Paper Review: Pref-GRPO: Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning
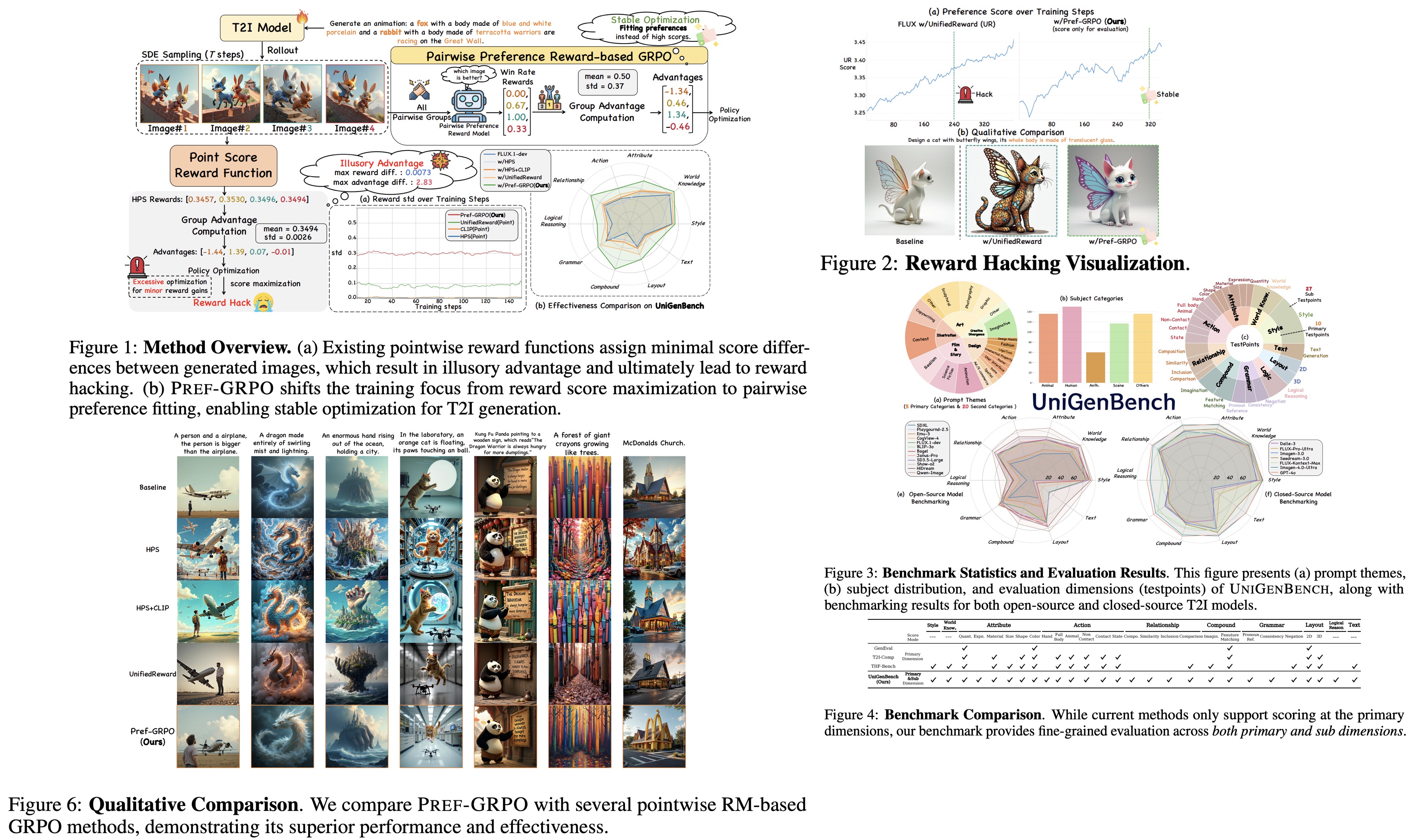
GRPO-based reinforcement learning improves text-to-image generation, but pointwise reward models often cause reward hacking, where small score differences are amplified during normalization and lead to unstable training and lower image quality. Pref-GRPO replaces score maximization with pairwise preference fitting, using win rates from image comparisons as training signals, which provides more stable optimization, better recognition of subtle quality differences, and reduces reward hacking.
