Paper Review: M1: Towards Scalable Test-Time Compute with Mamba Reasoning Models
M1 is a hybrid linear RNN reasoning model based on the Mamba architecture, designed for efficient inference. It uses distillation from existing reasoning models and is enhanced with reinforcement learning. M1 achieves strong performance on AIME and MATH benchmarks, matching Deepseek R1 models at a similar scale. It delivers over 3x faster generation compared to same-size transformers using vLLM and achieves higher accuracy under fixed generation time through self-consistency voting.
The approach

Stage 1: Distillation. M1 is created by distilling a pretrained transformer into a Mamba-based model using a modified version of the MAMBAINLLAMA approach. Key transformer weights are mapped to Mamba components and new Mamba-specific parameters are added (sampling rate and dynamic parameter). Additional linear layers are added to adapt GQA-based transformers. The attention layers are replaced with Mamba layers in one step, and the entire model is fine-tuned. Distillation uses reverse KL divergence for better mode-seeking alignment between student and teacher models.
Stage 2: SFT. After distillation, the model is fine-tuned on the OpenMathInstruct-2 dataset. It is then further trained on an 8B-token mixed dataset of math problems and model-generated solutions from various sources, including OpenR1, OpenThoughts, ServiceNow-AI, and MagpieReasoning.
Stage 3: Reasoning RL. To further improve performance, Mamba is trained using reinforcement learning with the GRPO. Unlike