visual reasoning and agentic behavior and also boosts text-only performance on benchmarks like MMLU-Pro, GPQA, and LongBench. At the post-training stage, the model is trained with joint multimodal RL, where experts are organized by ability (reasoning, coding, agentic skills) rather than modality. This paradigm maximizes cross-modal transfer, allowing improvements in vision to generalize to text and vice versa, without degrading language performance.
Agent Swarm

The authors argue that sequential agent execution is a fundamental bottleneck for complex, long-horizon tasks. As tasks grow wider (information gathering) and deeper (branching reasoning), a single agent quickly exhausts reasoning depth and tool-call budgets, making purely sequential systems poorly scalable.
To address this, Kimi K2.5 introduces Agent Swarm with Parallel Agent Reinforcement Learning (PARL). Instead of hard-coded parallelism or fixed heuristics, the model learns when and how to parallelize via RL. An orchestrator dynamically decomposes tasks, spawns heterogeneous subagents, and schedules them to run concurrently. Parallelism is not assumed to be beneficial by default; it emerges through reward-driven exploration based on task outcomes and efficiency.
PARL uses a decoupled architecture: a trainable orchestrator coordinates frozen subagents sampled from intermediate checkpoints. This avoids unstable end-to-end multi-agent training and sidesteps credit-assignment issues, treating subagent outputs as environmental observations rather than differentiable actions. Training starts with smaller subagents and progressively scales up, with dynamic resource allocation between the orchestrator and subagents.
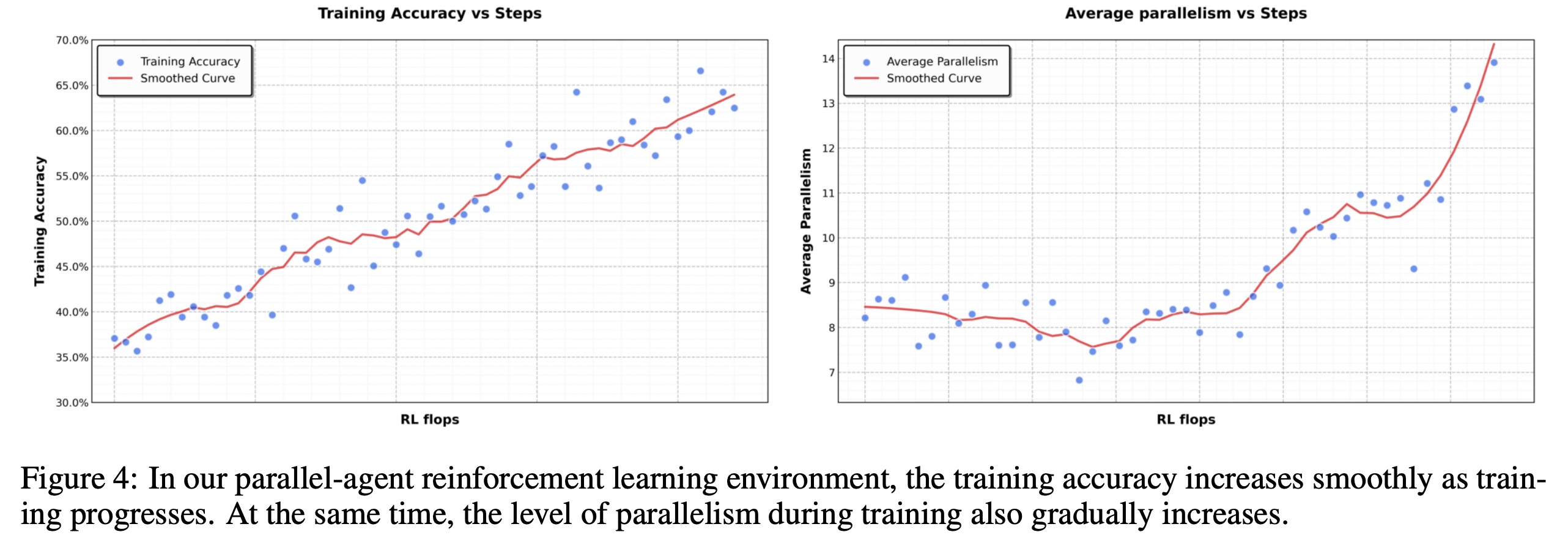
The reward function combines task performance with two auxiliary terms: one encourages subagent instantiation (to avoid collapsing back to serial execution), and another rewards successful subtask completion (to prevent meaningless parallelism). These auxiliary rewards are annealed to zero over the course of training, ensuring the final policy optimizes task quality.