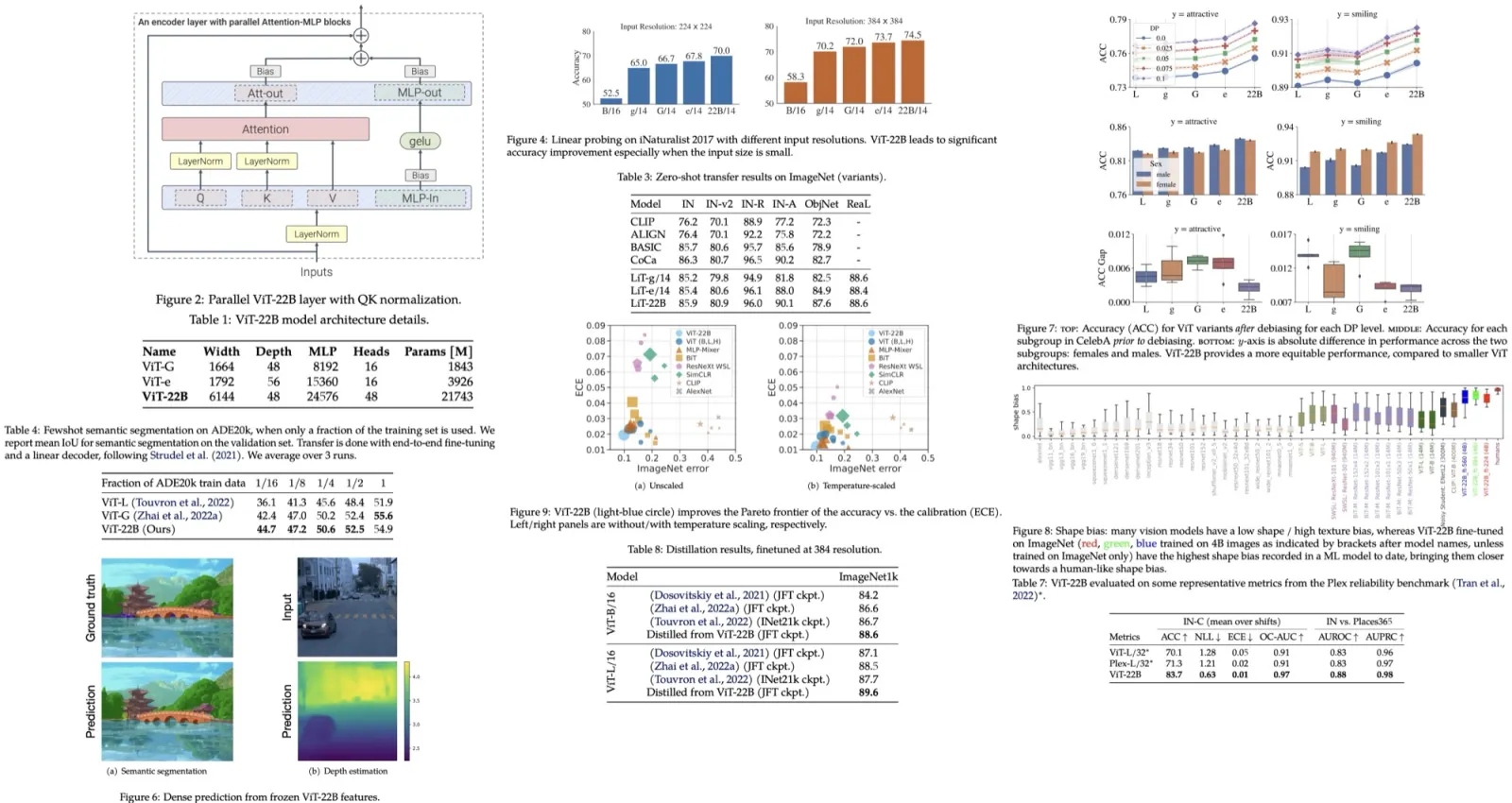
To complement this, the authors introduce UniGenNBench - a unified benchmark with 600 prompts across 5 themes and 20 subthemes, evaluating models on 10 primary and 27 sub criteria using multimodal large language models. This enables fine-grained assessment of text-to-image models, reveals their strengths and weaknesses, and validates the effectiveness of Pref-GRPO.
Pref-GRPO
Flow Matching GRPO
Flow matching generates intermediate samples by interpolating between real data and noise, and trains a velocity field to match the true flow. At inference, denoising can be seen as a Markov Decision Process where actions produce cleaner samples, and rewards are given only at the final step based on image–prompt quality.
GRPO stabilizes training by computing group-relative advantages, normalizing rewards across a batch of generated images. The policy is updated with a clipped objective that balances advantage-weighted likelihood ratios with KL regularization against a reference policy.
Since GRPO requires stochastic exploration, deterministic flow ODEs are converted into equivalent SDEs by adding controlled noise. This leads to a stochastic update rule using Euler–Maruyama discretization, where the noise scale is controlled by a hyperparameter controlling randomness during training.
