MiniMax Sparse Attention: Per-Group Block Selection for Cheap Million-Token Inference
Long-context LLMs keep promising the same thing: feed more tokens into the prompt and let the model reason over them. The bottleneck is rarely the window itself: it is the cost of attending over it once agentic workflows, repo-scale code reasoning, and persistent memory push the context into the hundreds of thousands or millions of tokens. Softmax attention is quadratic, so million-token context is not just a modeling challenge, but an inference-cost and deployment challenge.
MiniMax Sparse Attention (MSA) is the attention design behind MiniMax M3, and it tackles this problem with blockwise sparsity built on top of Grouped Query Attention. The idea is to keep exact softmax attention but run it over a tiny, query-dependent subset of the key-value history instead of the whole thing. A lightweight Index Branch decides which blocks matter, and the expensive Main Branch perform exact softmax attention only over those selected blocks. At 1M-token context, MSA cuts per-token attention FLOPs by 28.4x against a dense GQA baseline of the same 109B-parameter configuration, while staying on par with it on quality.
This is the same framing DeepSeek used for its sparse attention. The interesting question is no longer maximum context length, but whether the model can compute over a long context cheaply enough to deploy. MSA’s particular bet is per-group block selection, and most of the design follows from that choice.
You can read about my experience with MSA in the MiniMax M3 review, which covers its multimodal capabilities.
The approach
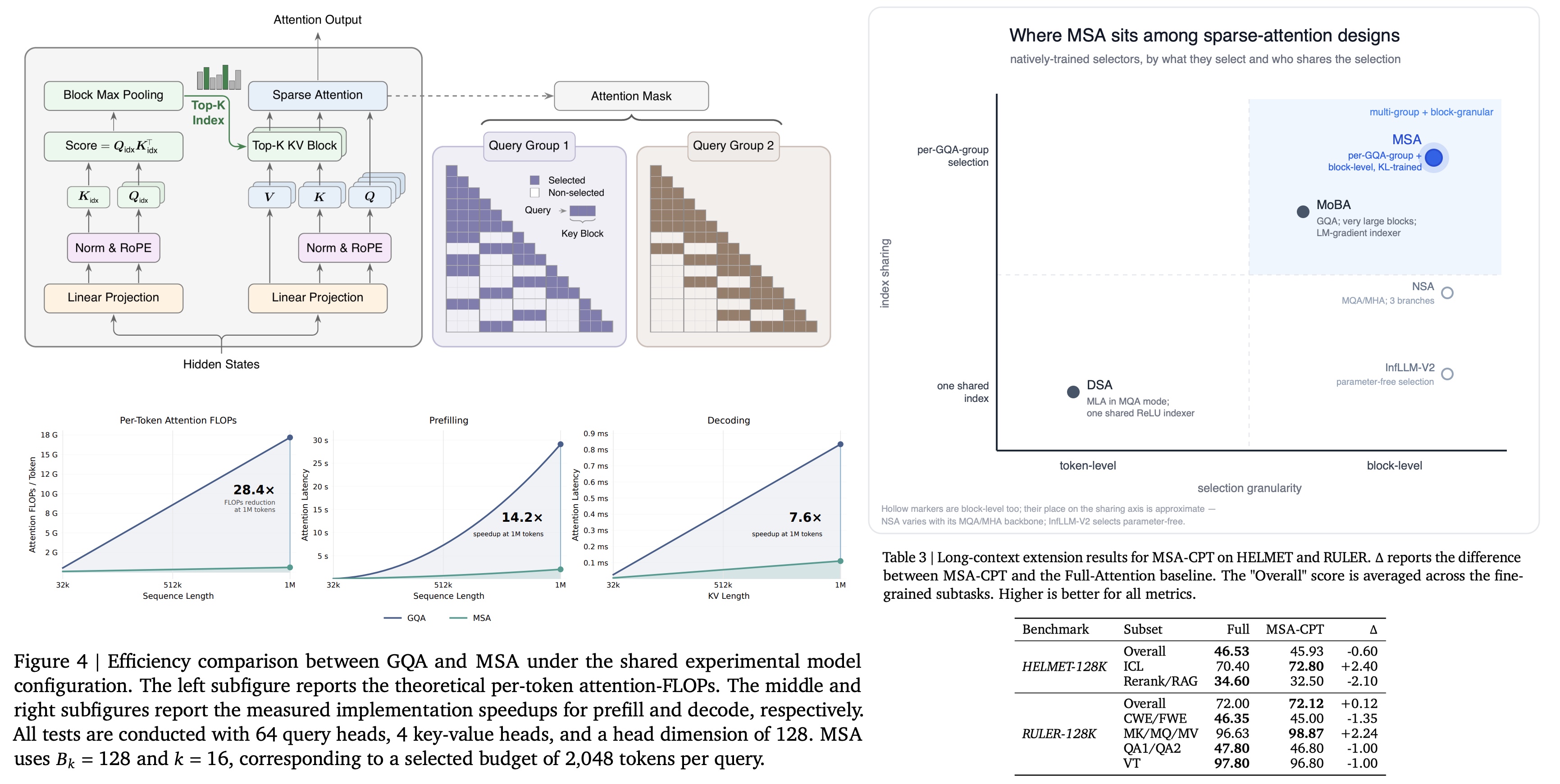
Two branches over one GQA backbone
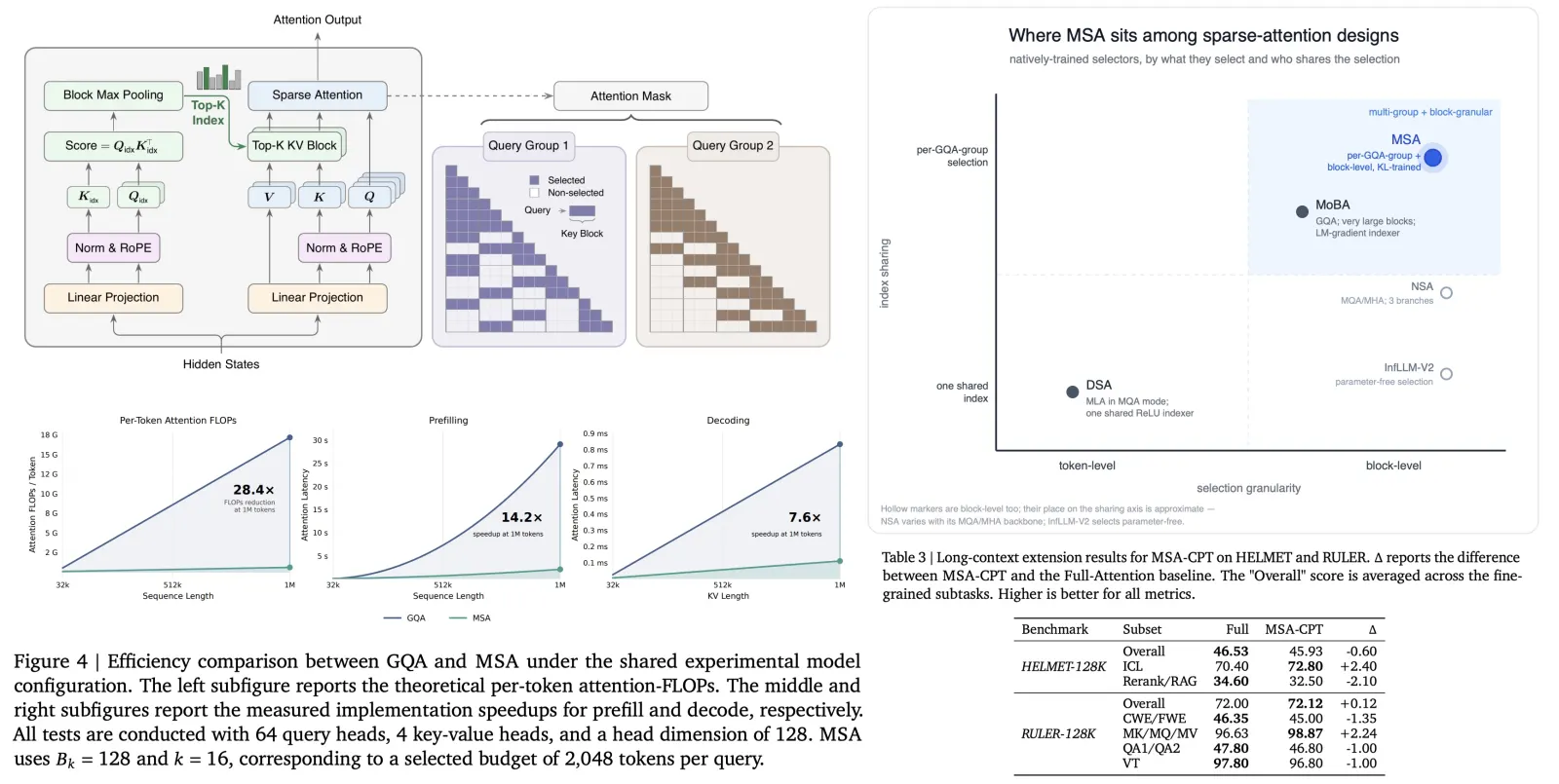
MSA splits each attention layer into an Index Branch and a Main Branch that share the same GQA backbone. The Index Branch adds one index-query head per GQA group and a single shared index-key head, scores every causally visible key token, then max-pools those scores up to the block level. For each GQA group it keeps the top-16 of those 128-token blocks, always force-including the local block that holds the query, for a fixed 2,048-token selection budget. The Main Branch then runs standard exact softmax attention restricted to exactly those selected blocks. Per-query cost drops from growing with sequence length to a constant set by the budget, so attention compute stays flat as context grows.
The design choice that separates MSA from its neighbors is that the Top-k selection is shared per GQA group rather than across all query heads, and it applies at block granularity rather than token granularity. Each group retrieves its own blocks, which preserves multi-group selectivity, while block-level selection keeps the KV reads contiguous so the kernel can stay efficient.
