Paper Review: ReXNet: Diminishing Representational Bottleneck on Convolutional Neural Network’
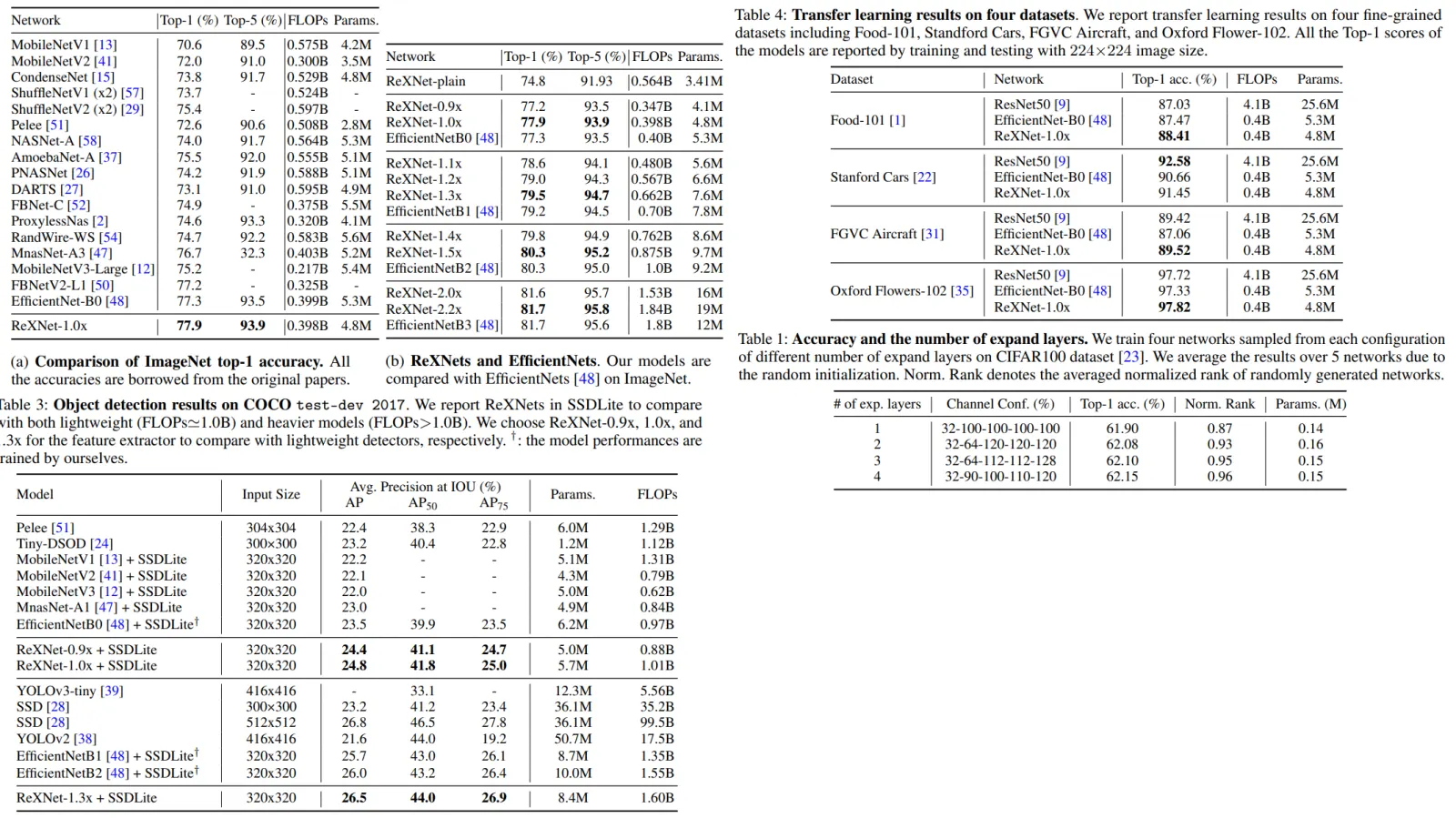
It was unexpected for me, but this paper is an improvement on MobileNet, not on ResNet. Authors think that commonly used architectures have a representation bottleneck and try to fix it by expanding channel size, using more expand layers, and better activation functions. This also improves the performance of models on ImageNet and good results on transfer learning on classification and object detection.
