Paper Review: VirTex: Learning Visual Representations from Textual Annotations

The authors offer an alternative approach to pre-training backbones for CV tasks - using semantically dense captions to learn visual representations. VirTex (CNN + Transformer) is pre-trained on COCO captions. On downstream tasks, it can reach performance similar to pre-training on ImageNet, but with 10x fewer images.
Language has higher semantic density than images. Therefore we expect that textual annotations can be used to learn visual representations using fewer images than other approaches. Also, it is easier to get data annotations this way.

Method
The image captioning model has two parts: visual backbone and textual head.
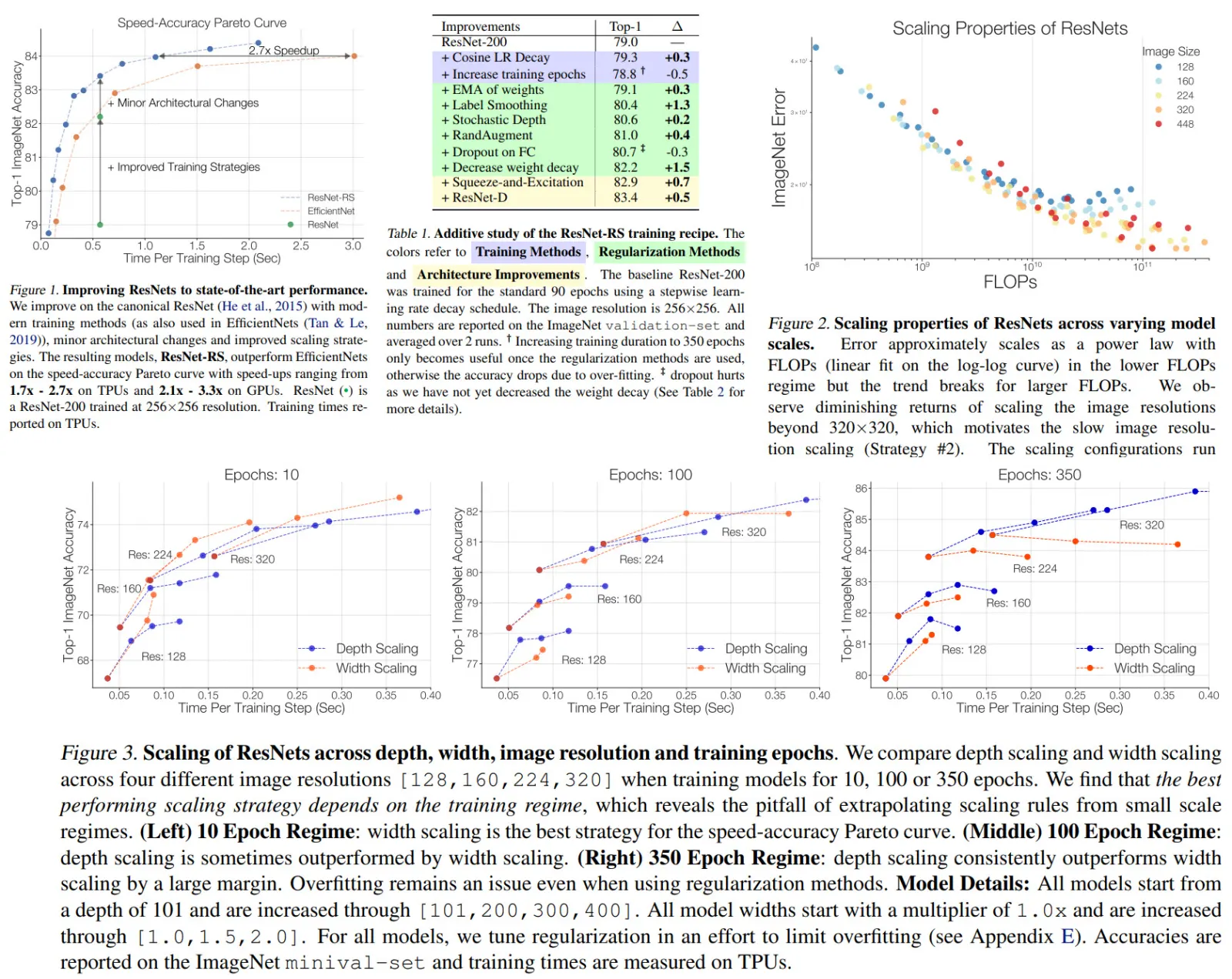
Textual head accepts features extracted by backbone and predicts caption token by token. It provides bidirectional captioning, so it predicts tokens twice - left-to-right and right-to-left.
