Paper Review: Efficient Visual Pretraining with Contrastive Detection
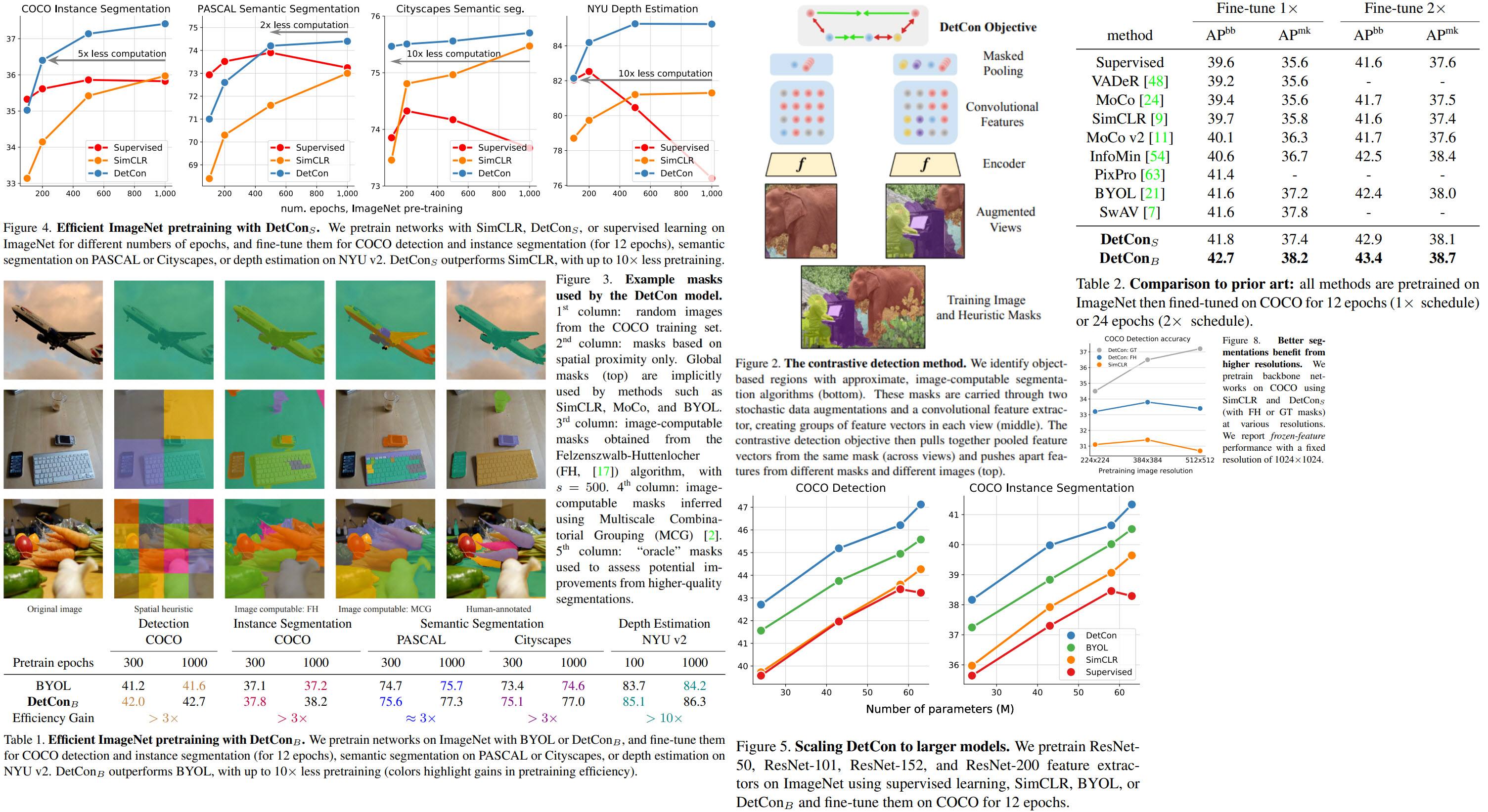
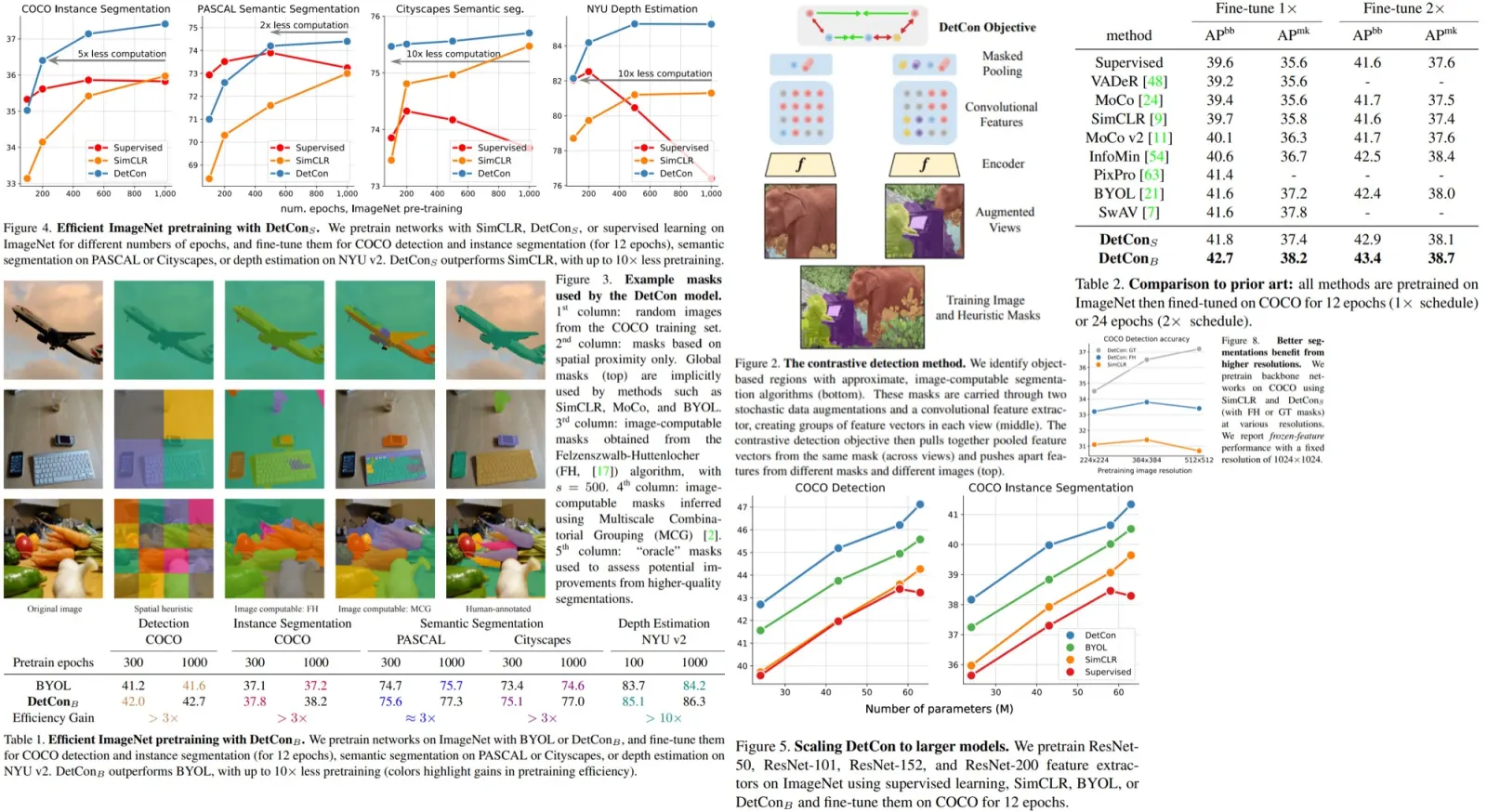
Self-supervised learning is a useful approach to learn good representations, but it requires a lot of data and has high computational costs. The authors of this paper introduce a new objective - contrastive detection: identifying object-level features across augmentations. As a result, models require up to 10x less pre-training.
In particular, their best ImageNet-pretrained model performs on par with SEER, one of the largest self-supervised systems to date, which uses 1000x more pre-training data. In addition, this new objective works well with complex images, closing the gap with supervised transfer learning from COCO to PASCAL.