Authors hope that their design ideas could be used in NAS to create even better models.
Terminology:
Expand layer is a layer that has a higher dimension of output than of input. Condense layer is the opposite.
The main idea of the paper
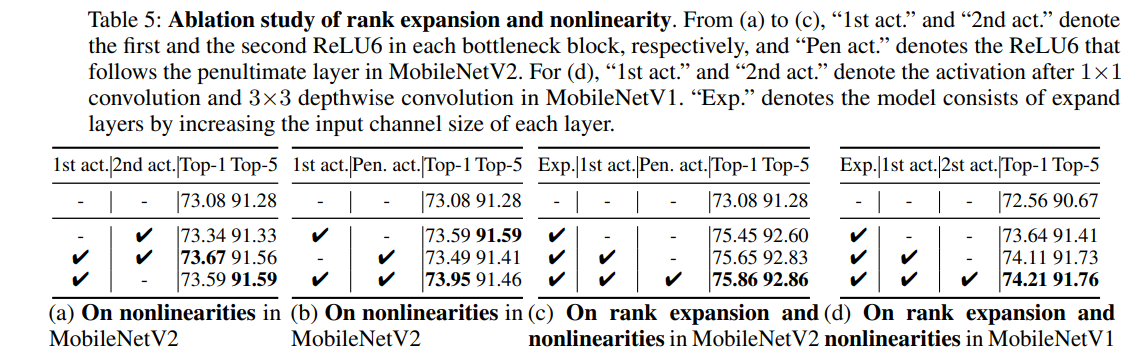
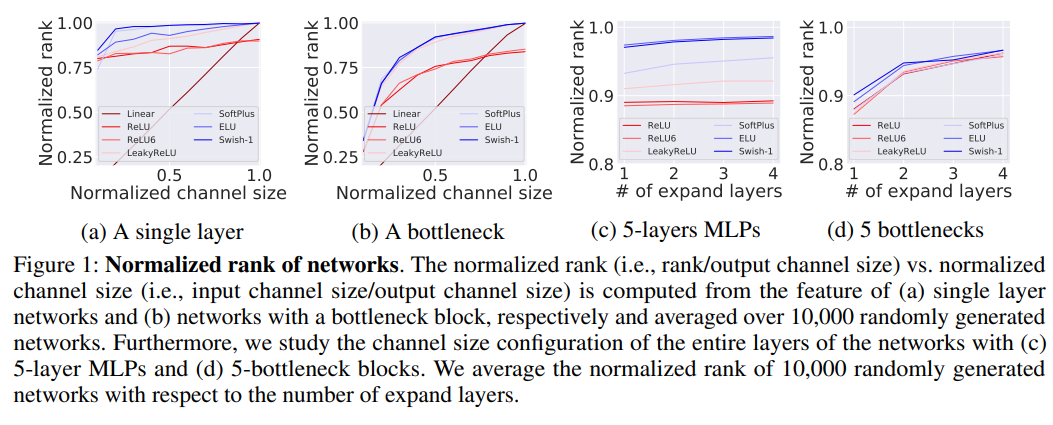
Common architectures used downsampling layers at the very beginning to decrease image size and increase channel size to compensate for it. Authors think that the rank of matrix in these layers isn’t high enough to make good representations of the data and decreases performance.
I don’t fully understand the math about matrix ranks and the authors’ conclusions, so I’ll skip it.
What really matters are their ideas of improvements:
- expand input channel size of convolutional layers and the penultimate layer (before classifier head)
- use swish as an activation function
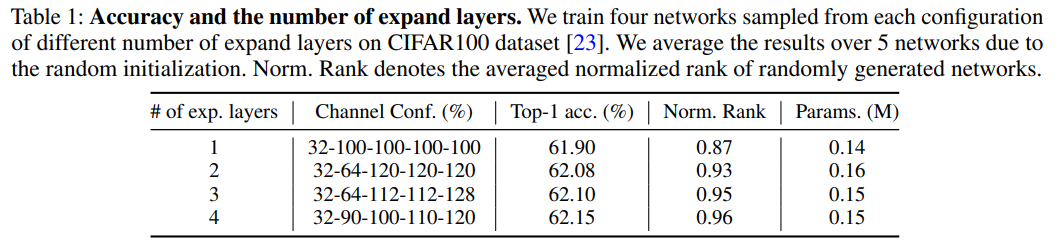
- use more expand layers
The base networks are MobileNetV1 and MobileNetV2. They also try to improve ResNet and VGG.
