LocateAnything Explained: Parallel Box Decoding and how it makes visual grounding faster and more precise
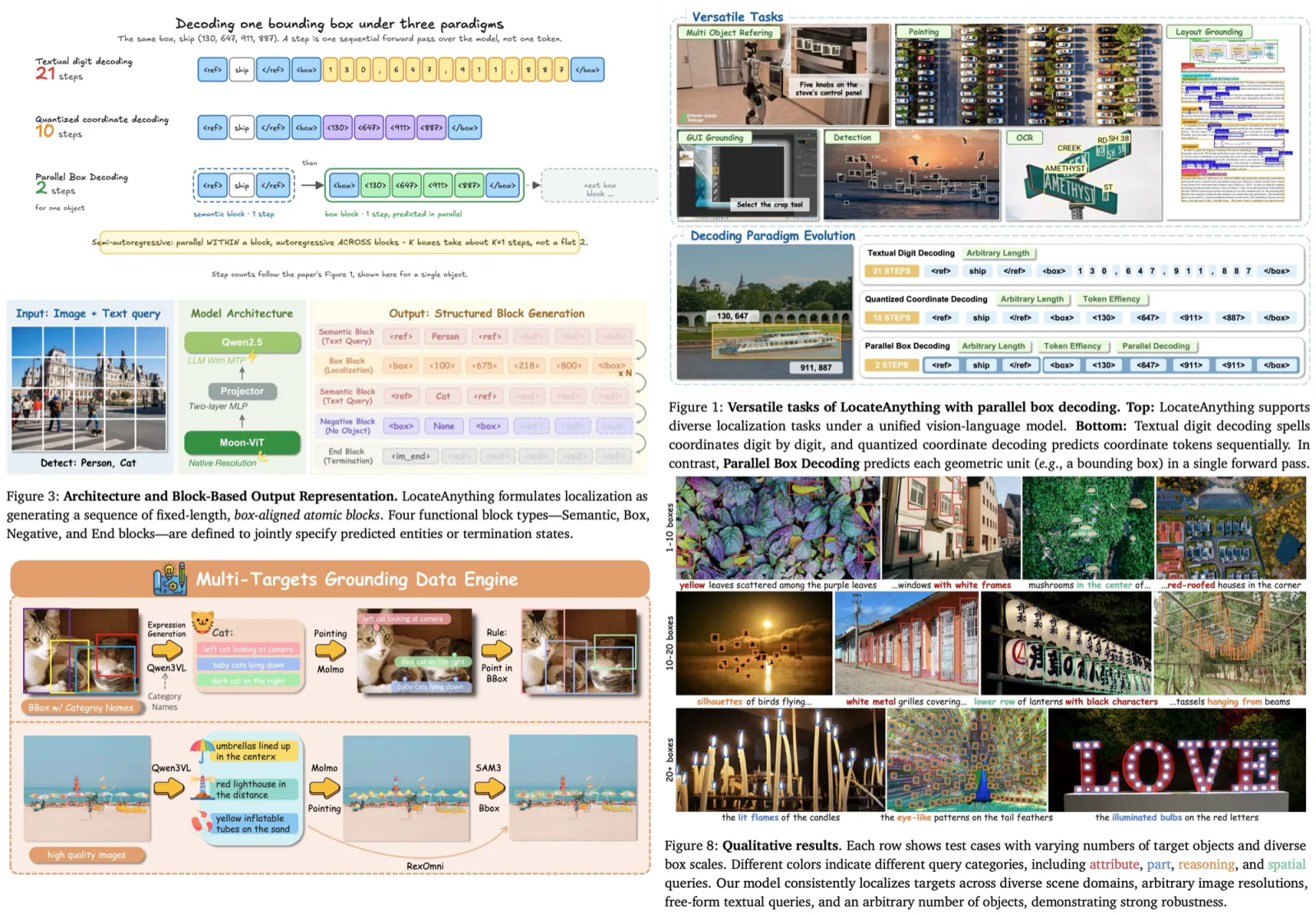
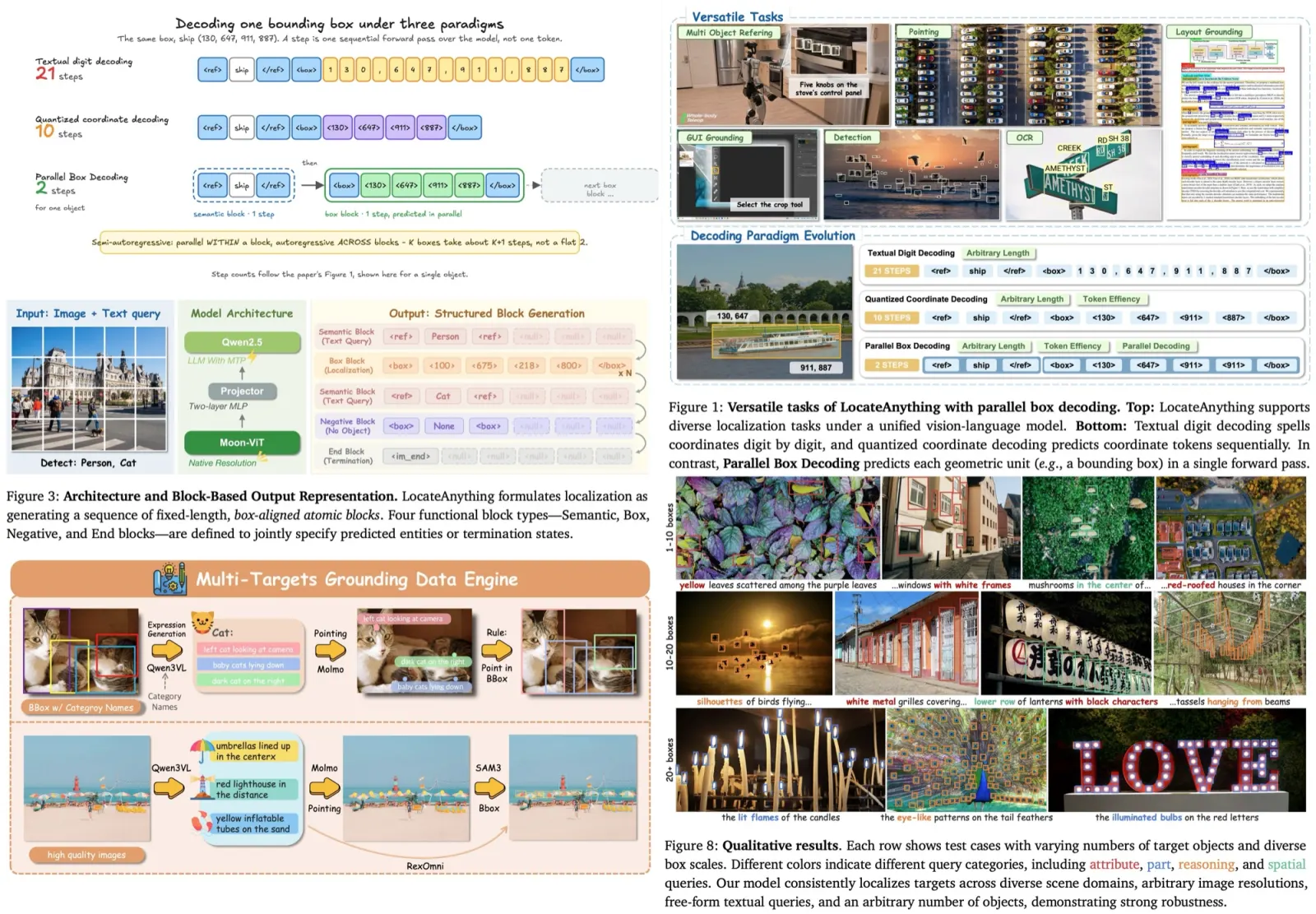
Modern detection-and-grounding VLMs treat a bounding box as text: each box becomes a short string of coordinate tokens, decoded one at a time, left to right. This means a model predicts box coordinates one token at a time, despite all coordinates belonging to the same geometric object. The approach inherits the limitations of language modeling rather than exploiting the structure of spatial prediction. The usual fix for the latency half is multi-token prediction (MTP): emit several tokens per step and accept some accuracy loss for throughput. LocateAnything introduces Parallel Box Decoding (PBD), which predicts an entire bounding box as a single atomic unit. This simultaneously improves localization quality and decoding speed.