The model maximizes the log-likelihood of the correct caption tokens. Only the backbone is used for downstream tasks.
Authors tried using masked language models, but they trained slower.
A backbone can be any CNN. Authors used ResNet-50 on 224x224 images.
The textual head consists of two Transformers for predicting tokens in two directions. It takes as input extracted visual features and tokenized captions (SentencePiece with BPE with little tricks).
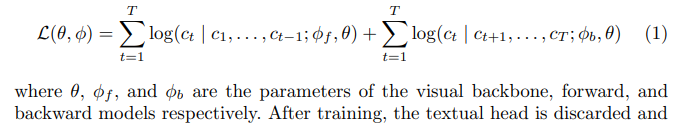
Model is trained on train2017 split of the COCO Captions. 8 GPU are used, the batch size is 256. Authors use standard augmentations, SGD with LookAhead.\
Model is trained for 1080 epochs (500k iterations). Wow!
It is interesting how they do early stopping. Performance on image captioning doesn’t correlate well with performance on downstream tasks. So they use performance on PASCAL VOC as a metric for early stopping.
Experiments
VerTex backbone is compared to the following approaches:
- Random. CNN without pre-training
- ImageNet-supervised (IN-sup). Models trained on ILSVRC 2012. Well, default torchvision models: https://github.com/pytorch/vision
- PIRL. A self-supervised method for learning visual features by encouraging learned representations to be invariant to transformations. https://arxiv.org/abs/1912.01991
- MoCo. A self-supervised contrastive method for learning visual features that scales to large batches using a momentum-based encoder and a queue. MoCo-IN: - trained on ImageNet, MoCO-COCO - trained on COCO with default hyperparameters. All models use ResNet-50.
Image Classification with Linear Models
VerTex requires much fewer images to get similar performance to other approaches, as we can see from the plots. It even reaches mAP 87.4 on VOC07, which model pre-trained on ImageNet reaches 86.8 mAP.
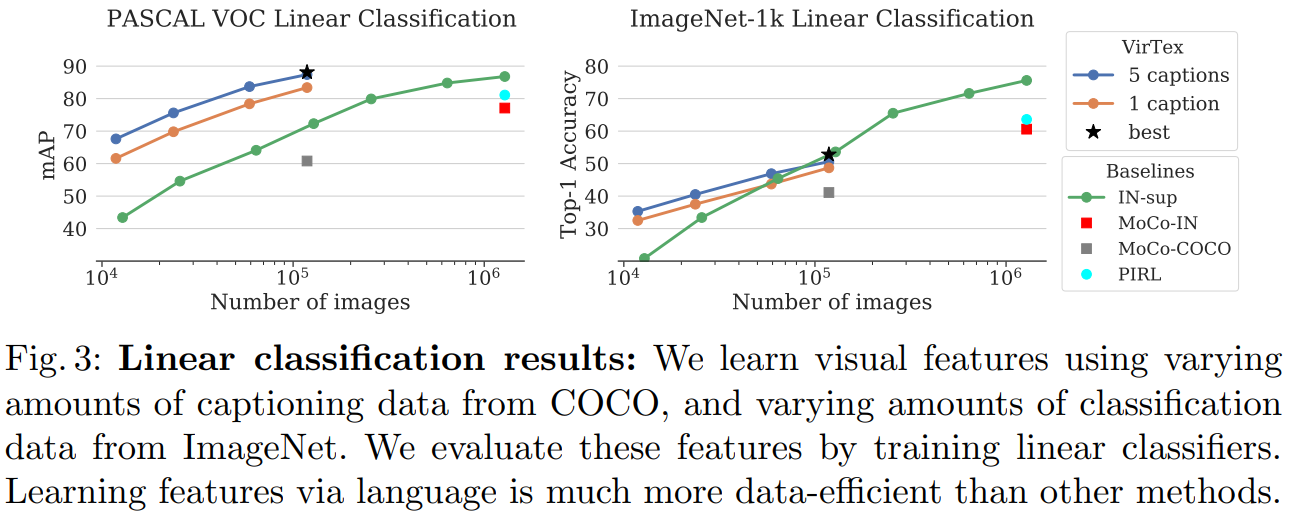
Ablation study
Bicaptioning is better than other approaches.