For a fair comparison, the authors try to keep the number of parameters and FLOPS nearly identical.
Training
224x224. Standard data augmentation with the random-crop rate from 0.08 to 1.0. SGD with momentum of 0.9 and mini-batch size of 512 with 4 GPUs. LR is initially set to 0.5 and is linearly warmed up in the first 5 epochs, then is decayed by the cosine learning rate scheduling. Weight decay is set to 1e-5.
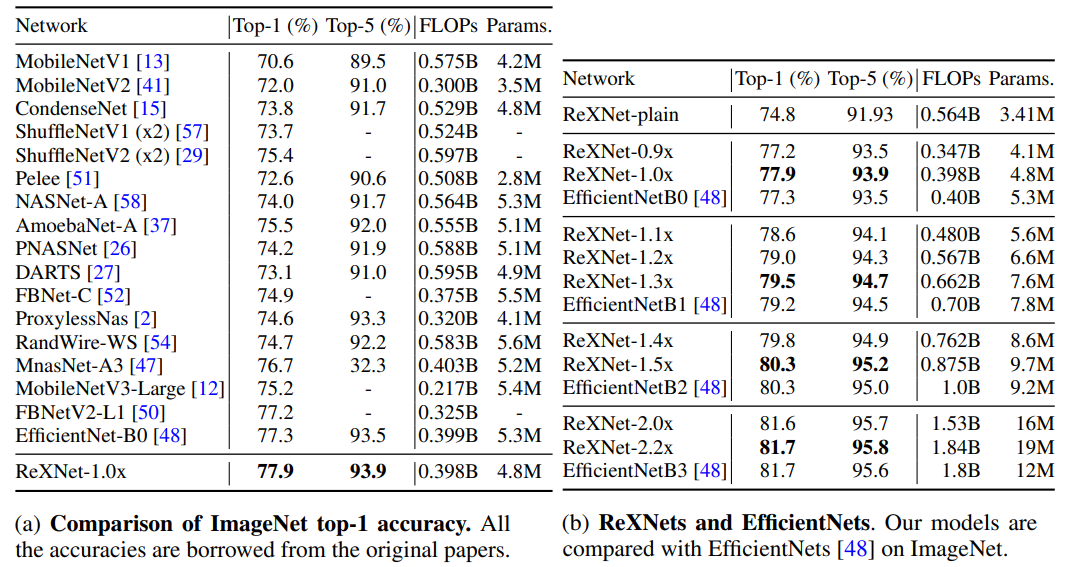
They train MobileNetV1 and MobileNetV2 with this setup and get 72.5% and 73.1% that outperform the reported scores of 70.6% and 72,0% respectively.
Quite interesting is that there is additional information in the appendix:
label smoothing with alpha 0.1, dropout 0.2 on the last layer, stochastic depth 0.2, randaug with the magnitude of 9, and random erasing with the probability of 0.2.