The approach
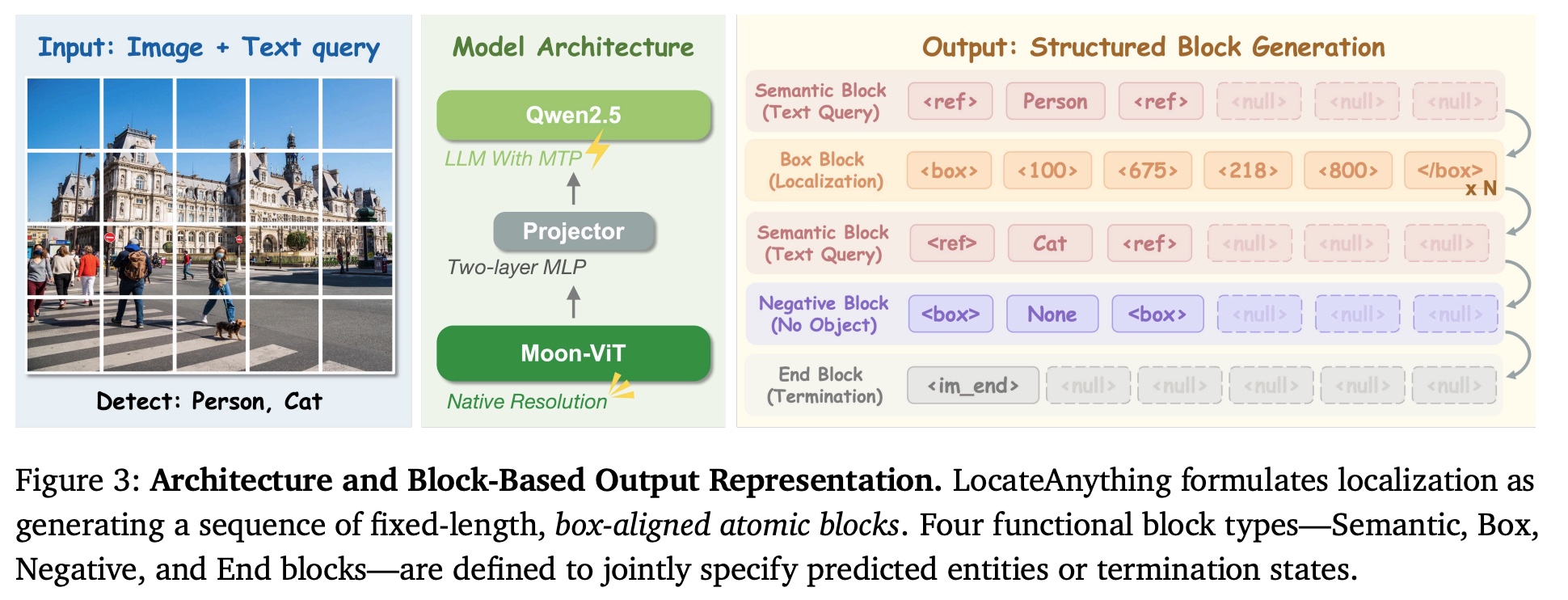
LocateAnything-3B is a native-resolution VLM built from a Moon-ViT vision encoder and a Qwen2.5 language decoder joined by a two-layer MLP projector. LocateAnything uses a block-based representation for bounding boxes. Coordinates are quantized and grouped into fixed-length blocks that become the fundamental prediction unit.
Parallel Box Decoding

The central idea is Parallel Box Decoding (PBD): reformulate localization output as a sequence of fixed-length, box-aligned blocks rather than a flat coordinate-token stream. Every block has the same length (six positions, four quantized coordinates in a 0-to-1000 grid plus two structural markers). There are four block types: a Semantic block carrying the queried label, a Box block carrying the coordinates, a Negative block when the object is absent, and an End block to stop.
Because a box now lives inside one constant-length block, the decoder can output that whole block in a single step. Within a block, the four coordinate positions attend to each other bidirectionally, so the top edge is predicted with knowledge of the left edge rather than being blind to it; across blocks, attention is block-causal. That makes the scheme semi-autoregressive rather than fully parallel: the tokens inside a block are predicted together, but blocks are still emitted one after another, so a busy image costs roughly one step per box rather than a flat two.