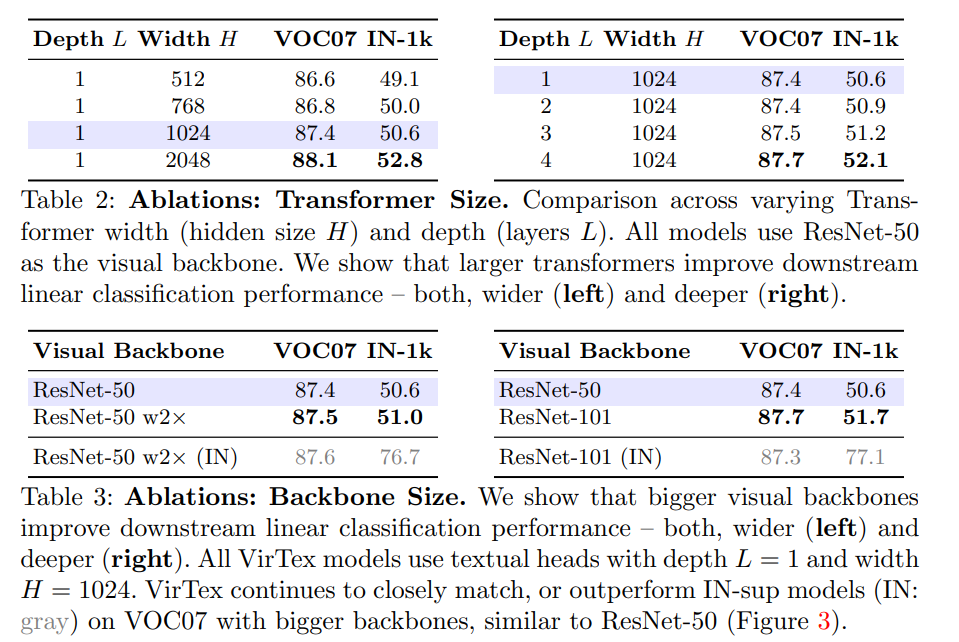
Bigger transformers and backbone improve performance.

Fine-tuning
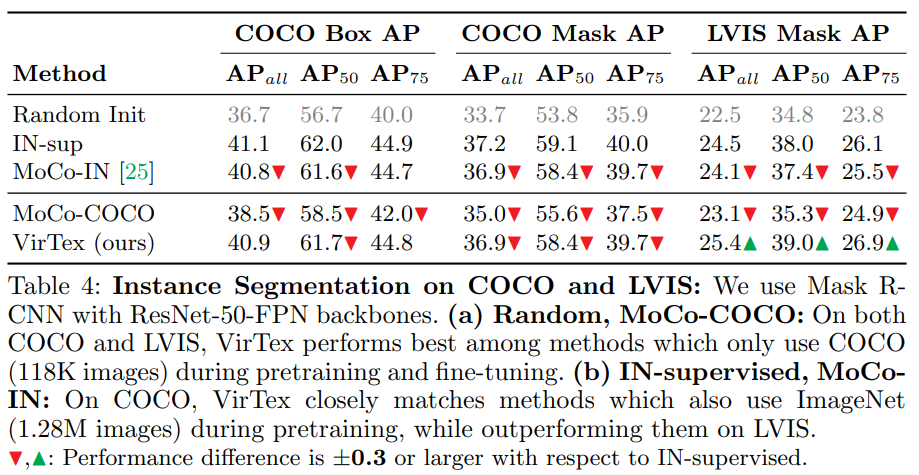
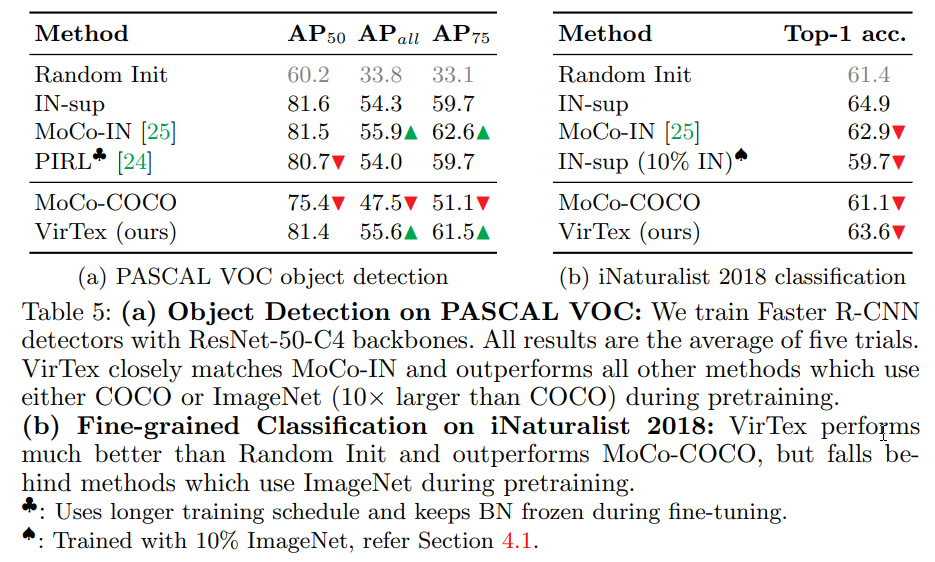
VerTex is outpaced only by ImageNet pre-trained models in most experiments, but we need to remember that we used much fewer images for VerTex pre-training.
And here, we can see the performance of the model on the image captioning task itself.
