Paper Review: Titans: Learning to Memorize at Test Time
Titans is a new neural architecture that combines attention mechanisms with a long-term memory module to efficiently handle large context windows. Attention captures short-term dependencies, while the neural memory stores historical context for long-term use. This design allows fast, parallel training and inference, scaling to over 2 million tokens with improved accuracy in tasks like language modeling, common-sense reasoning, genomics, and time series analysis. Titans outperform Transformers and modern linear recurrent models, especially in tasks requiring retrieval of specific information from large datasets.
Preliminaries
Transformers rely on the attention mechanism, which computes dependencies between tokens but has high memory and computational costs for long sequences. To address this, efficient attention methods like sparsification, softmax approximation, and linear (kernel-based) attention have been developed, reducing complexity and improving throughput. Linear attention models, which replace softmax with kernel functions, allow for recurrent formulations that support efficient inference. However, their additive memory structure can lead to overflow with long contexts.
To tackle this, two approaches have emerged: adding forget mechanisms, such as adaptive gates in models like GLA, LRU, Griffin, xLSTM, and Mamba2, and improving write operations, inspired by the Delta Rule, which removes past values before adding new ones. Recent models also focus on parallelizable training and incorporating forgetting gates to enhance memory management.
Learning to Memorize at Test Time
Long-term Memory
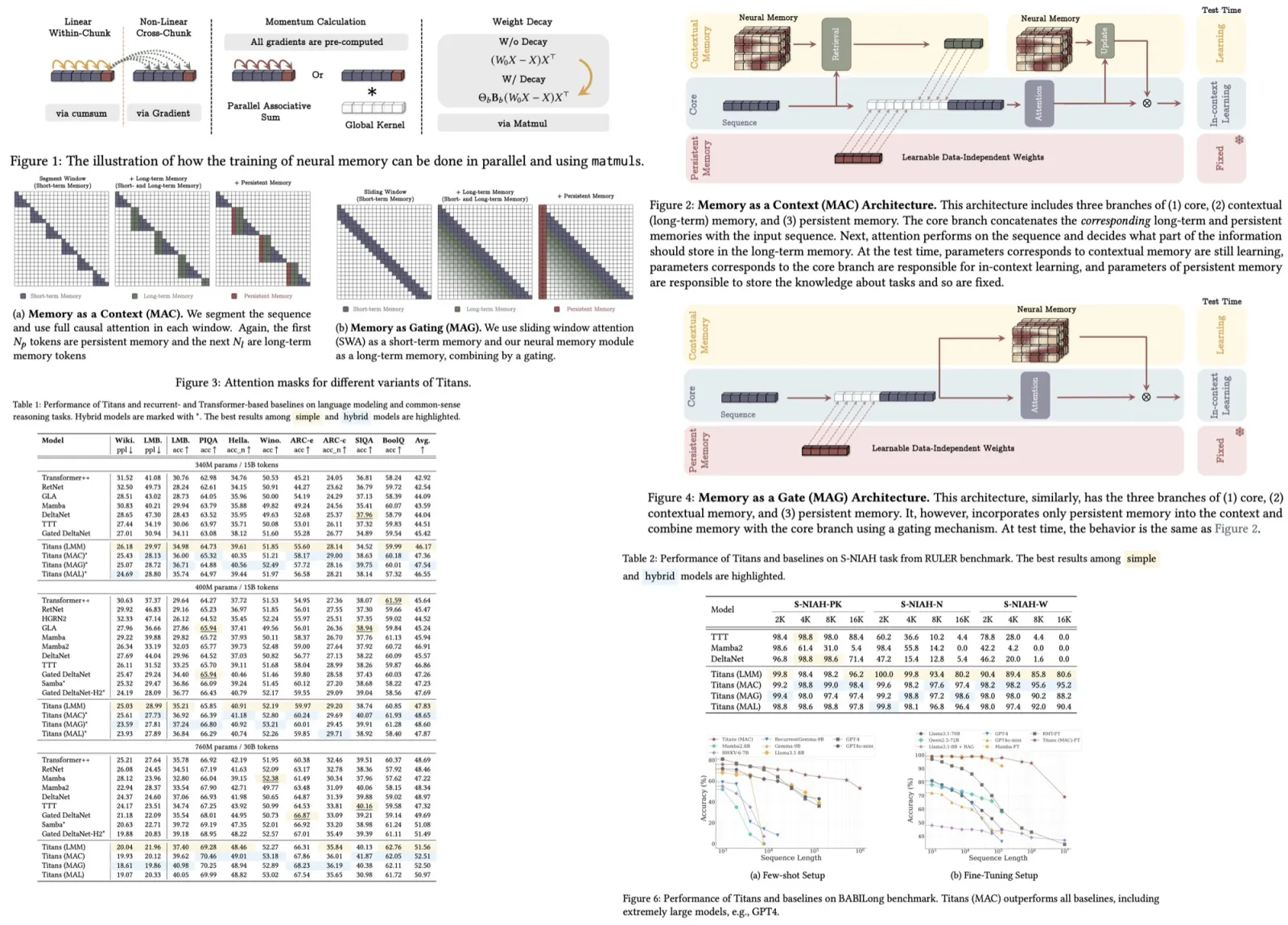
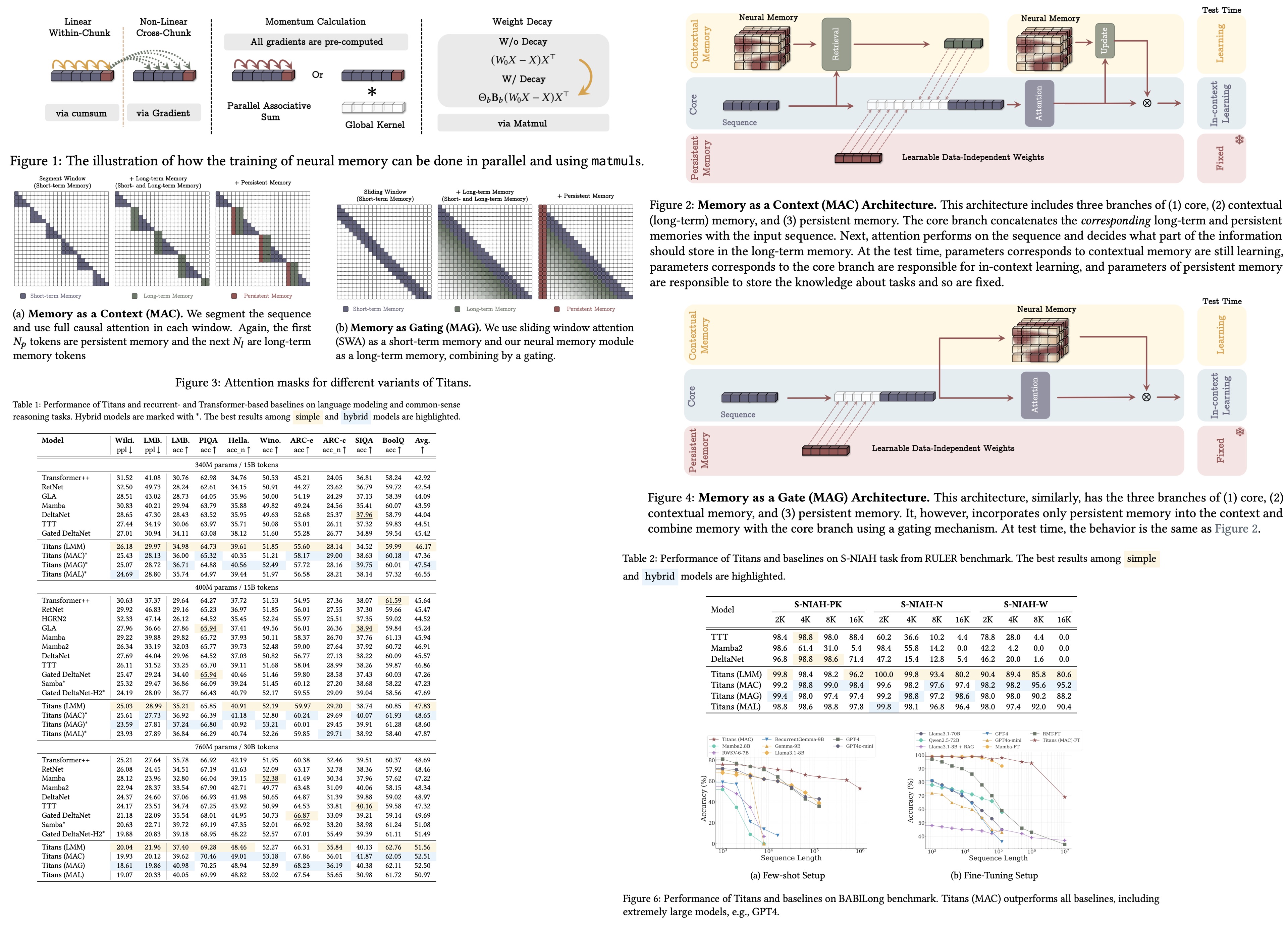
The authors discuss the design of a neural long-term memory module that can effectively memorize and forget information in a dynamic, data-dependent way. Unlike traditional models that risk overfitting by memorizing training data, this approach uses an online meta-learning framework to balance memorization and generalization at test time. The model updates its memory based on a surprise metric, which measures how different incoming data is from past data, incorporating both momentary surprise and past surprise (similar to gradient descent with momentum).