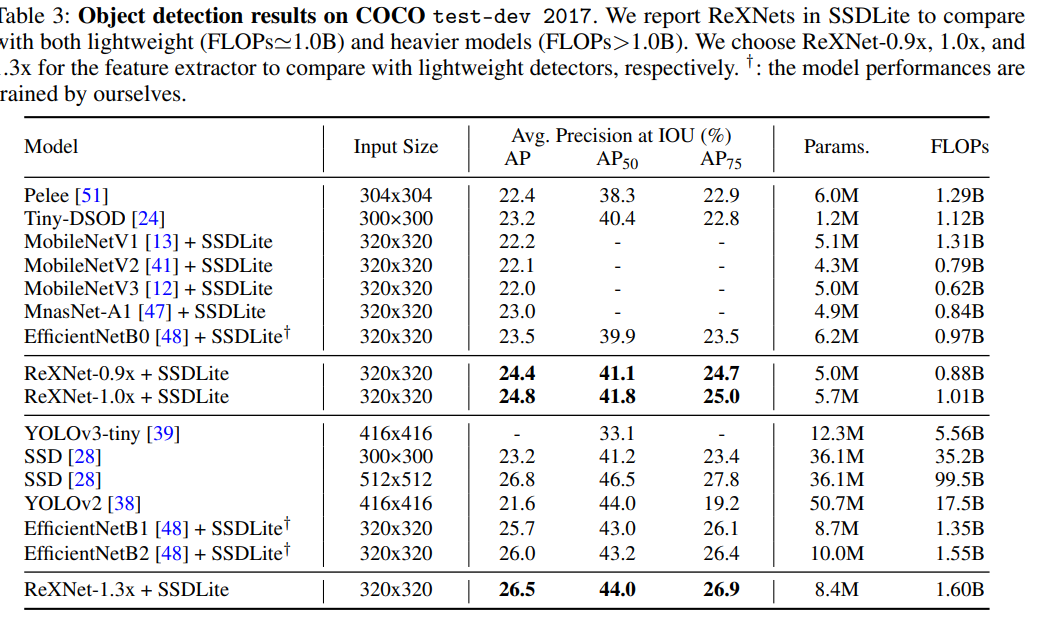
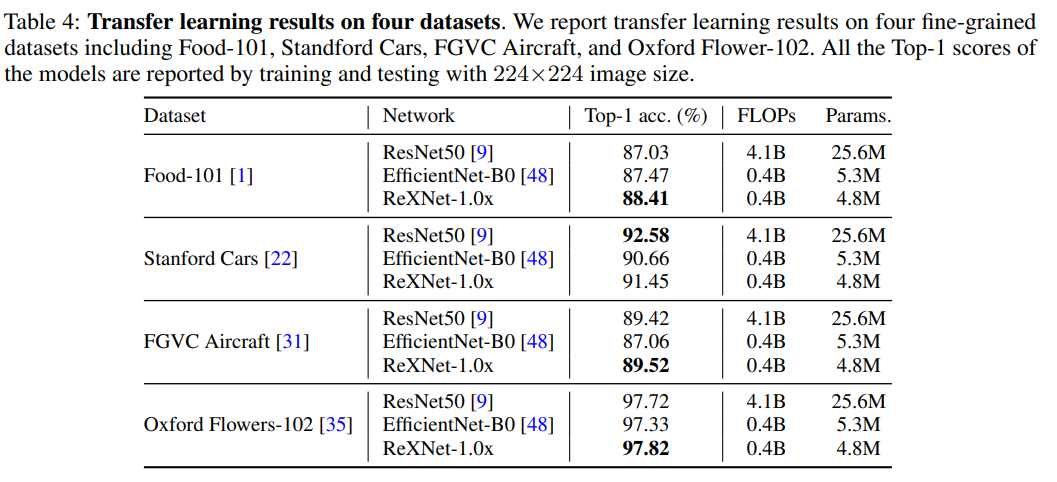
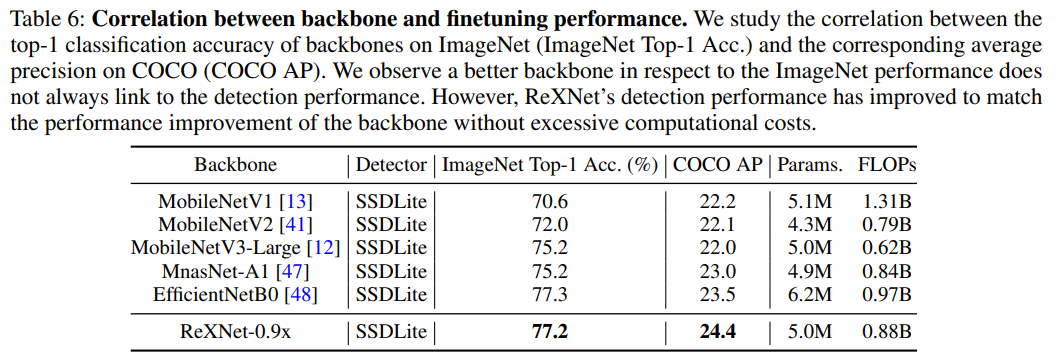