Training a non-differentiable selector

Top-k selection is not differentiable, so the Index Branch cannot learn from the language-model loss directly. MSA trains it with a KL alignment loss that matches the index branch’s block-score distribution to the Main Branch’s actual attention distribution over the selected tokens, so the selector learns to predict which blocks the exact attention would have wanted. Gradient detach confines this auxiliary loss to the index projections alone, keeping it from perturbing the rest of the model. Training starts with an indexer warmup that runs full attention before switching to sparse, which gives the local block a stable target to imitate. The same warmup recipe is what converts a pretrained dense checkpoint into a sparse one.
That conversion path is worth separating from training from scratch, because the two behave differently. MSA-PT is trained sparse from the start; MSA-CPT takes an existing dense GQA checkpoint, swaps in MSA, and continues training.
Experiments
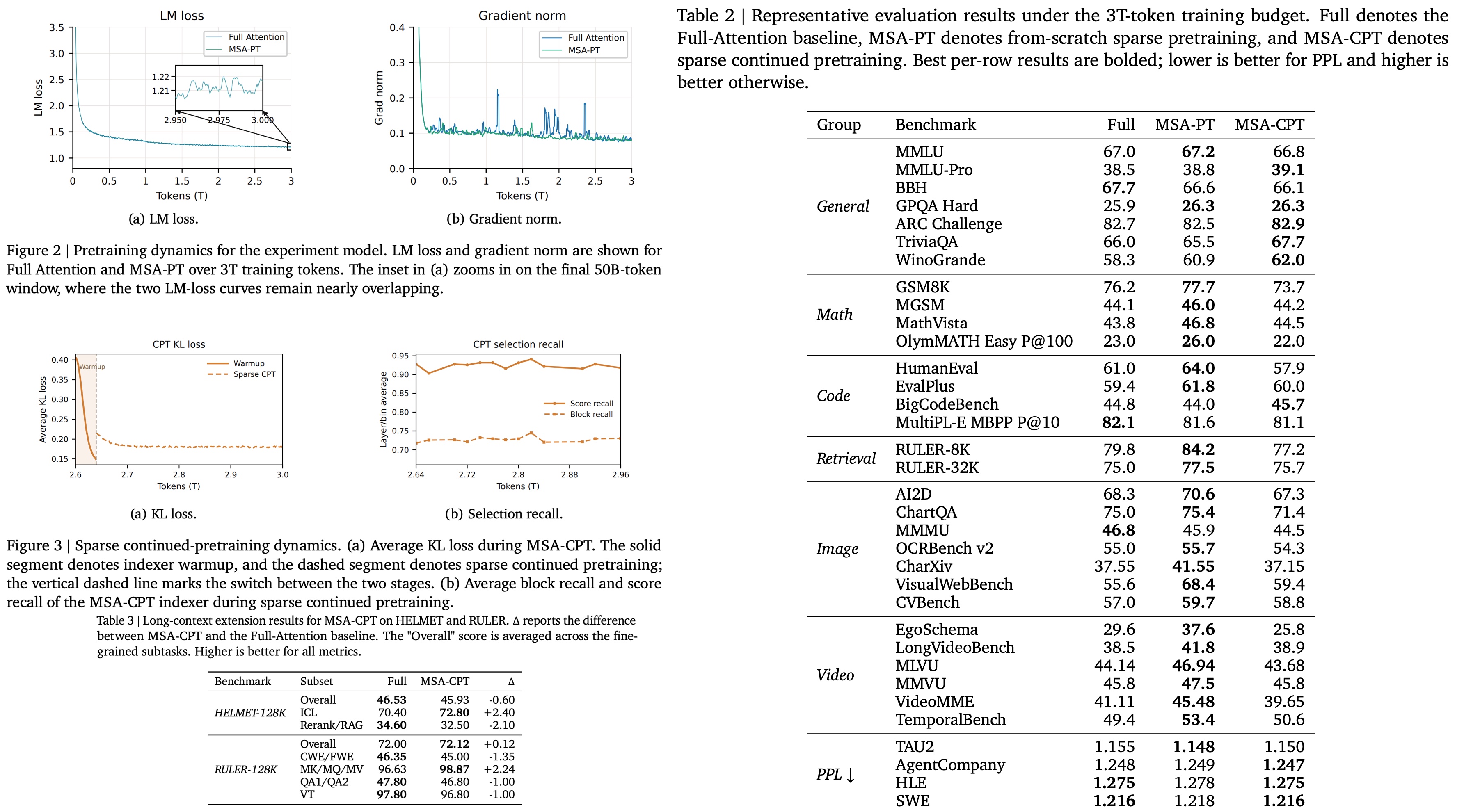
