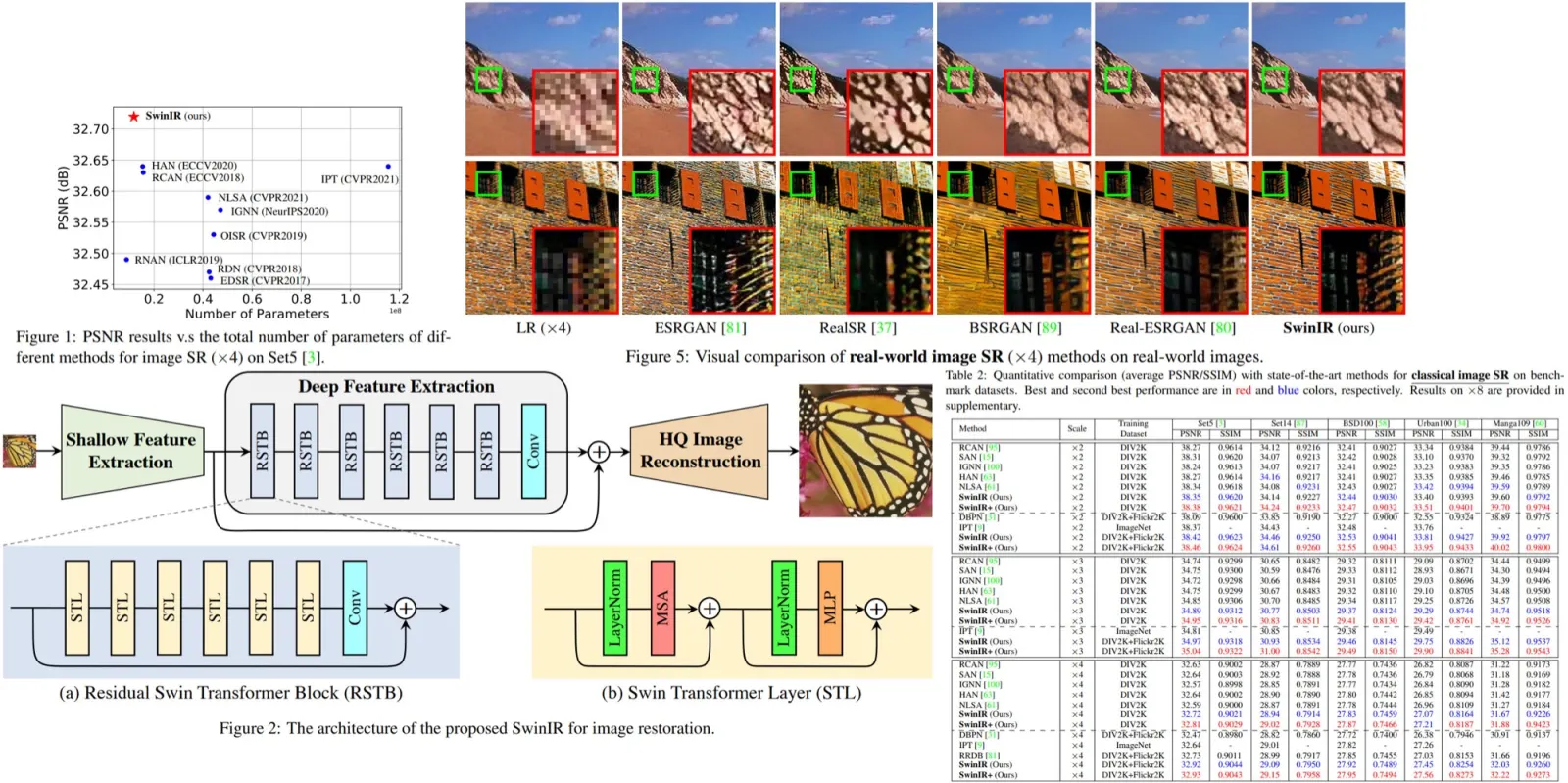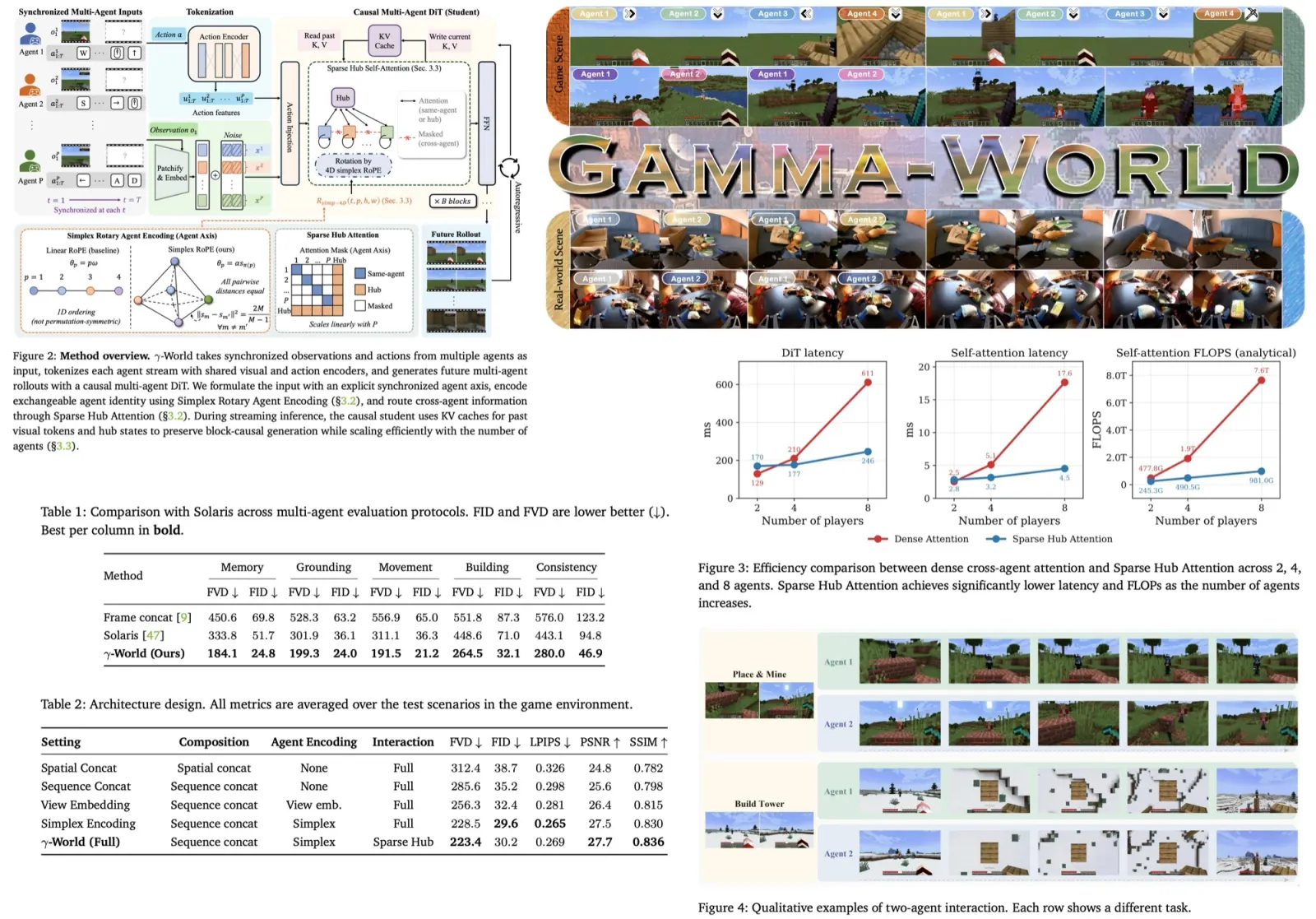
Gamma-World: Simplex Agent Encoding and Hub Attention for Multi-Agent World Models
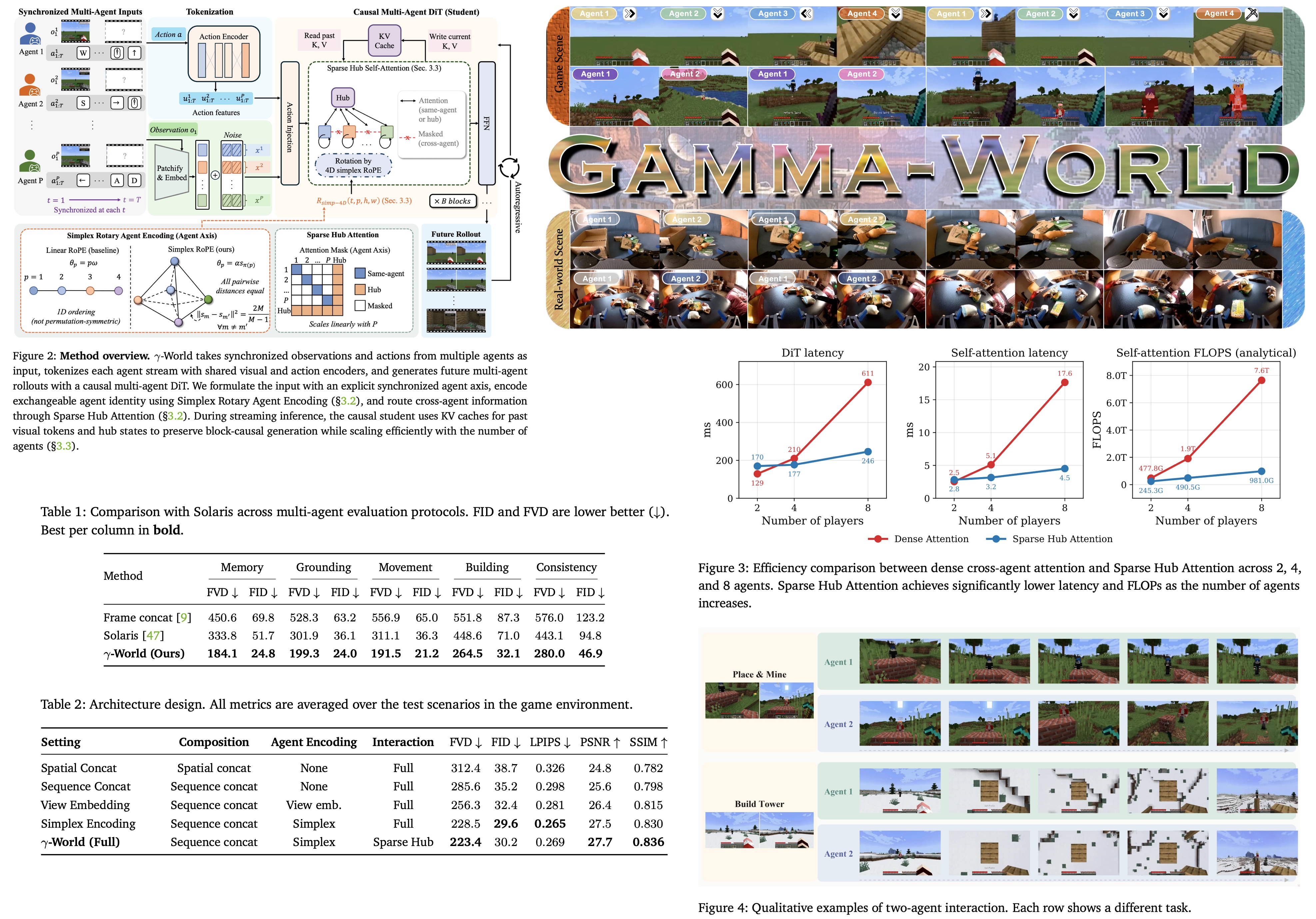
Most interactive video world models still assume a single agent: one user, one action stream, one generated future. γ-World adopts a harder, more realistic setting: several independently acting agents share the same evolving world. This is essential for games, robotics, embodied AI, social simulation, and agent training environments, where the key problem is not only visual fidelity, but whether multiple agents can act, interact, and remain consistent over time.
The paper’s central contribution is a clean multi-agent design for generative world modeling. It introduces Simplex Rotary Agent Encoding to represent agent identities without fixed slots or arbitrary ordering, Sparse Hub Attention to let agents exchange information without expensive all-to-all attention, and a teacher-student distillation setup that turns a full-context diffusion model into a causal streaming model. Gamma-World itself is a DiT-based latent video diffusion model trained with flow-matching, extended along an explicit agent axis. The result is a model that can produce action-responsive multi-agent rollouts in real time, while preserving independent controllability and even generalizing from two to four players without additional training.