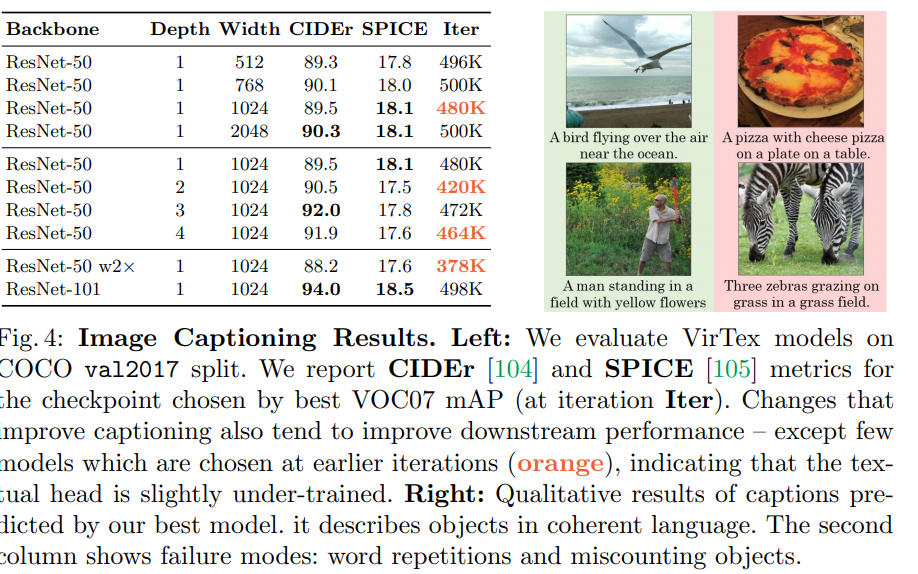
The appendix has additional info on implementation details and these cool visualizations of attention on image captioning tasks.

I think this is a cool paper, and it could be a start in applying CNN + Transformer approaches further on.
paperreview imagecaptioning cv visual annotation transformer pretraining transferlearning deeplearning multimodal