The approach
To isolate the benefits of the new objective, the authors intentionally re-use elements of existing contrastive learning frameworks where possible.
They develop two versions: DetConS (based on SimCLR) and DetConB (based on BYOL). The authors use augmentations and architectures from those papers and use their contrastive detection loss.
Augmentation
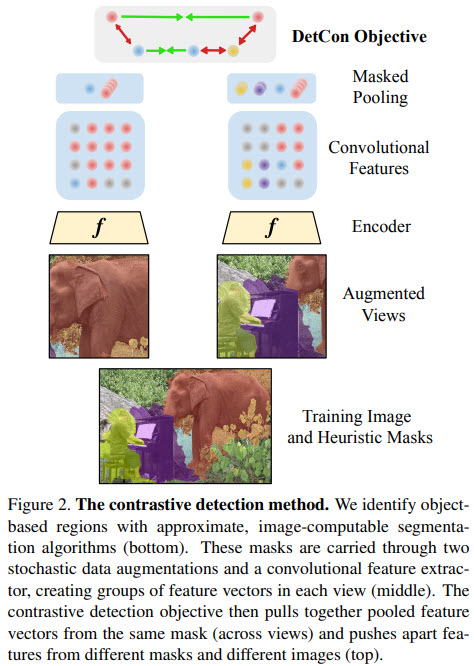
Each image is randomly augmented two times (output is 224x224). For each image a set of masks is computed that segments the image into components. These masks can be derived using unsupervised segmentation algorithms, or human-annotated segmentations can also be used. The masks are transformed using the same augmentations as their original images.
Architecture
ResNet-50 encoder is used to extract features from the images - 7x7 grid of 2048 dimensional vectors. We apply average pooling to spatially downsample the masks. Finally, we get projections from these vectors using a two-layer MLP.
For DetConS we use the same encoder and projection networks for both views.
As for DetConB, one view is processed by the one pair of encoder and projection networks; the other is processed using an exponential moving average of these networks. Then the first view is passed through a projection network.
All latent representations are rescaled with a temperature hyperparameter tau.
For downstream tasks only a feature extractor is used.
Objective: contrastive detection
Usually, contrastive learning is about recognizing the latent representations of augmented images in the presence of the negative samples. The authors include negative samples from different masks in the image and different images in the batch.
A natural extension of this loss would be to sample paired masks corresponding to the same region in the original image and maximize the similarity of features representing them. But the authors add several changes to this idea:
- at each iteration, a set of 16 (possibly redundant) masks is sampled from the variable-sized sets of masks;
- densely evaluate the similarity between all pairs of masks and all images, such that each image contributes 16 negative samples instead of one; mask out the loss to only maximize the similarity of paired locations (objects that are present on both views);
Unsupervised mask generation

- Spatial heuristic. Groups locations based on their spatial proximity only - the image is divided into an n x n grid of nonoverlapping, square sub-regions.
- Image-computable masks: Felzenszwalb-Huttenlocher algorithm. A classic segmentation procedure that iteratively merges regions using pixel-based affinity (Figure 3, 3rd column).
- Image-computable masks: Multiscale Combinatorial Grouping. This algorithm groups superpixels into many overlapping object proposal regions, guided by mid-level classifiers. For each image the authors use 16 MCG masks with the highest scores.