The approach
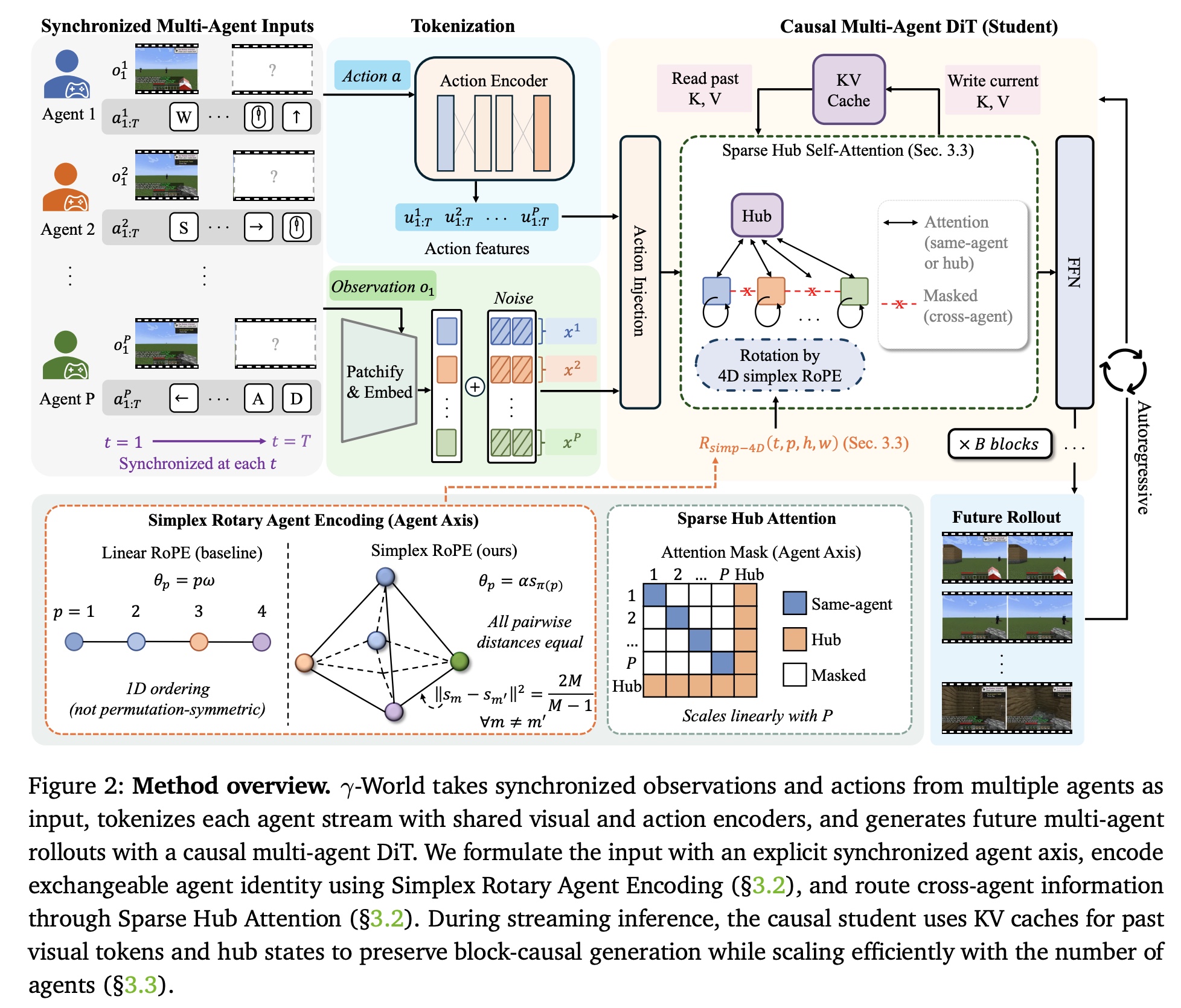
The model uses a transformer-based latent video diffusion model adapted for autoregressive generation, in which rotary position embeddings encode spatial and temporal locations. The authors modify this position embedding to account for agent identities and implement a multi-agent aware attention masking mechanism to reduce computational cost. The model is trained in two steps: a bidirectional teacher model and a causal student model that supports the streaming setting.
Unlike traditional world models that generate a future for a single player, γ-World generates futures for all agents simultaneously.
The model:
- Receives the first observation from each agent.
- Receives an action sequence for each agent.
- Predicts future observations for every agent jointly.
The key goal is consistency across agents and time. If agent A moves left and agent B observes agent A, both generated views should agree on what happened.
Shared Action Conditioning
Every agent has its own action sequence. A single shared encoder maps actions to latent representations, action features are injected into the transformer at every layer as additive biases. This means that each agent can be controlled independently while the parameters are shared.