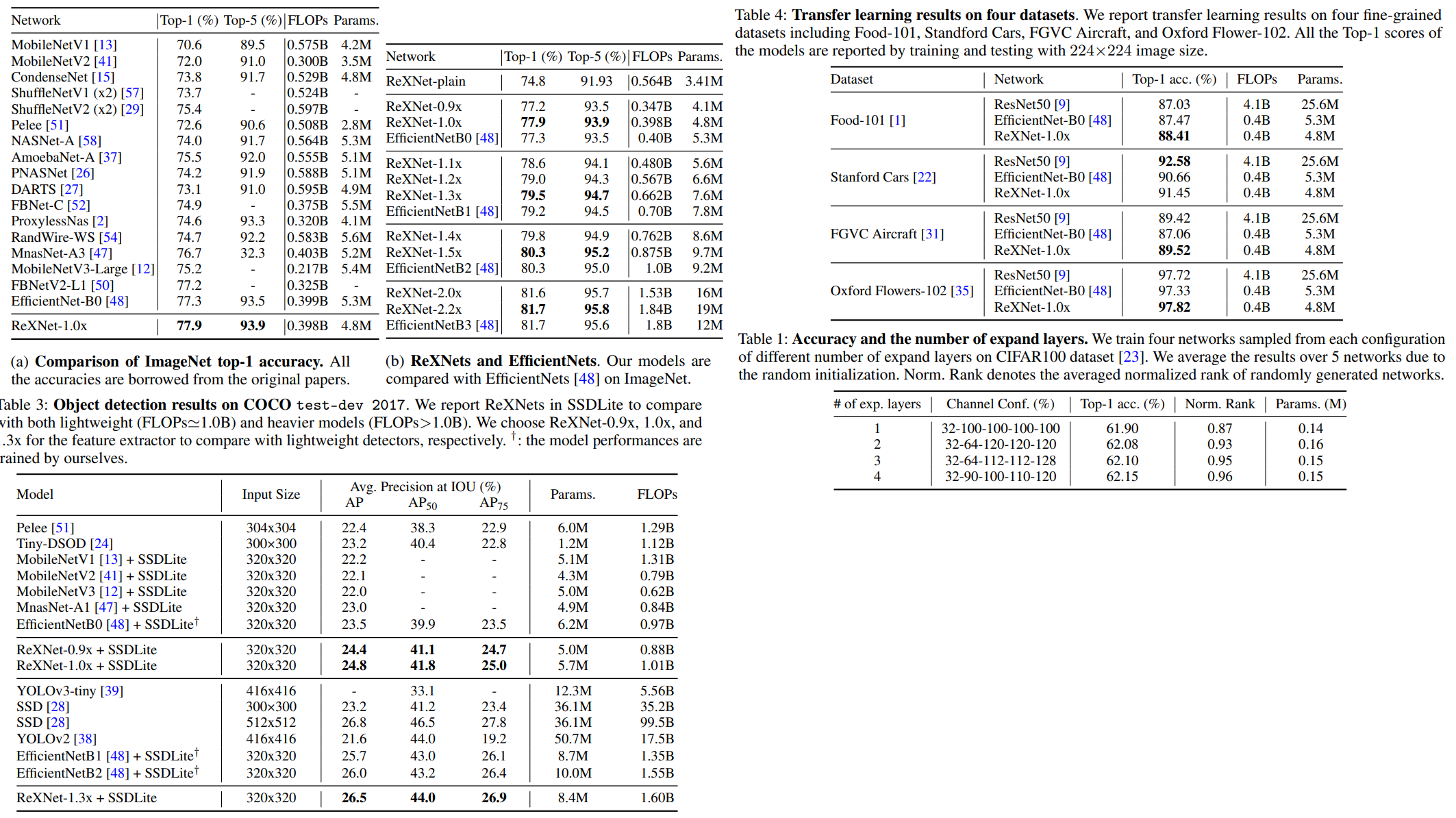
The results are quite good both on ImageNet and on transfer learning.