Dual NTP and MTP training
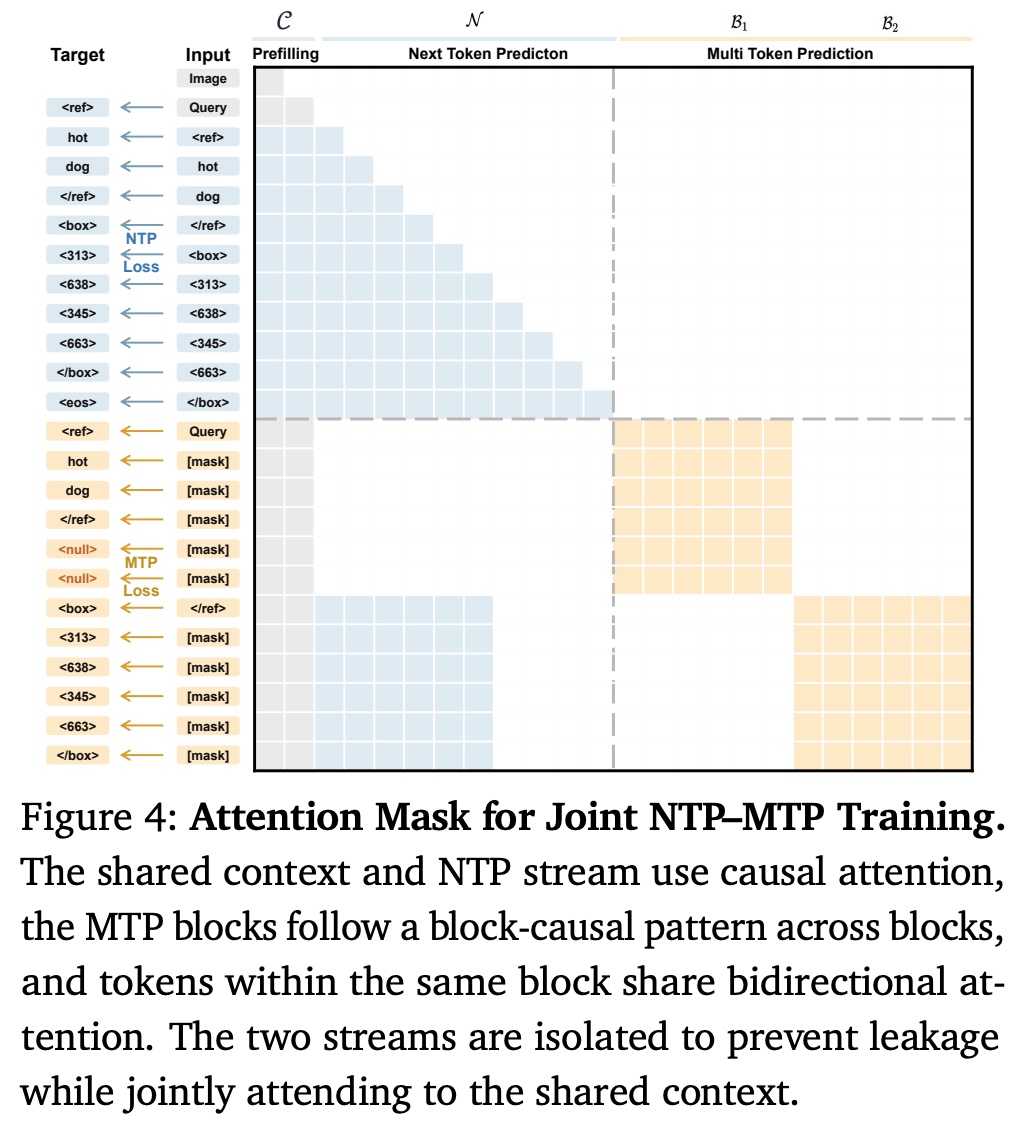
Training only with parallel box prediction would risk losing the causal reasoning behavior inherited from autoregressive language models. LocateAnything therefore trains on two representations of the same target simultaneously: a standard next-token prediction (NTP) sequence and a block-level masked-token prediction (MTP) sequence. The NTP stream preserves the model’s original language modeling capabilities, while the MTP stream teaches it to predict an entire box block in a single step. If the block size is reduced to one token, the formulation naturally becomes standard NTP.
To make this work, the authors introduce a block-causal attention mask. The NTP stream uses standard causal attention and cannot access the MTP stream. The MTP stream can attend to previously generated blocks but not future ones, while tokens within the same block use bidirectional attention. This allows the model to jointly reason about all coordinates of a bounding box while maintaining dependencies between different box predictions.
The final objective combines the losses from both streams, enabling the model to retain autoregressive reasoning while learning the structured predictions required for Parallel Box Decoding.