- Human annotated masks;
Evaluation
- Object detection and instance segmentation. The authors use the pre-trained network to initialize the feature extractor of a Mask-RCNN that has feature pyramid networks and cross-replica batch-norm;
- Semantic segmentation. The pre-trained network is used to initialize FCN;
- Depth Estimation. Stack the deconvolutional network on the top of the feature extractor;
Results
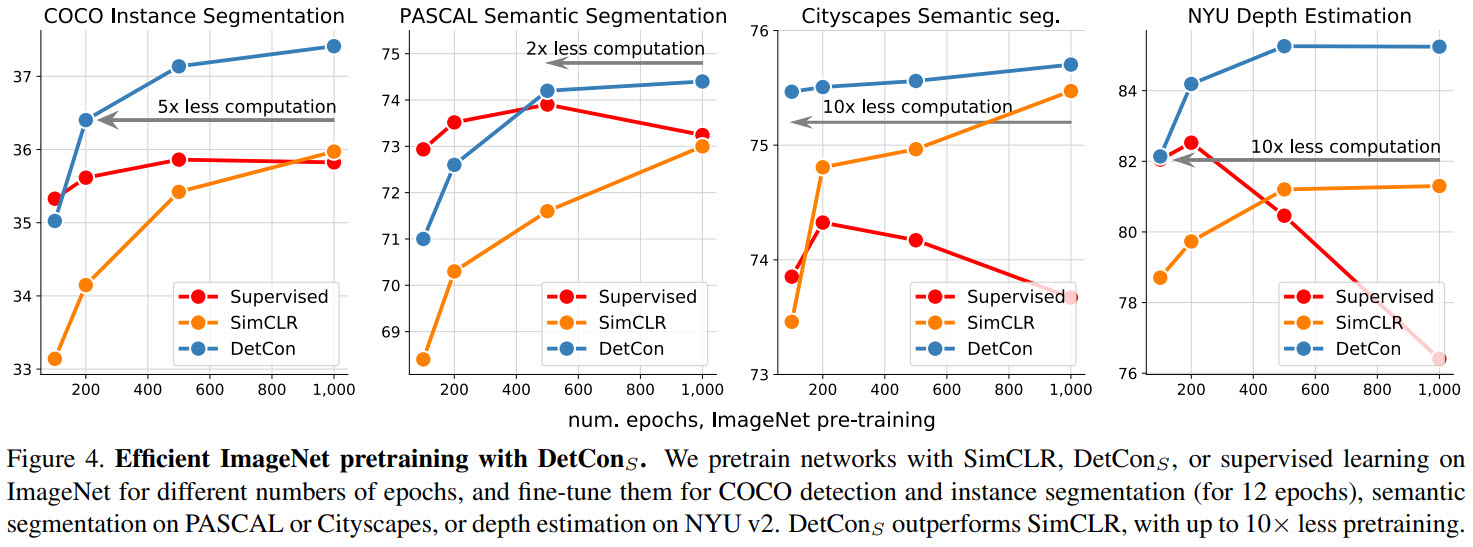
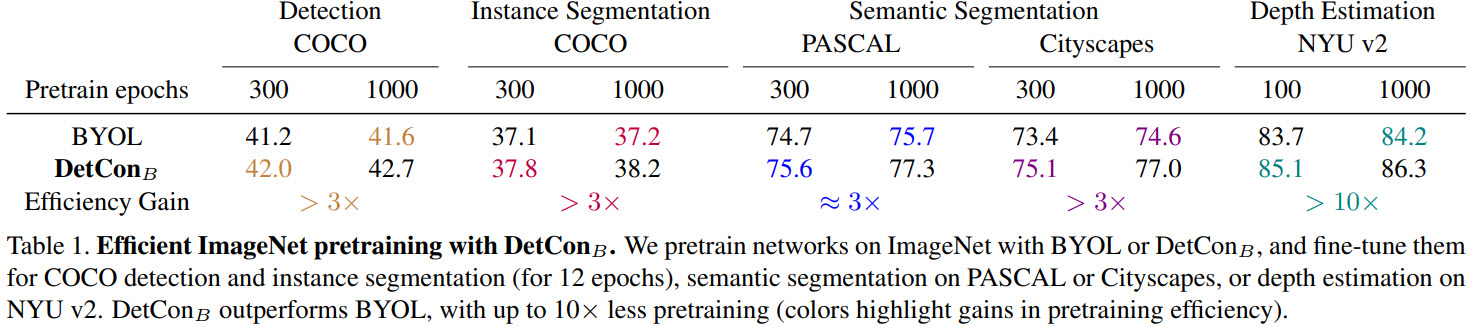
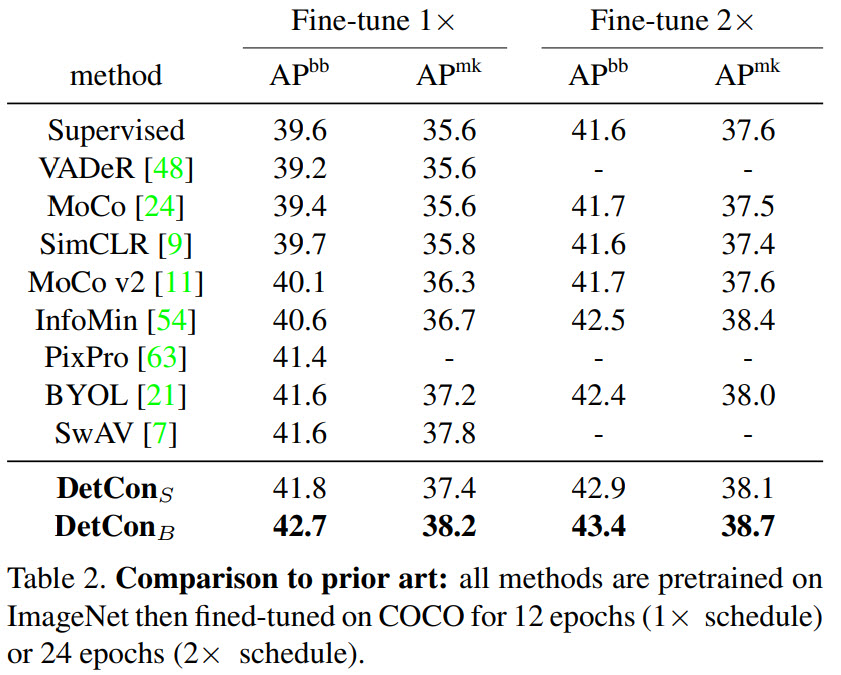
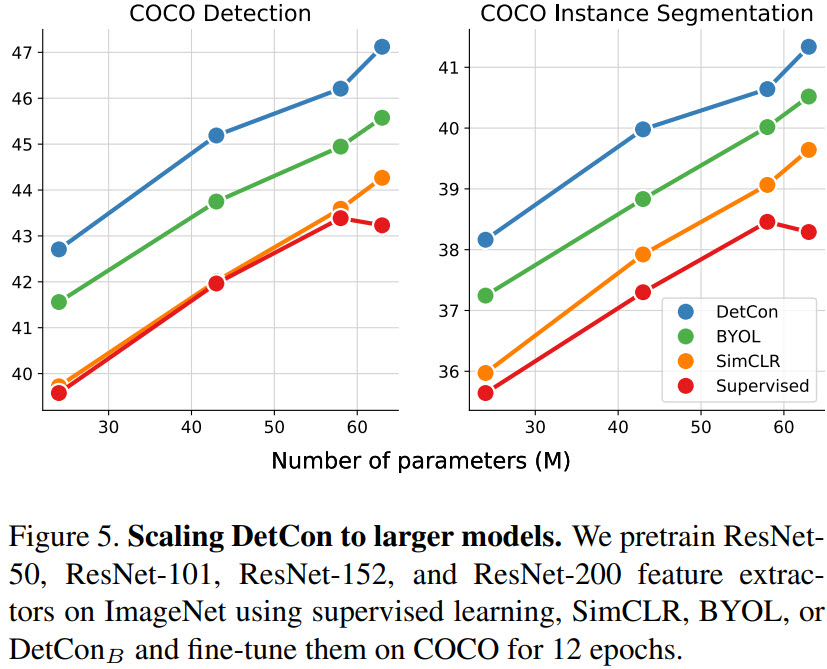

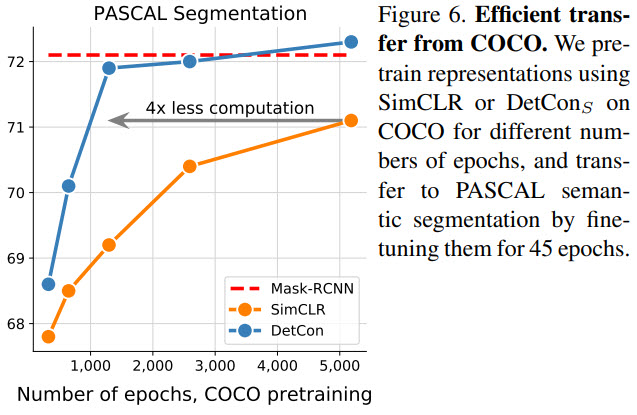
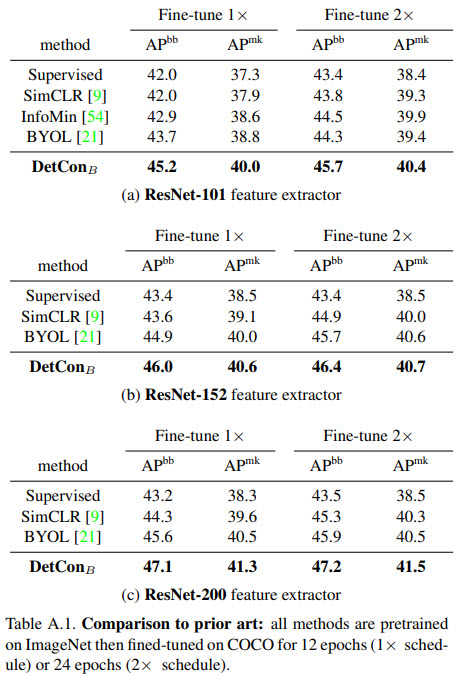
- DetConS pre-trained for 200 epochs is better than SimCLR pre-trained for 1000 epochs;