To explicitly optimize latency, the authors introduce critical steps, a metric similar to the critical path in parallel computation. Training and evaluation are constrained by critical steps rather than total steps, which incentivizes decompositions that reduce end-to-end execution time instead of merely increasing concurrency.
Finally, the orchestrator is trained on synthetic stress-test prompts designed to break sequential agents, emphasizing wide search, deep branching, and real-world workloads like long-document analysis. Without explicitly instructing parallelism, the task distribution naturally favors parallel execution, teaching the orchestrator to exploit Agent Swarm where it provides real benefit.
The general approach
Kimi K2.5 is built on Kimi K2, a trillion-parameter MoE language model trained on 15T text tokens, and extends it into a native multimodal, agentic system. Kimi K2 MoE LLM is combined with MoonViT-3D, a native-resolution vision encoder, connected via an MLP projector. MoonViT-3D unifies image and video understanding by sharing parameters and embedding space across both modalities, treating short video clips as spatiotemporal “patch-and-pack” sequences. This helps to avoid specialized video modules while enabling efficient long-video processing through lightweight temporal pooling and compression.
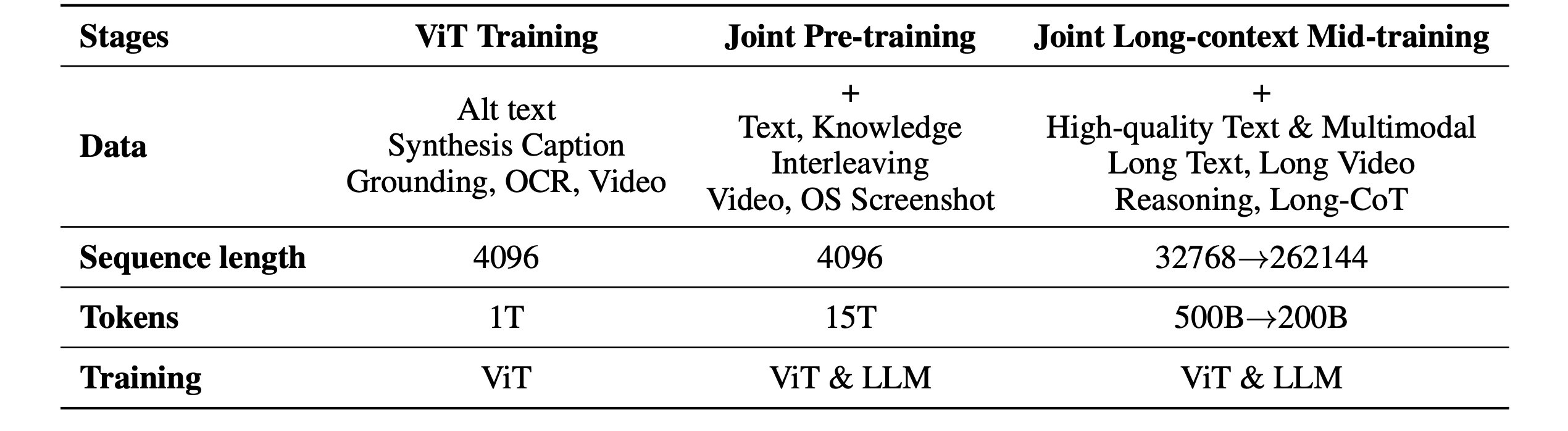
Pre-training proceeds in three stages over ~15T additional multimodal tokens:
- standalone ViT training to build a strong visual encoder from image–text and video–text data;
- joint text–vision pre-training starting from a near-final Kimi K2 checkpoint to co-optimize language and multimodal capabilities;
- mid-training with higher-quality data and long-context activation, progressively extending context length via YaRN interpolation.
Post-training follows large-scale SFT + RL. Supervised fine-tuning uses synthesized high-quality responses from multiple Kimi variants and expert models, emphasizing reasoning depth and tool use. Reinforcement learning is unified across text, vision, and agentic behaviors using a shared agentic RL environment. The policy optimization uses token-level clipping to stabilize off-policy RL in long-horizon, tool-using settings, paired with outcome-based and GRM-based rewards. Visual tasks use task-specific reward formulations (IoU, edit distance, counting error, etc), while Generative Reward Models provide fine-grained preference signals across diverse agent types.