On quality, MSA-PT matches or slightly beats the dense Full-Attention baseline across most of the benchmark table, with the largest margins on multimodal and long-context tasks. MSA-CPT, the conversion route, stays close to the dense checkpoint it started from and is strongest on text, code, and perplexity. The sparse beats dense claims warrant some caution: these are research-scale 109B models trained on only 3T tokens, and the multimodal jumps may reflect native sparse pretraining acting as a form of regularization at this scale rather than evidence that sparse attention wins at frontier scale.
The ablations show that a sliding-window baseline held to the same FLOP budget has uniformly higher perplexity than MSA.
At 1M context, MSA delivers a measured 14.2x prefill and 7.6x decode wall-clock speedup on H800 against the dense GQA baseline, both growing with context length. The paper is honest that the runtime gains are smaller than the 28.4x FLOPs reduction would suggest: index construction, Top-k selection, and a less regular memory-access pattern all decrease the theoretical win.
Conclusions

There are two major approaches within sparse-attention research. One sparsifies a model that was already pretrained densely: methods such as H2O, SnapKV, Quest, MInference, and InfLLM reduce the cost of long-context inference by pruning, compressing, or selectively retrieving from the KV cache. While effective, they inherit the quadratic cost of dense pretraining and can only approximate the attention patterns the model originally learned.