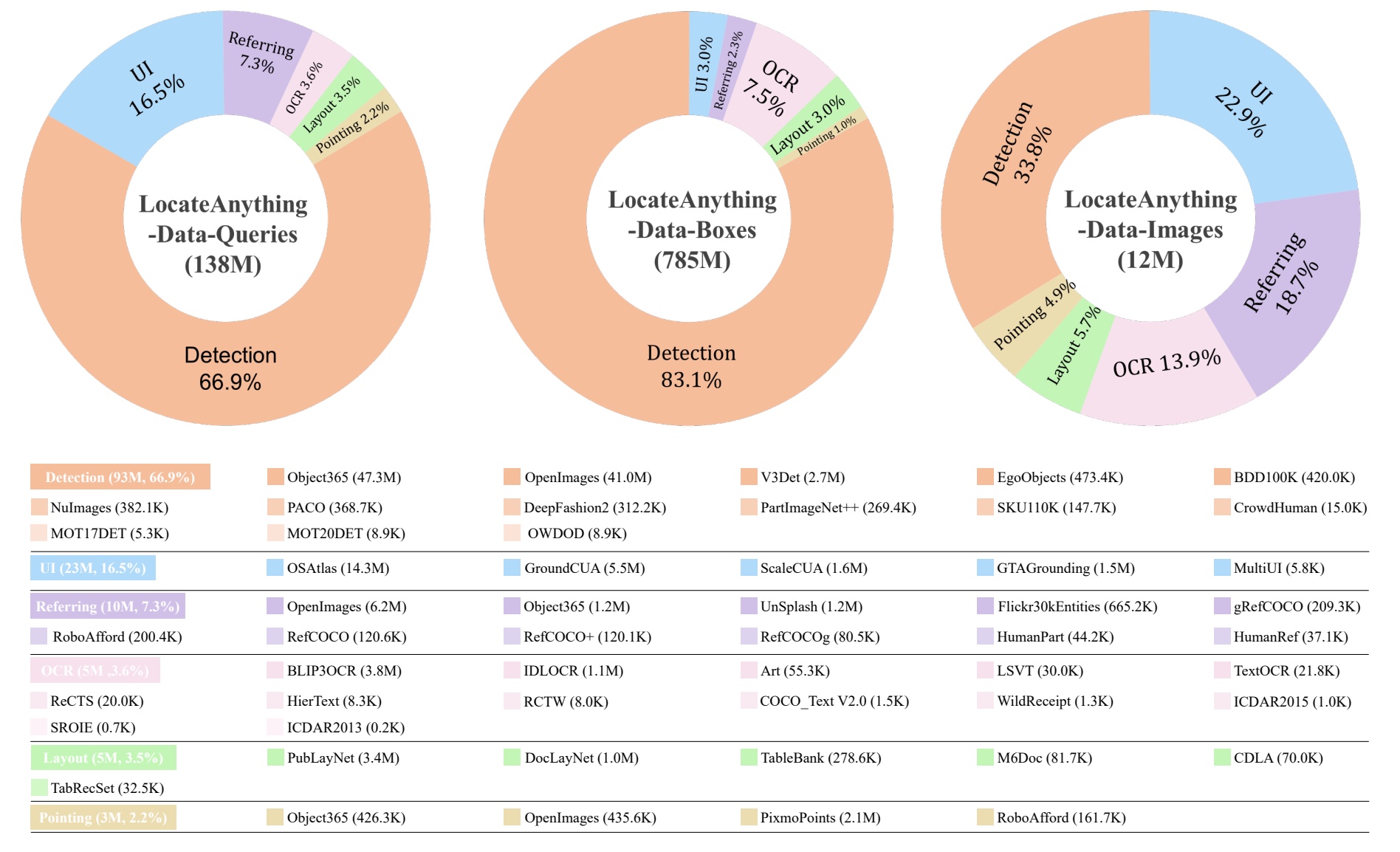
The authors use a large data engine, LocateAnything-Data: 12M images, 138M natural-language queries, and 785M boxes across six task families. General object detection dominates the supervision (about two-thirds of queries and over 80% of boxes), with GUI grounding, referring comprehension, OCR, layout grounding, and point localization filling out the rest. Training runs a world-knowledge alignment pass with detection data held out, then two SFT stages: the first mixes in the full query set, the second cuts general data to a fifth and over-samples dense-scene datasets like MOT20Det and SKU110K to sharpen crowded detection.