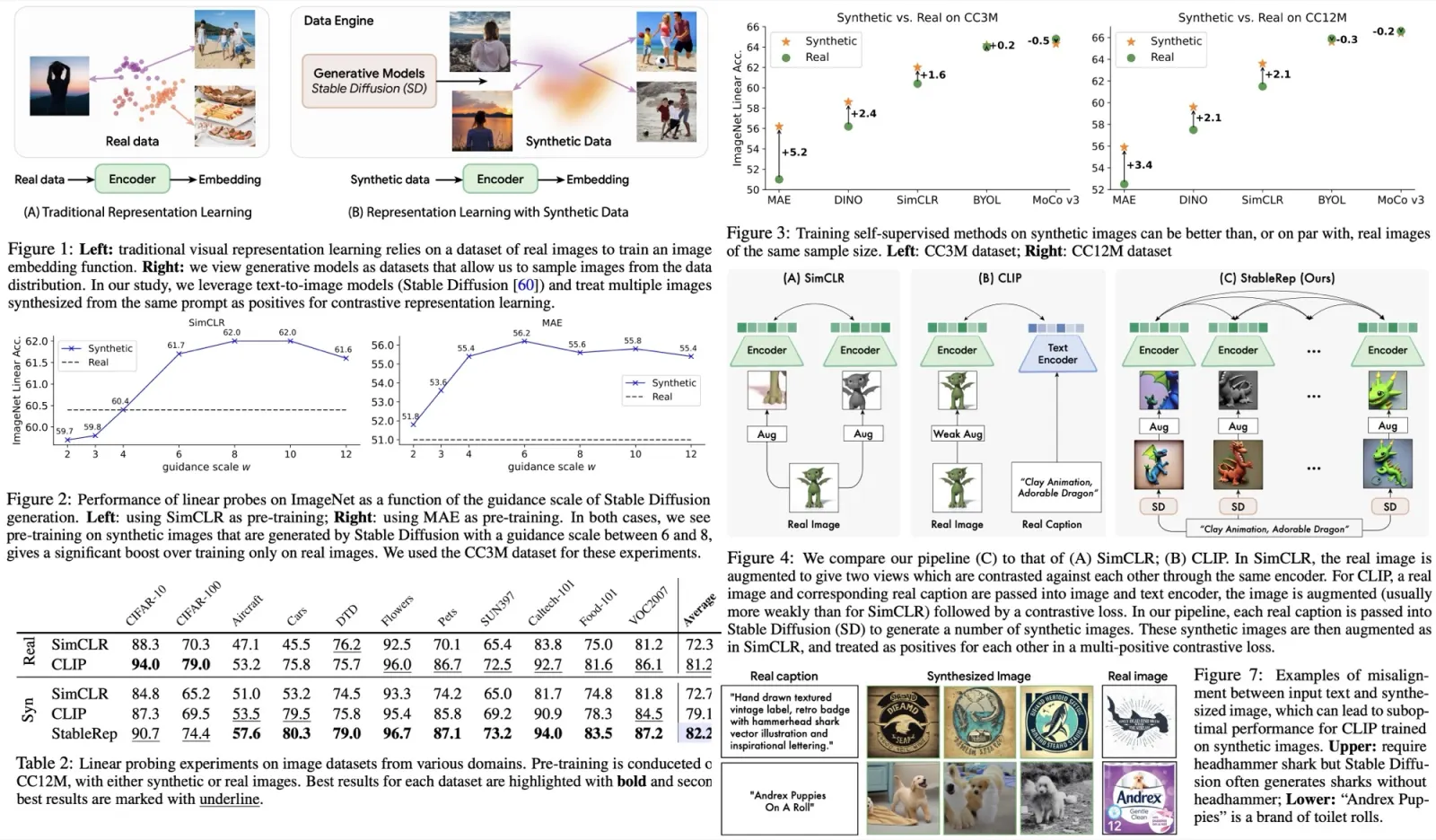
Illusory advantage in reward score-maximization GRPO methods

Flow matching–based GRPO methods use pointwise reward models to score generated images and compute group-normalized advantages. Since these reward models often assign nearly identical scores to similar images, the standard deviation of rewards becomes very small. This causes tiny score differences to be disproportionately amplified, creating an illusory advantage. The effect leads to excessive optimization, reward hacking, and heightened sensitivity to noise or biases in the reward model, pushing the policy toward exploiting flaws rather than aligning with true preferences.