An adaptive forgetting mechanism, controlled by a gating parameter, manages memory capacity by deciding how much past information to retain or discard. The architecture uses MLP to capture non-linear relationships. Keys and values are generated from input data, and the memory learns associations between them using an online linear regression objective.
Information is retrieved via a forward pass using a query projection without updating memory weights.
How to Parallelize the Long-term Memory Training
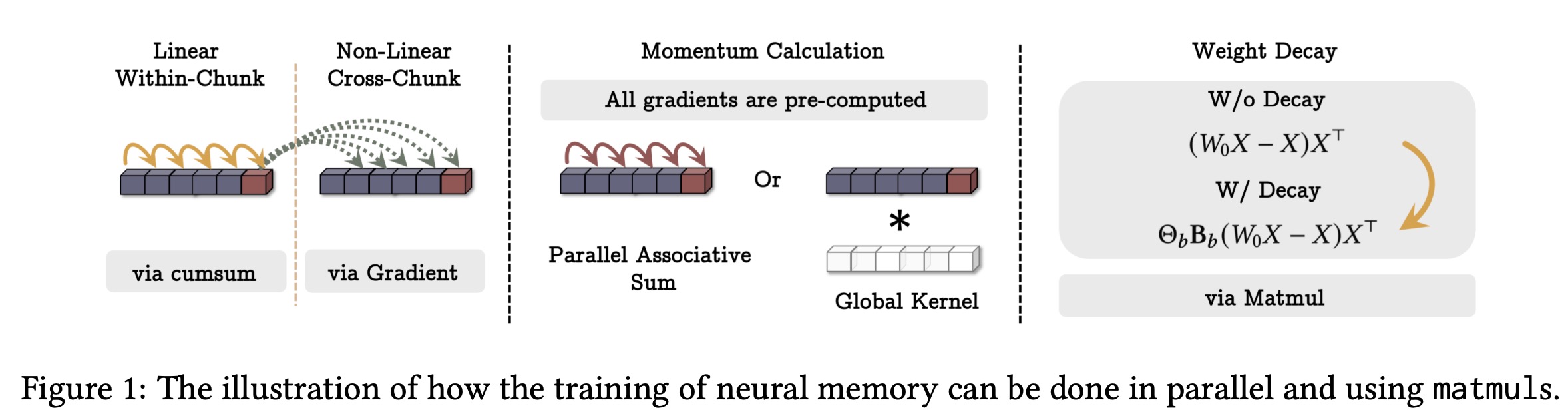
The long-term memory module is trained as a meta-model using gradient descent with momentum and weight decay. To optimize performance on hardware accelerators, the training process is parallelized by tensorizing operations and using matrix multiplications. The sequence is divided into chunks, and mini-batch gradient descent is applied within each chunk.
Parameters like learning rate, weight decay, and momentum decay can be made data-dependent or simplified to be constant within chunks, trading off some expressiveness for faster training. When parameters are time-invariant within chunks, the system behaves as a linear time-invariant system, which can be computed using global convolutions.
Persistent Memory
The long-term memory module functions as contextual memory, relying entirely on input data. To complement this, the authors use a set of learnable, input-independent parameters (persistent or meta-memory) to store task-specific knowledge. These parameters are appended to the beginning of the input sequence.
From a memory perspective, persistent memory stores abstractions of task knowledge, enabling better task mastery. From a feedforward network perspective, these parameters function like attention weights in Transformer feedforward layers, acting similarly to key-value pairs but independent of input. From a technical perspective, they help mitigate the bias of attention mechanisms toward initial tokens in sequences, redistributing attention weights more effectively to improve performance.