previous work, the KL penalty is removed to improve stability, and an entropy bonus is added to encourage diverse outputs. Each prompt ends with “Let’s think step by step and output the final answer within \boxed{}”.
Experiments
Llama3.2-3B-Instruct is used as distillation target model.
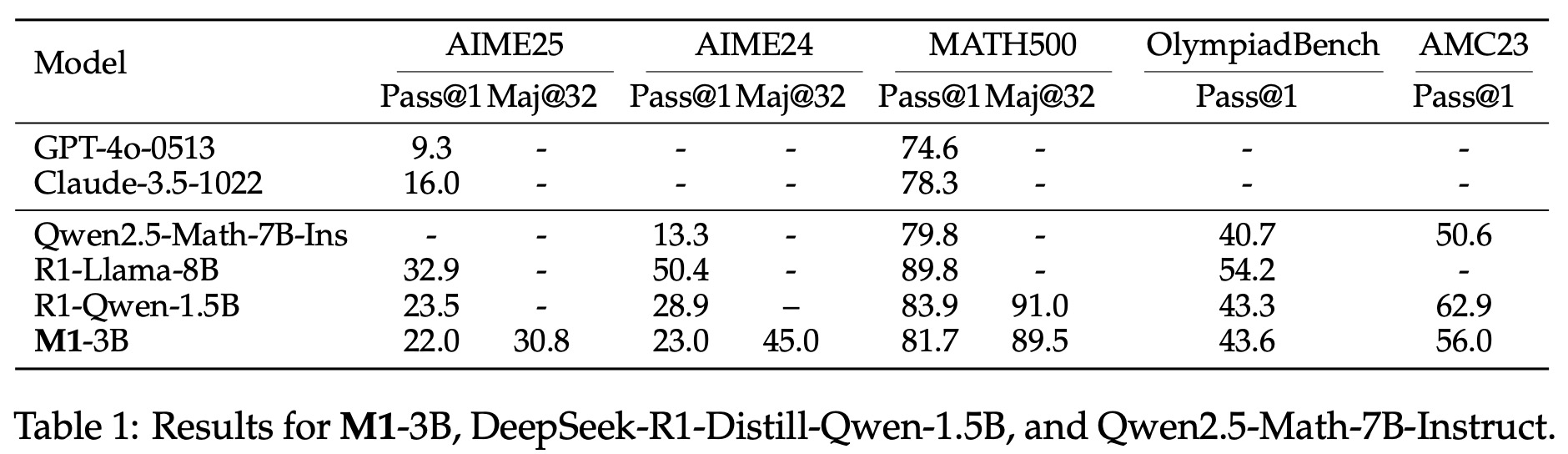
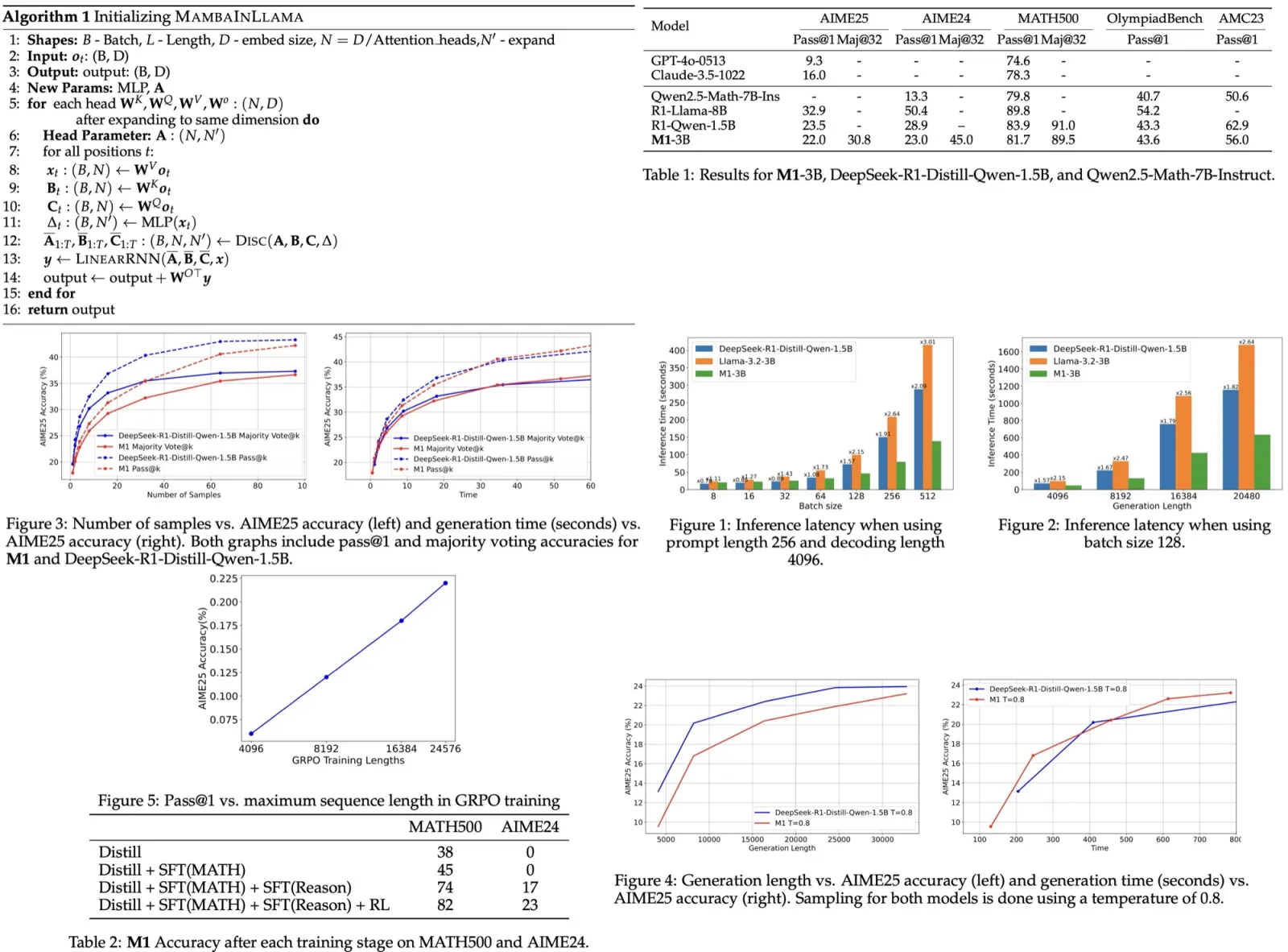
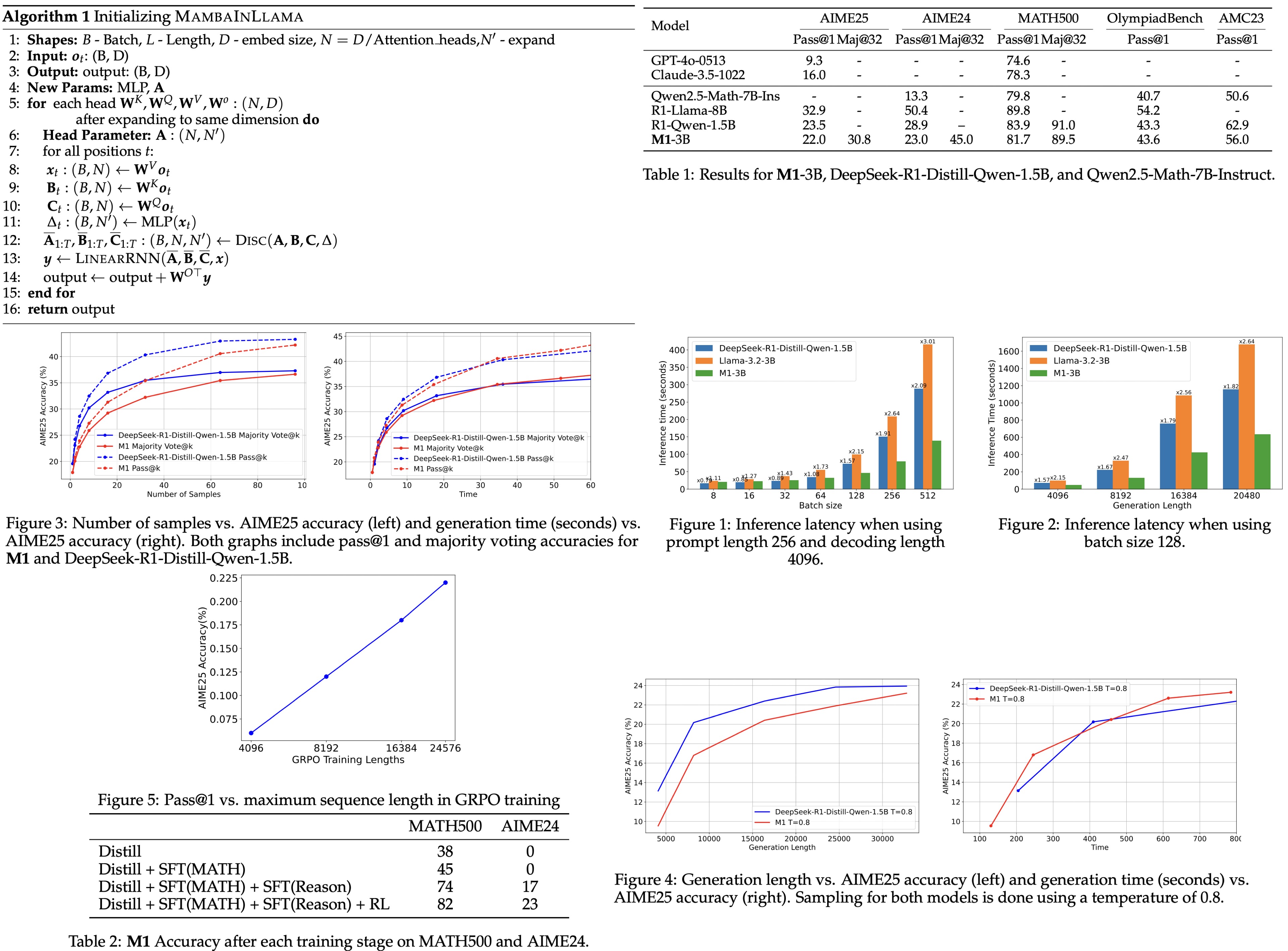
The models are evaluated with a temperature of 0.7 and 32k sequence length, using pass@1 over 64 runs and majority voting over 100 trials. Compared to DeepSeek-R1-Distill-Qwen-1.5B, M1-3B achieves competitive performance. It performs slightly worse on AIME24 but outperforms larger non-reasoning transformer models.
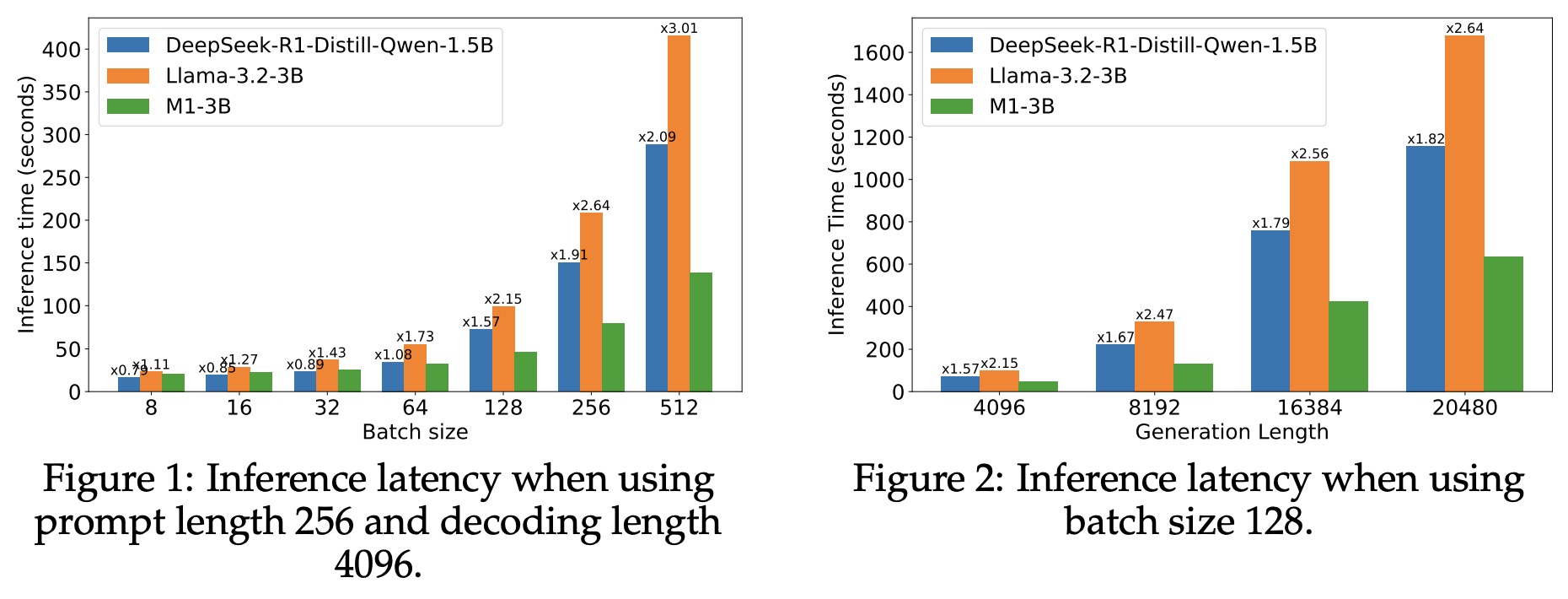