Pairwise preference reward-based GRPO
PRref-GRPO replaces absolute reward scoring with a pairwise preference reward model that compares images directly and assigns win rates based on relative quality. These win rates are used as rewards, producing more stable and discriminative signals for policy optimization. This approach mitigates reward hacking by amplifying reward variance, reduces sensitivity to noise by relying on rankings rather than raw scores, and better aligns with human judgment by reflecting how people naturally evaluate images through comparisons.
UniGenBench
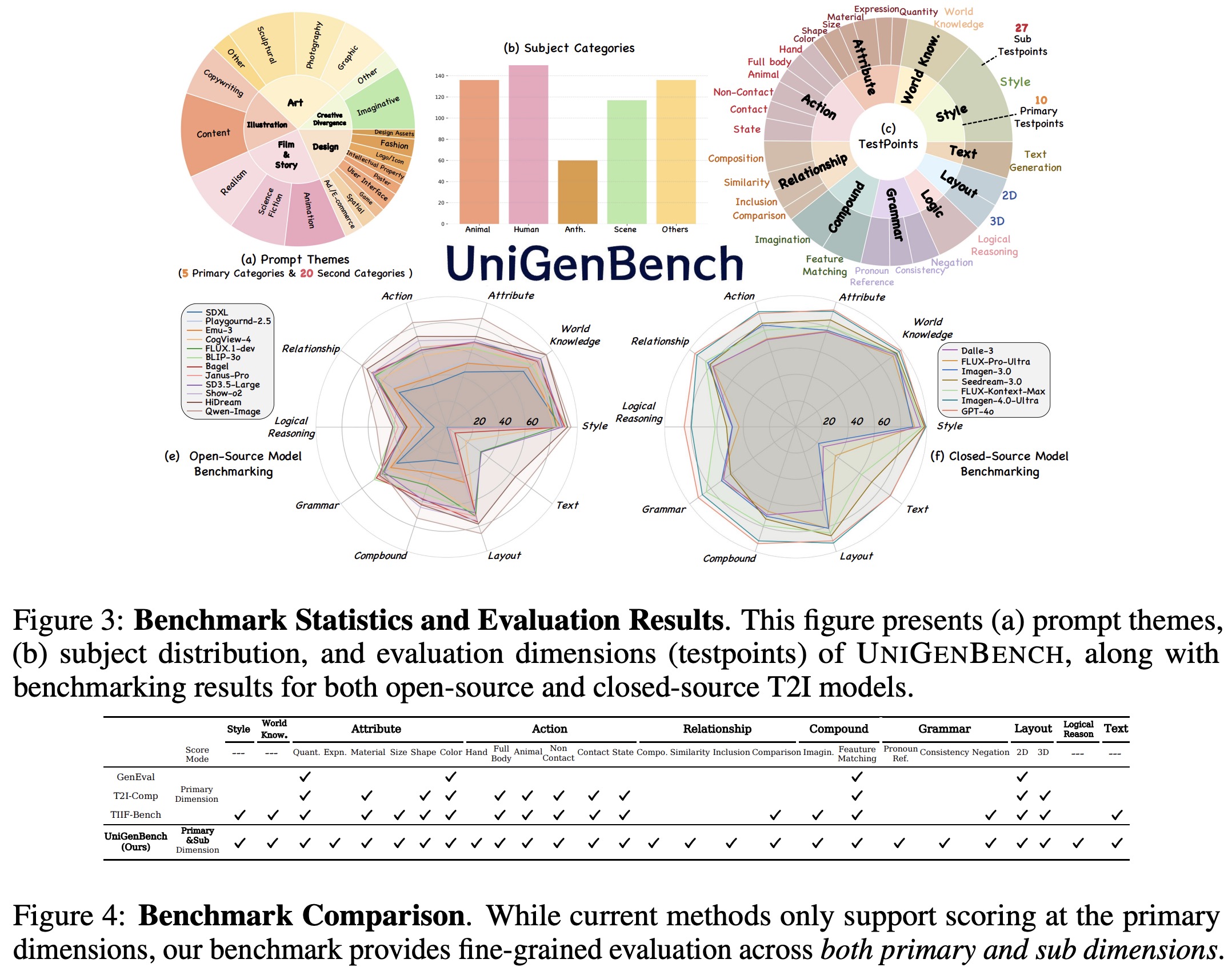
Existing benchmarks for text-to-image models are limited because they cover only a few sub-dimensions within each evaluation area and provide scores only at the primary dimension level, resulting in incomplete and coarse assessments. UniGenBench introduces a unified benchmark with five major prompt themes (Art, Illustration, Creative Divergence, Design, and Film&Storytelling) and 20 subcategories, along with 10 primary and 27 sub-dimensions. This design enables fine-grained evaluation across aspects such as logical reasoning, facial expressions, and pronoun reference, offering a more comprehensive and interpretable assessment of model capabilities and alignment with human intent.