- DetConB yields a 2x gain in pretraining efficiency for PASCAL semantic segmentation and 10x for Cityscapes semantic segmentation and NYU depth prediction;
- In additional models scale well with model capacity (ResNet-101, 152, 200). In fact ResNet-200 variant is better than SEER, that is trained on 1000x more data;
Ablation
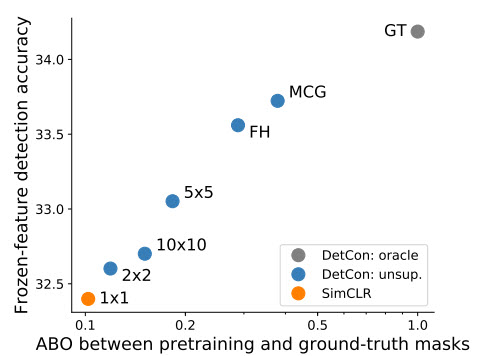
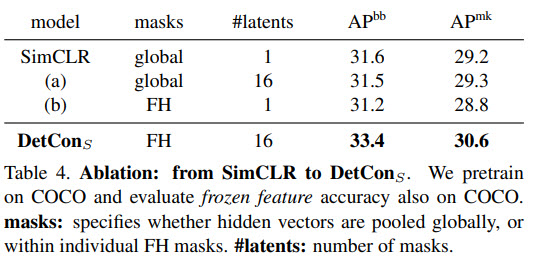
- the quality of the representation correlates very well with the overlap between pretraining masks and ground-truth — the better each ground truth object is covered by some mask, the better DetCon performs;
Using better segmentation
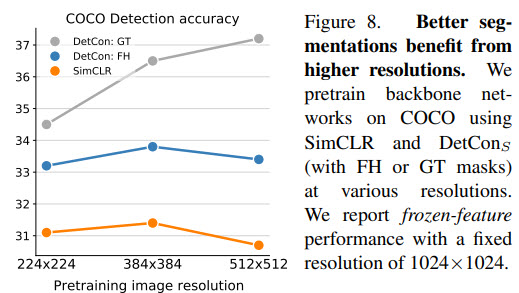

The ablations show that using better masks leads to the improvement of the model’s performance. In addition, they show that it is possible to improve the models even further if we change the approach after including the better masks.
- We can use higher image resolution while pre-training: Using 384x284 images instead of 224x224 benefits all models, but using 512x512 leads to the improvement only when we use ground truth masks.
- It isn’t necessary to use a lot of negative samples. In table
(a)shows the case when the number of negative samples was divided by 128. DetConS became even better; - It isn’t necessary to sample positive pairs across augmented views. In
(b)we sample a single augmentation for each image, and the similarity of mask-based features is maximized within this view;
The authors think that if the masks of the images are clean, then a small number of negative samples and positives from the same image provide enough signal.
paperreview deeplearning cv pretraining selfsupervised objectdetection