How to Incorporate Memory?
The authors suggest three ways of incorporating the memory into the transformer architecture.
Memory as a Context
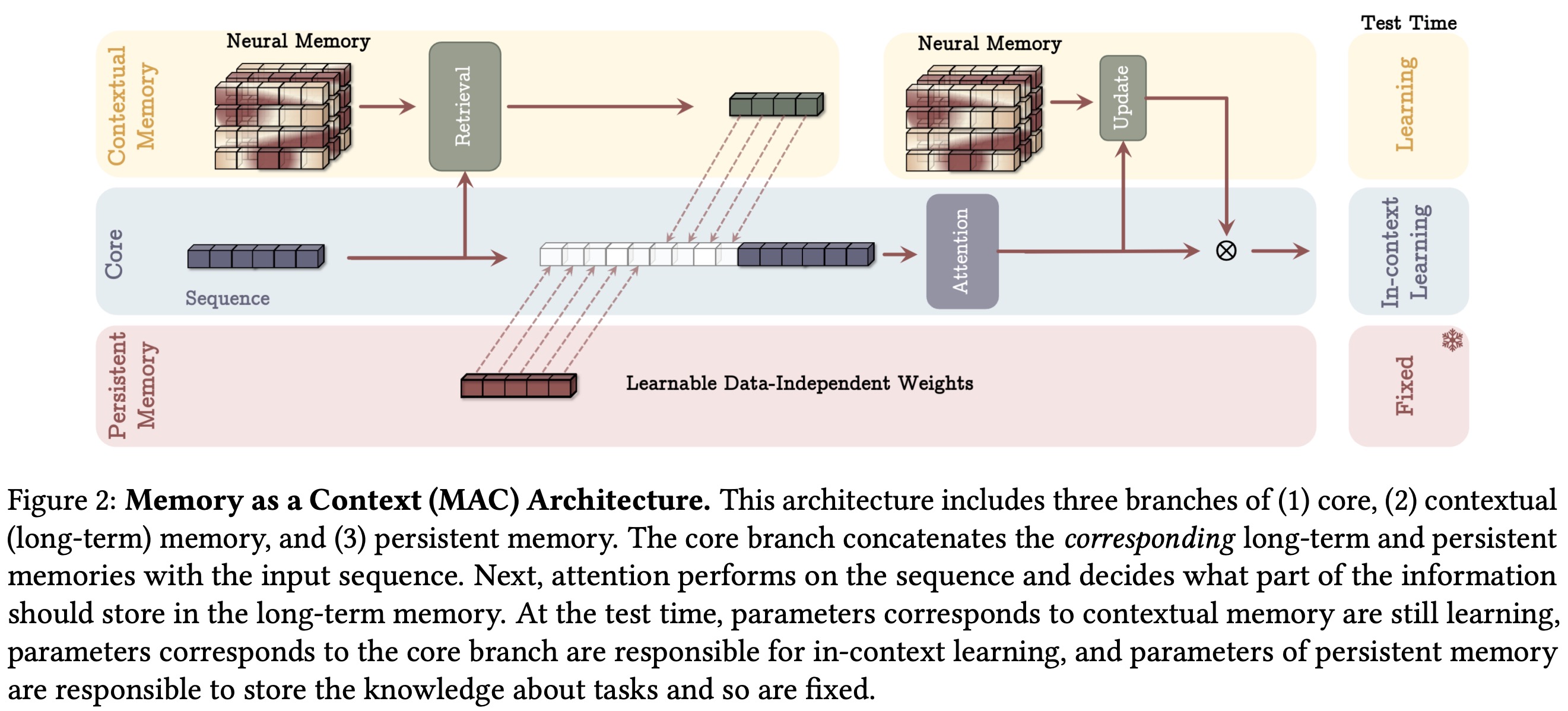
The first architecture processes long sequences by dividing them into fixed-size segments. For each incoming segment, the model retrieves relevant historical information from the long-term memory using the segment as a query. This retrieved information, combined with persistent memory parameters, is passed into the attention module.
The attention module outputs a refined representation that updates the model’s final output and updates the long-term memory. This design offers three advantages:
- The attention mechanism decides whether historical context is necessary.