Evaluations
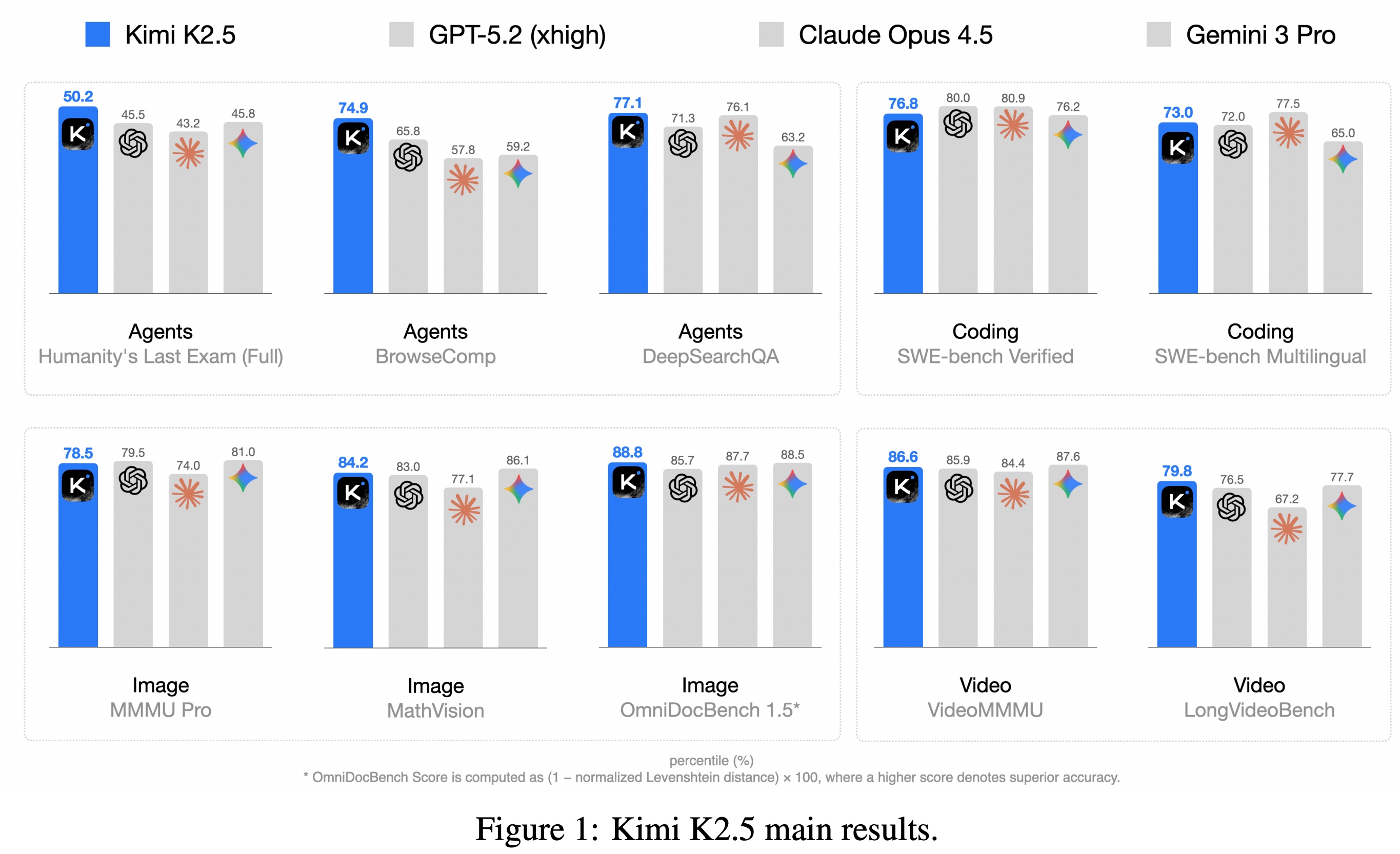
Kimi K2.5 delivers frontier-level performance across reasoning, coding, agentic, and multimodal benchmarks, often matching or surpassing leading proprietary models. It shows strong STEM and scientific reasoning (AIME, HMMT, MMLU-Pro, GPQA), clear gains from tool use on HLE, and competitive real-world software engineering performance (SWE-Bench, LiveCodeBench, CyberGym).