M1 is benchmarked against Llama-3.2-3B and DeepSeek-R1-Distill-Qwen-1.5B using vLLM on a single NVIDIA H100 GPU. With a decoding length of 4096 and prompt length of 256, M1 achieves up to 3x faster inference than similarly-sized transformers. When varying generation length with a fixed batch size, M1 consistently outpaces the baselines, reaching up to 2.64× speedup for the longest sequences.
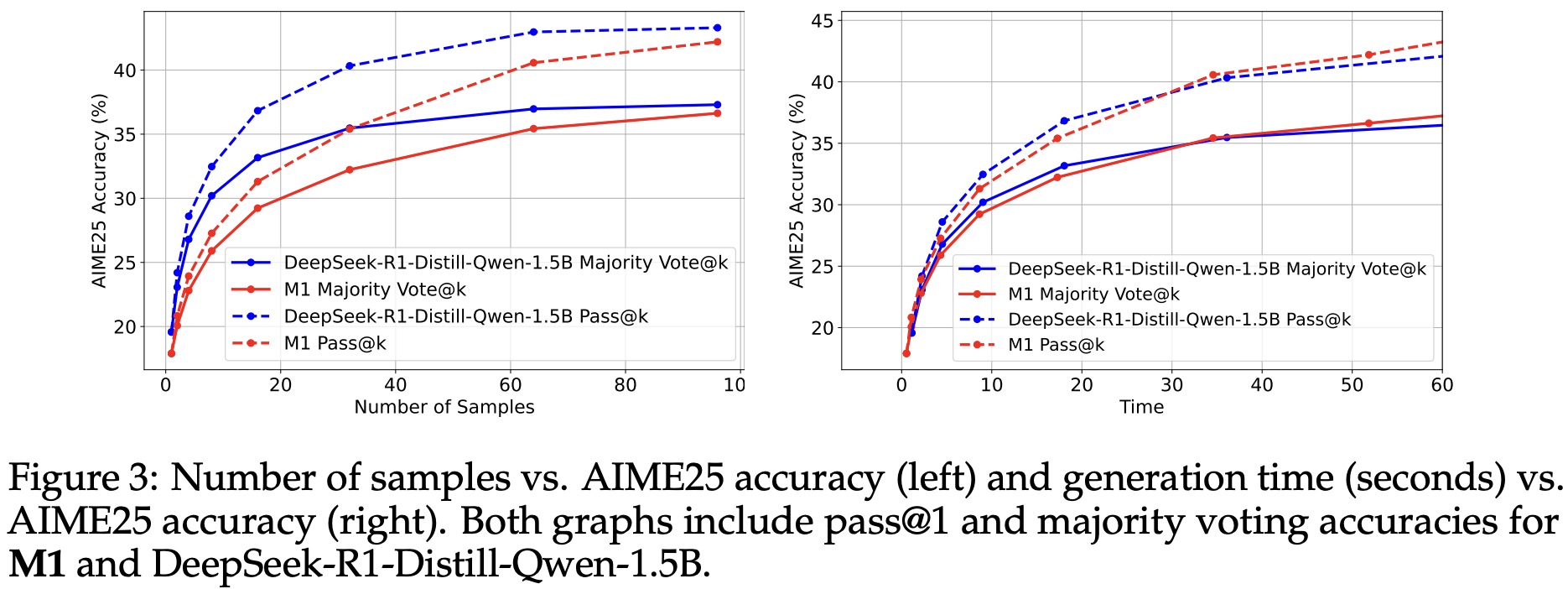
M1’s faster generation allows it to produce more or longer sequences within a fixed time budget, potentially boosting accuracy. When scaling the number of generated samples with majority voting, both M1 and the baseline improve in accuracy, but M1 does so more efficiently—reaching similar accuracy in less time due to higher throughput (15,169 vs. 7,263 tokens/sec).