- Attention helps identify and store only useful information, preventing memory overflow.
- Persistent memory remains fixed to retain task knowledge, attention weights adapt in-context, and the long-term memory continues learning during testing, updating its abstraction of past information.
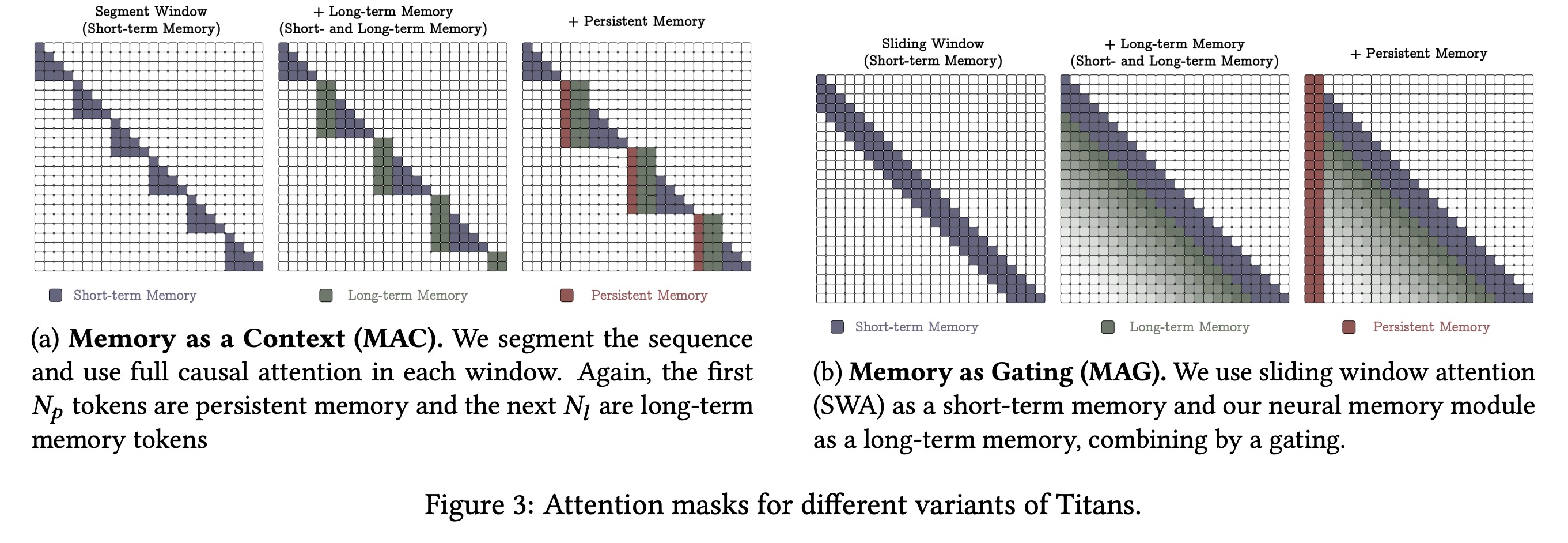
Gated Memory
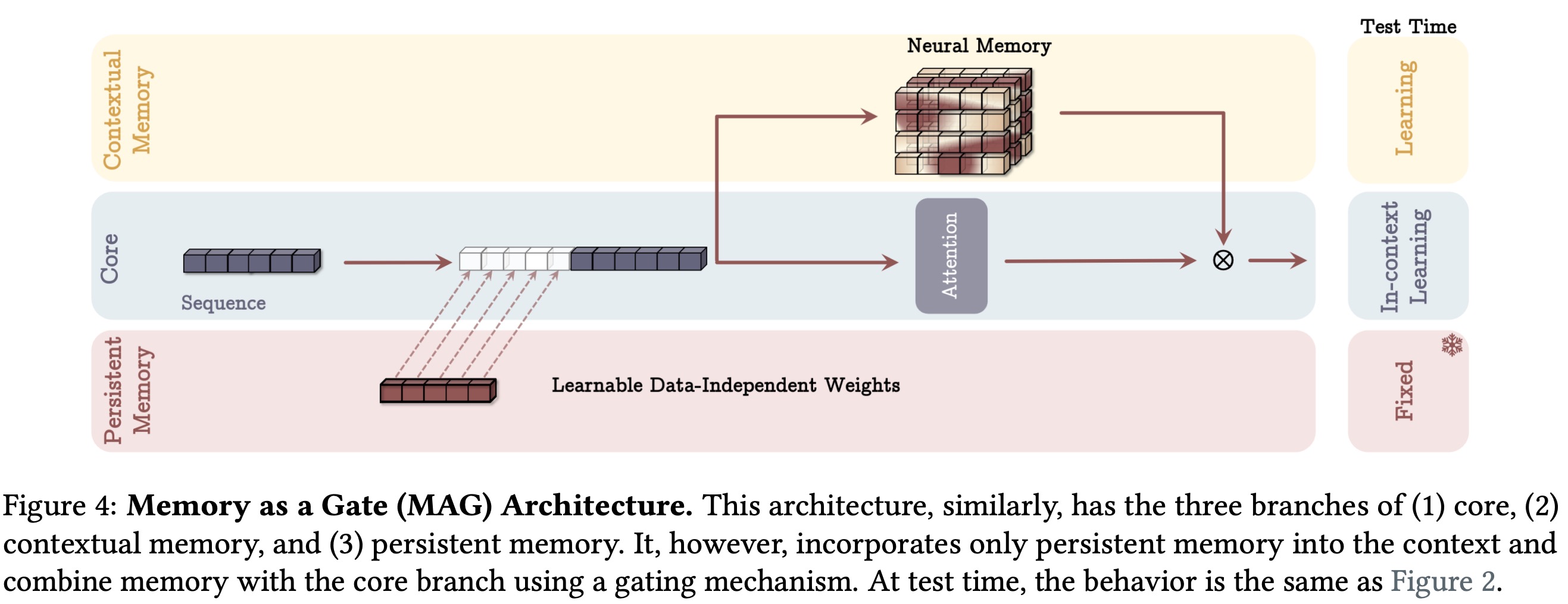
In this architecture, input data is processed through two parallel branches. One branch updates the long-term memory directly, while the other applies sliding window attention with persistent memory parameters as a prefix. Unlike the previous design, the input is not segmented.