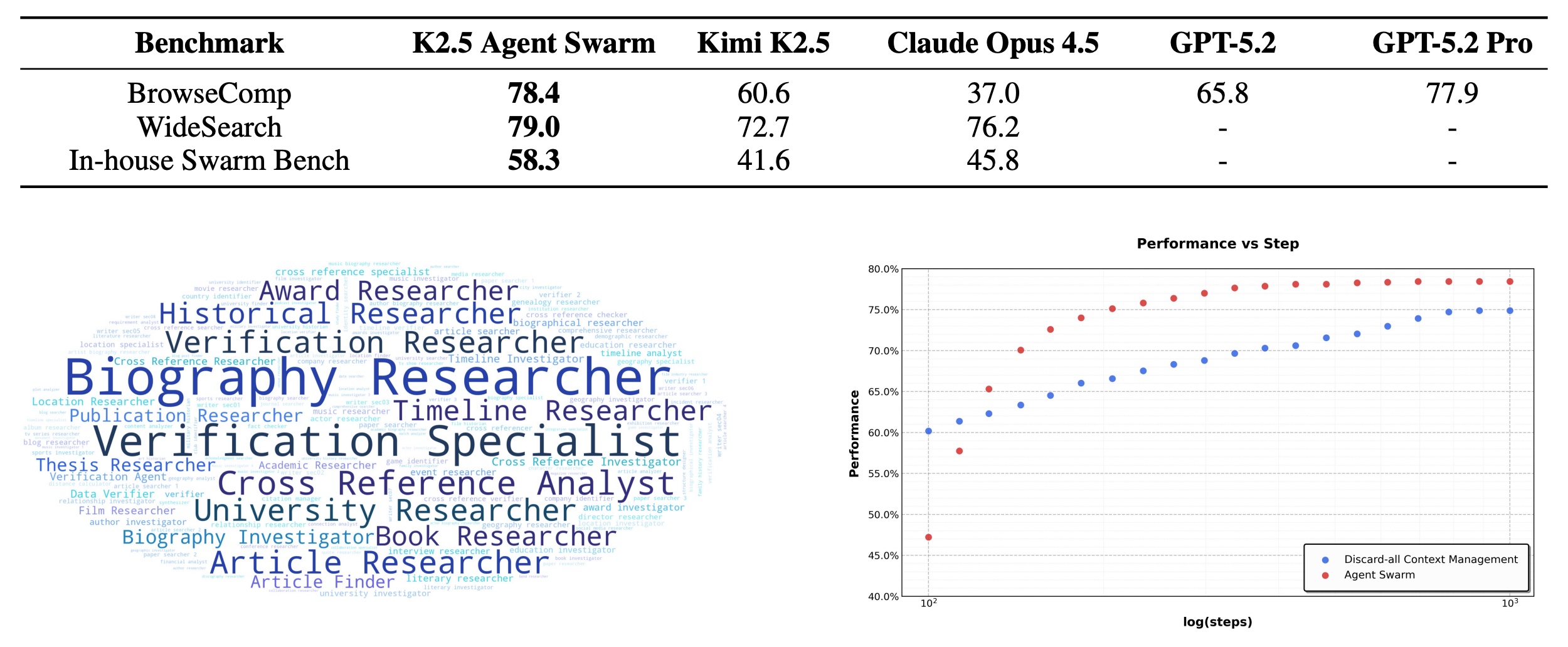
The Agent Swarm delivers large gains beyond the base model: multi-agent orchestration consistently improves performance over single-agent K2.5 and often surpasses GPT-5.2 Pro. These gains are paired with latency reductions: parallel execution yields 3–4.5x wall-clock speedups, with execution time remaining nearly constant as task difficulty increases.
Additionally, Agent Swarm functions as proactive context management: tasks are decomposed into parallel, semantically isolated subtasks handled by specialized subagents with bounded local context. Only distilled results are returned to the orchestrator, enabling context sharding rather than context truncation. This allows K2.5 to scale to long-horizon, high-complexity tasks while preserving reasoning integrity and modularity.
Conclusions
Kimi k2.5 positions itself as a strong open-source competitor in the agentic domain, directly challenging GPT-5.2 and Claude Opus 4.5. Kimi k2.5 differentiates itself from other models thanks to its native visual capabilities.
I really like the Agent Swarm orchestration introduced here. Most current models rely on long, linear contexts that degrade in speed as complexity increases. Kimi k2.5 breaks this “linear curse” by parallelizing the reasoning process. The fact that Anthropic already implemented this functionality shows that it was a great idea.
paperreview deeplearning llm vlm visual mllm