Simplex Rotary Agent Encoding
Standard 3D RoPE gives video transformers rotary bands for time, height, and width. Simplex Rotary Agent Encoding (SRAE) adds a fourth band for agent identity: instead of assigning each agent a learned ID embedding, which fixes the roster and breaks symmetry the moment you reorder players, SRAE puts agents at the vertices of a regular simplex in rotary-angle space. Every pair of agents then sits at equal distance, so no agent is privileged, and the encoding does not care which slot a player occupies. The architecture never changes when an agent is added, which is what lets a model trained on two players accept four without retraining.
Sparse Hub Attention
The other half of the design is how agents share information. Dense all-to-all attention across agents is quadratic in the number of agents, so it scales poorly for large numbers of agents. Sparse Hub Attention (SHA) routes cross-agent interaction through a small set of learnable hub tokens that act as a compact representation of the environment state. Each agent attends to its own stream and to the hub tokens. The information flow is linear (agent -> hub -> agent) rather than quadratic.
This design significantly reduces computational cost while maintaining a communication pathway between agents. Together, these two ideas allow the model to generate coherent multi-agent rollouts, preserve consistency across viewpoints, and scale beyond the two-player settings that dominate most previous work.
Model training and inference
A major challenge in world modeling is balancing generation quality with real-time interactive inference. High-quality diffusion models typically rely on bidirectional attention, allowing them to look into the future during training, but this makes them unsuitable for online generation. Conversely, causal models support streaming generation but often suffer from exposure bias because they are trained on ground-truth histories while being evaluated on their own predictions.
γ-World uses a three-stage training pipeline:
- First, the authors train a powerful bidirectional teacher model that has access to the full multi-agent trajectory and can learn rich temporal dependencies and cross-agent interactions.
- Next, they train a causal student model using Diffusion Forcing, enabling autoregressive generation while preserving multi-agent communication through Sparse Hub Attention.
- Finally, the causal model is distilled into a few-step generator using Conditional Self-Forcing, where the model learns under its own rollout distribution and is encouraged to remain faithful to both the initial observations and the specified action sequences.
This training strategy allows γ-World to combine the strengths of both paradigms: the visual quality and consistency of diffusion models with the low-latency streaming capabilities required for interactive simulation. During inference, the distilled model generates future blocks autoregressively using KV-cached attention, while maintaining cross-agent coordination through shared hub states. The result is a real-time multi-agent world model capable of streaming coherent rollouts at 24 FPS.