The outputs from SWA and the long-term memory are combined using a non-linear gating mechanism. SWA functions as a precise short-term memory, while the neural memory module serves as a fading long-term memory. This setup can be seen as a multi-head architecture, with each branch acting as a distinct attention mechanism.
Memory as a Layer
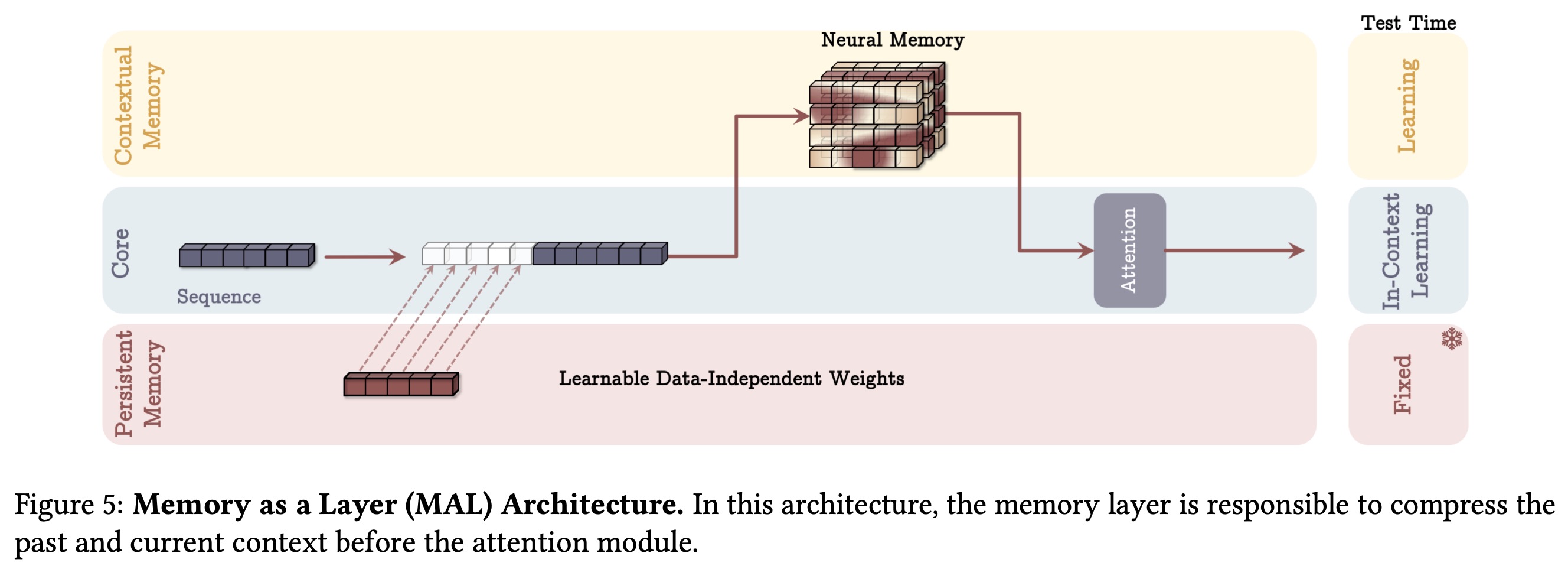
In this architecture, the neural memory module is used as a layer within a deep neural network. The input, combined with persistent memory parameters, is first processed by the neural memory module, and its output is then passed through SWA. This sequential setup is common but limits the model’s ability to leverage the complementary strengths of attention and memory modules simultaneously.