Similarly, when scaling the maximum generation length, M1 achieves higher accuracy for the same compute time at most lengths, demonstrating that its speed advantage translates into better performance under compute-constrained test-time settings.
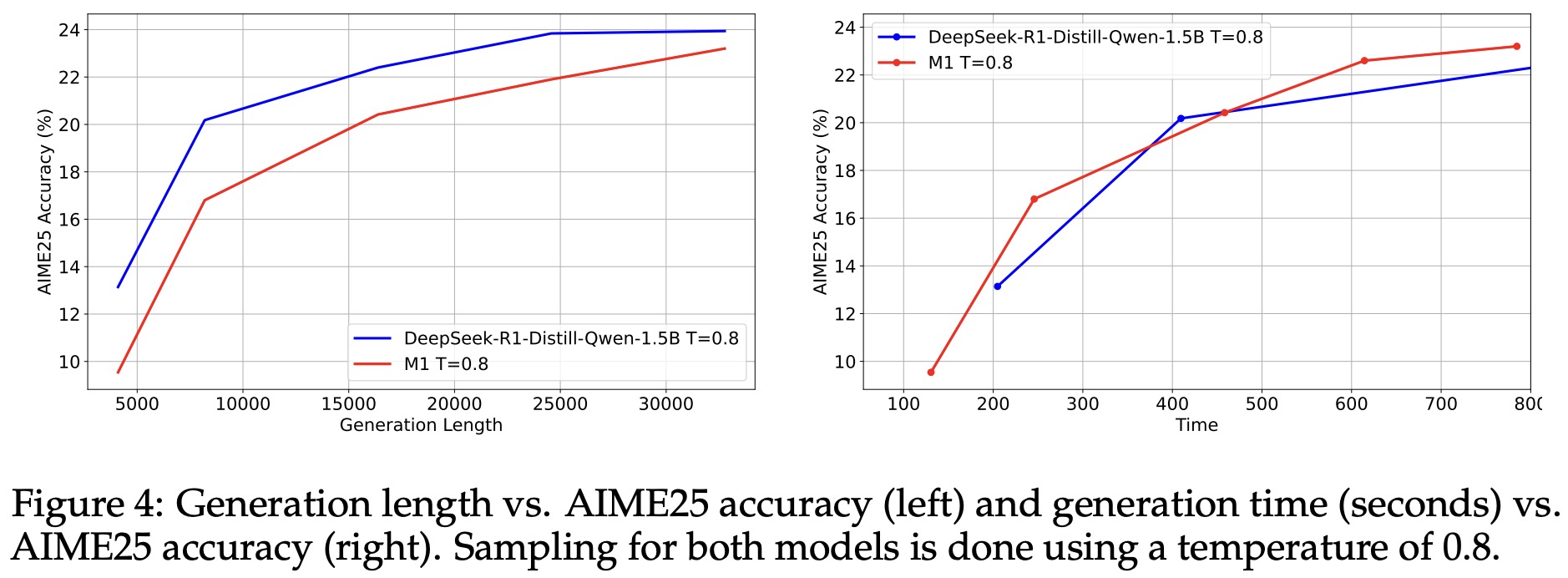
Longer sequences during RL training significantly boost M1’s performance, with accuracy on AIME25 rising from under 7.5% at 4K tokens to 22.5% at 24K tokens.
Evaluations at each training stage show that the biggest gains come from fine-tuning on model-generated reasoning solutions, improving MATH500 accuracy by 29% and AIME24 by 17%. An alternative approach (directly distilling from DeepSeek-R1-Qwen-1.5B using only the 8B reasoning dataset) performed poorly, suggesting that 8B tokens alone aren’t enough for effective transfer. A more effective strategy is to first distill on standard math problems (OpenMathInstruct), then fine-tune on reasoning data.
paperreview deeplearning rnn distillation nlp mamba reasoning llm