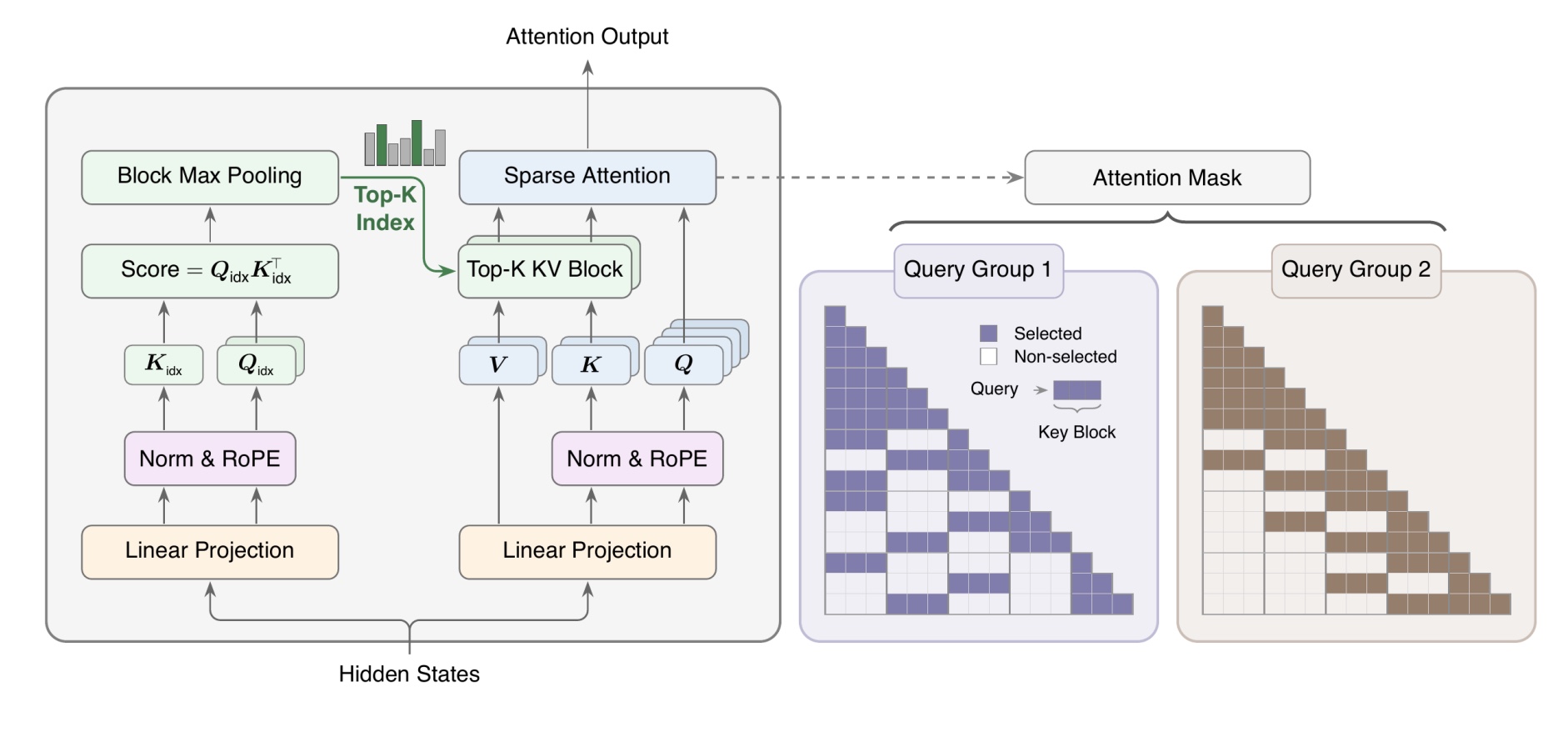
MSA belongs to the second group, where sparsity is built into training from the beginning. The model learns to operate under a fixed attention budget rather than being sparsified after the fact. Several architectures pursue this idea in different ways. NSA combines compressed, selected, and sliding-window attention branches; MoBA performs routing at block granularity using block-level summaries and learns routing implicitly through the language-model objective; InfLLM-V2 retrieves relevant blocks without introducing a learned routing network. The most similar is DeepSeek’s DSA, which performs sparse token-level retrieval on top of Multi-head Latent Attention using a lightweight ReLU-based indexer.
MSA’s distinguishing feature is its combination of per-GQA-group retrieval and block-level sparsity. Instead of forcing all heads to share the same sparse view of the context, each GQA group selects its own relevant blocks. At the same time, operating on contiguous blocks rather than individual tokens produces a sparsity pattern that maps efficiently onto GPU kernels, allowing MSA to improve both retrieval flexibility and hardware efficiency.
I like that MSA is a complete, deployed system rather than a proposal, with a released inference kernel and the cheap MSA-CPT conversion route that lets an existing dense model become sparse without retraining from scratch. At the same time, there are certain caveats: the runtime speedup trails the FLOPs reduction, retrieval-heavy long-context subtasks don’t show outstanding performance, and the scope focuses on pretraining, with no RL or post-training and no benchmark against NSA, MoBA, or DSA.
paperreview deeplearning llm attention efficiency moe minimax