A simpler variant excludes attention altogether, relying solely on the long-term memory module (LMM) as the sequence model. This approach tests the independent effectiveness of the memory system without short-term memory components.
Architecture details
- All blocks have residual connections;
- Activation function is
SiLU; - 1D depthwise-separable CNN is used after each projection;
Experiments
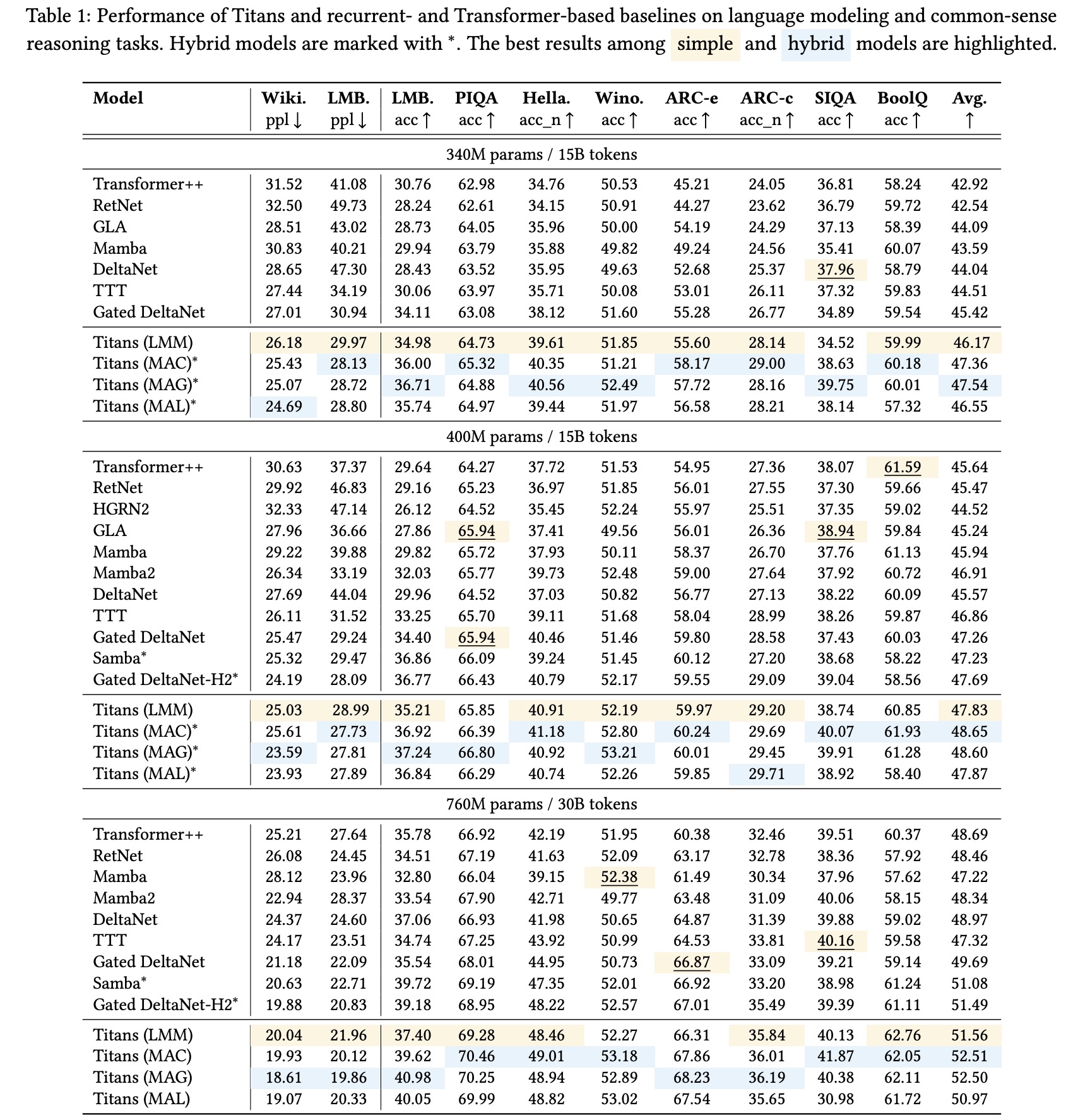
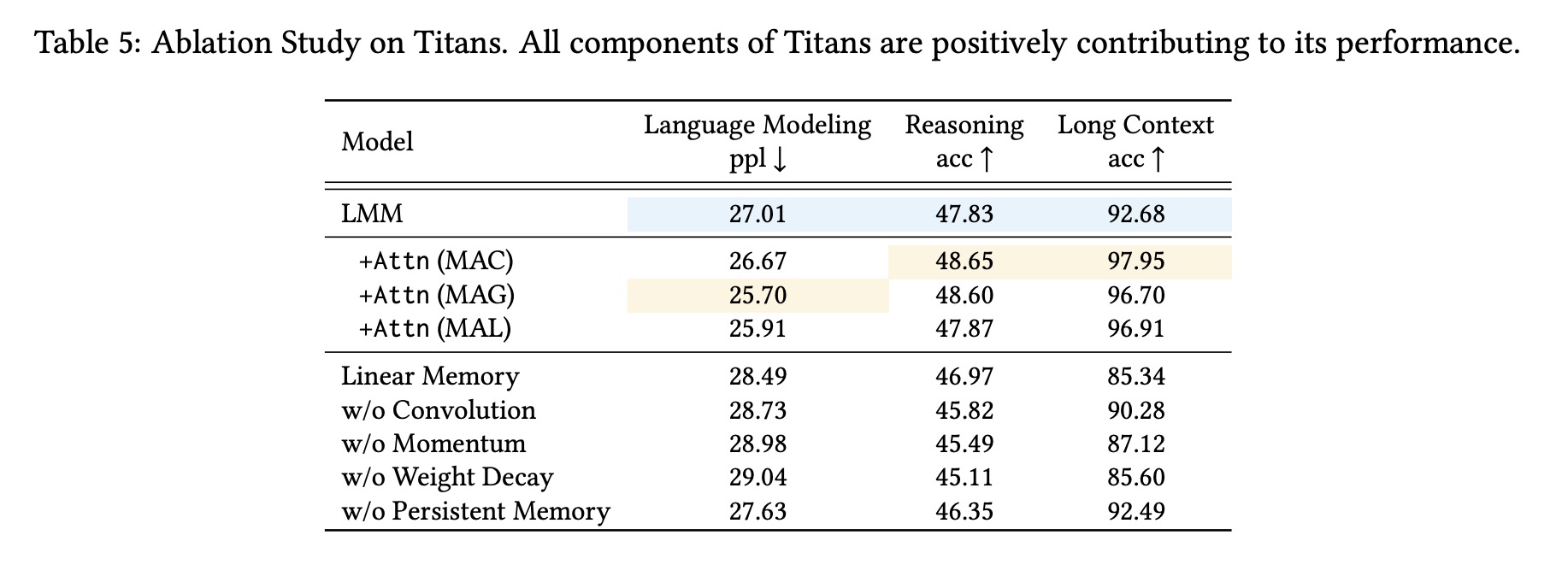
Titans’ neural memory module outperforms baseline models in both language modeling and commonsense reasoning tasks across model sizes (340M, 400M, 760M).
In the Needle-in-a-Haystack (NIAH) task, Titans outperform all baselines at sequence lengths of 2K, 4K, 8K, and 16K.