Three inference modes and the hybrid fallback

Parallel Box Decoding is fast, but the authors identify two situations where it can fail. The first is format irregularity: in complex scenes with many object categories, the model can become confused when transitioning between categories and generate malformed box syntax. The second is spatial ambiguity: when objects are densely packed in regular patterns, parallel decoding can predict coordinates that fall between two neighboring objects rather than on either object itself.
To address this, LocateAnything introduces a hybrid inference strategy that combines the speed of MTP with the reliability of traditional autoregressive decoding. During generation, the model continuously checks for malformed outputs and low-confidence coordinate predictions. When a problematic block is detected, generation rolls back to the last valid prefix and temporarily switches to standard next-token prediction (NTP) for that block. Once the difficult region has been resolved, decoding returns to the faster MTP mode.
This leads to three inference modes. Slow Mode uses pure autoregressive decoding. Fast Mode uses Parallel Box Decoding throughout. Hybrid Mode combines both approaches, using MTP by default and falling back to NTP only when necessary.
Conceptually, Hybrid Mode resembles speculative decoding and other modern acceleration techniques. Most predictions are generated using a fast approximate procedure, while a slower but more reliable mechanism is invoked only for difficult cases. This allows LocateAnything to retain most of the throughput benefits of parallel decoding while avoiding its most common failure modes.
Experiments

On standard object detection benchmarks, LocateAnything consistently outperforms similarly-sized grounding VLMs such as Rex-Omni. More interestingly, the gains persist in dense detection scenarios such as VisDrone and Dense200, suggesting that the model learns robust spatial representations rather than simply memorizing common object layouts. The authors also report strong results on a diverse set of localization tasks, including UI grounding, document layout understanding, and referring expression comprehension, where LocateAnything reaches or exceeds the performance of larger general-purpose VLMs and several specialized systems.
Under the default Hybrid Mode, LocateAnything achieves roughly 12.7 boxes per second, compared to 5.0 for Rex-Omni and 1.1 for Qwen3-VL. The advantage becomes even larger in dense scenes, where the number of predicted boxes grows and autoregressive coordinate generation becomes increasingly expensive.
Ablations
The ablation studies reinforce the paper’s main argument: the gains come from the output representation rather than from scaling the backbone.
- First, replacing coordinate-token generation with box-aligned outputs improves localization quality even in pure autoregressive decoding. This suggests that representing a bounding box as a structured object provides a better learning signal than serializing it into a sequence of coordinate tokens.
- Second, the authors compare Parallel Box Decoding against generic multi-token prediction approaches such as SDLM and Block Diffusion. These methods treat blocks as arbitrary token groups, while LocateAnything aligns blocks with meaningful geometric units. The aligned formulation proves both faster and more accurate, supporting the paper’s broader thesis that output structure matters.
- Finally, the Hybrid Mode successfully balances speed and accuracy. Pure MTP decoding delivers the highest throughput but suffers occasional quality degradation in difficult scenes. The NTP fallback mechanism recovers most of this lost accuracy while retaining the majority of the speedup.
Conclusions
The “predict all the boxes at once” approach is not new; it is the idea behind the DETR and DINO: represent detection as a set prediction problem rather than generating coordinates token-by-token. Those models remain among the strongest closed-set detectors, but they achieve this through specialized detection architectures with fixed label spaces. They are not open-vocabulary systems, instruction-following models, or general-purpose VLMs.
LocateAnything’s bet is to bring some of that set-prediction intuition into a generative VLM. Instead of treating a bounding box as a sequence of coordinate tokens, it treats the entire box as a structured prediction unit and decodes it in parallel. The result is somewhere between DETR-style detectors and coordinate-token VLMs such as Qwen-VL and Rex-Omni.
In hindsight, coordinate-token grounding always felt like a compromise. DETR showed years ago that boxes are naturally set-valued geometric objects, yet many VLMs reverted to serializing them into text because language models only knew how to generate sequences. LocateAnything revisits that earlier intuition and asks what happens if we bring structured box prediction back into the VLM era.
What I like here is that the speed argument and the accuracy argument come from the same design choice rather than being traded against each other. Parallel decoding is normally a latency optimization that is a trade-off for quality; reframing the parallel unit as a coupled box makes it more precise, and the IoU=0.95 jump on LVIS is concrete proof. On the other hand, the advantage disappears at IoU=0.5 and the model still trails specialized detectors on COCO, and the hybrid fallback shows that pure parallelism is not yet enough in dense or multi-class scenes.
paperreview deeplearning computervision objectdetection multimodal vlm efficiency