Experiments
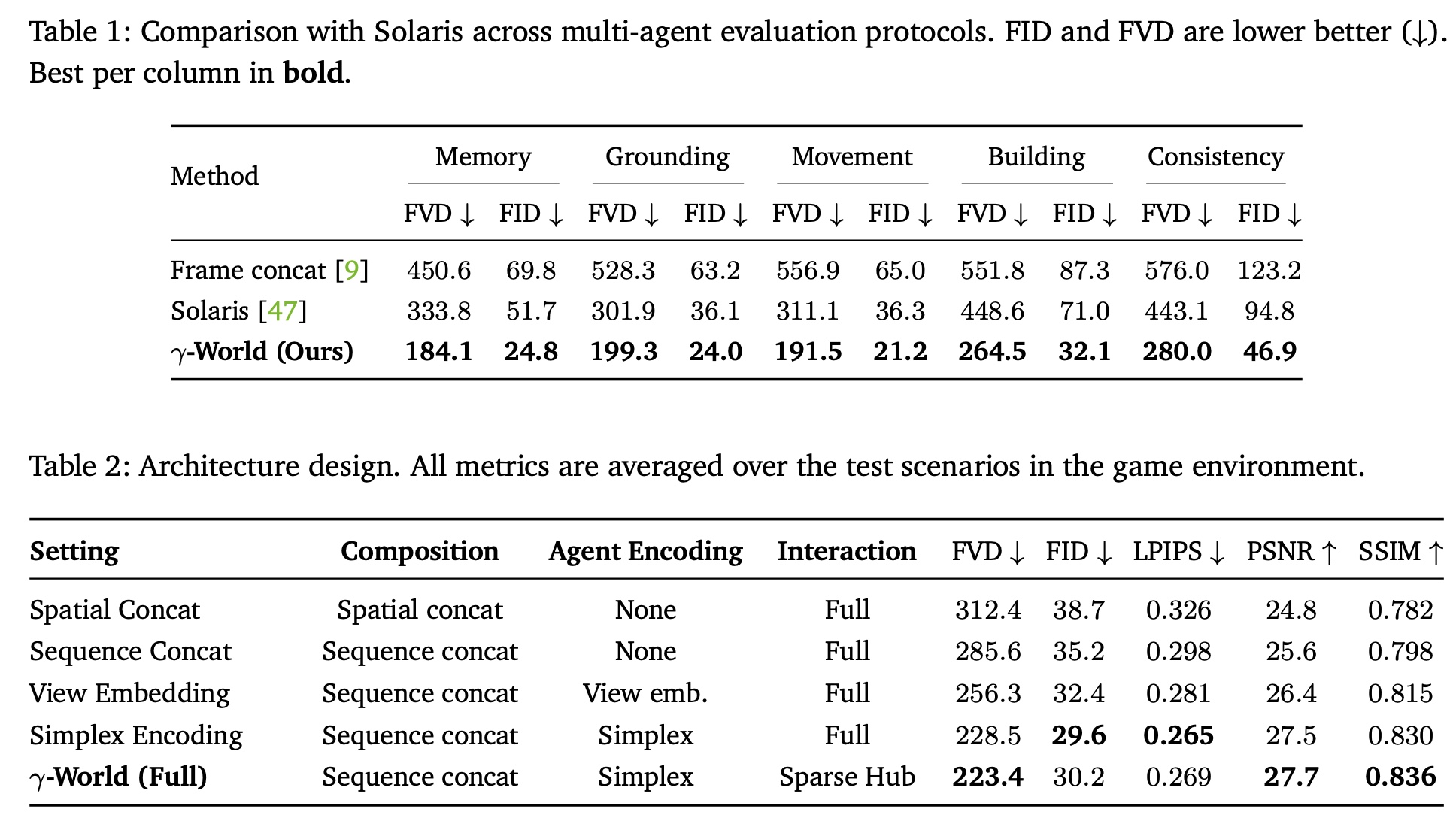
Training is on two-agent Minecraft trajectories, and the generation-quality numbers are all two-player. Against the concurrent Solaris (a multiplayer-Minecraft world model that uses dense joint attention and learned per-player IDs) and a frame-concatenation baseline, γ-World achieves significantly lower FID and FVD scores in tasks requiring memory, grounding, movement, building, and cross-view consistency. On Memory it cuts FVD from Solaris’s 333.8 to 184.1 and FID from 51.7 to 24.8; on Consistency, the hardest protocol, FVD drops from 443.1 to 280.0.
The ablation studies indicate that each of the paper’s major design decisions contributes to performance. Treating agents as separate streams is more effective than spatially concatenating their observations, Simplex Rotary Agent Encoding consistently outperforms learned view embeddings, and Sparse Hub Attention preserves quality while providing a scalable communication mechanism between agents. Together, these components produce the strongest overall results, supporting the authors’ central claim that agents should be modeled as distinct but exchangeable entities connected through a shared interaction state.
Four-player generation is shown only qualitatively, zero-shot, with no metrics.
Conclusions
This idea loosely echoes recent work such as DroPE, in the sense that both papers treat rotary embeddings as an architectural degree of freedom rather than a fixed implementation detail. However, the motivation is almost opposite: DroPE removes positional embeddings to improve length extrapolation in LLMs, while γ-World reallocates rotary dimensions to introduce a permutation-symmetric agent axis for multi-agent world modeling.
γ-World belongs to the emerging family of interactive video world models, alongside systems such as Oasis/Genie-style single-agent worlds, Matrix-Game-style real-time long-horizon models, MultiWorld-style multi-agent multi-view models, and ActionParty-style action-binding models. Compared with these, γ-World’s strongest distinguishing idea is not just “better video generation”, but a principled treatment of agent exchangeability: the model should not depend on Player 1/Player 2 ordering, learned identity slots, or dense pairwise attention.
Its contribution is therefore architectural and conceptual. Matrix-Game 3.0 emphasizes high-resolution real-time generation and long-horizon memory; MultiWorld emphasizes multi-view consistency; ActionParty emphasizes subject-action binding. γ-World contributes a scalable, permutation-symmetric, independently controllable multi-agent generation. The paper is important because it pushes world models closer to actual shared environments rather than controllable video demos.
paperreview deeplearning computervision generativemodels videogeneration worldmodels diffusion attention transformer efficiency