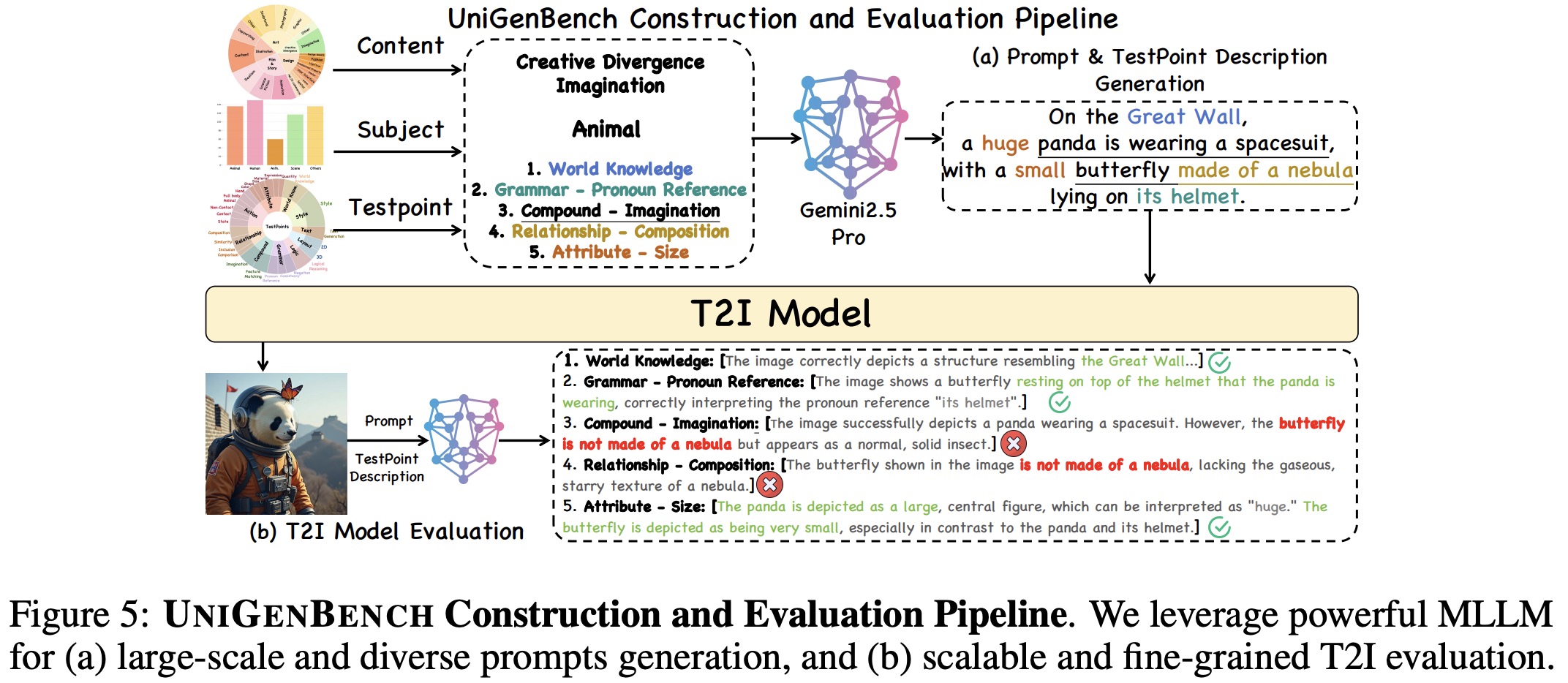
The benchmark uses an MLLM-based pipeline for both prompt generation and model evaluation. For each case, a theme, subject category, and a small set of fine-grained evaluation dimensions are sampled, then the MLLM generates a natural language prompt and structured descriptions specifying how the chosen testpoints appear in it. During evaluation, each generated image, along with its prompt and descriptions, is assessed by the MLLM, which provides binary scores and textual rationales for each testpoint. These scores are then aggregated across prompts to compute sub-dimension and primary dimension results, resulting in scalable, fine-grained, and interpretable evaluation without human annotation.
Experiments

Pref-GRPO is evaluated using FLUX.1-dev as the base model and UnifiedReward-Think as the pairwise preference reward model, with baselines including HPS, CLIP, and UnifiedReward. Training uses 5k prompts from the benchmark pipeline, and evaluation uses UniGenBench, GenEval, T2I-CompBench, and several image quality metrics.
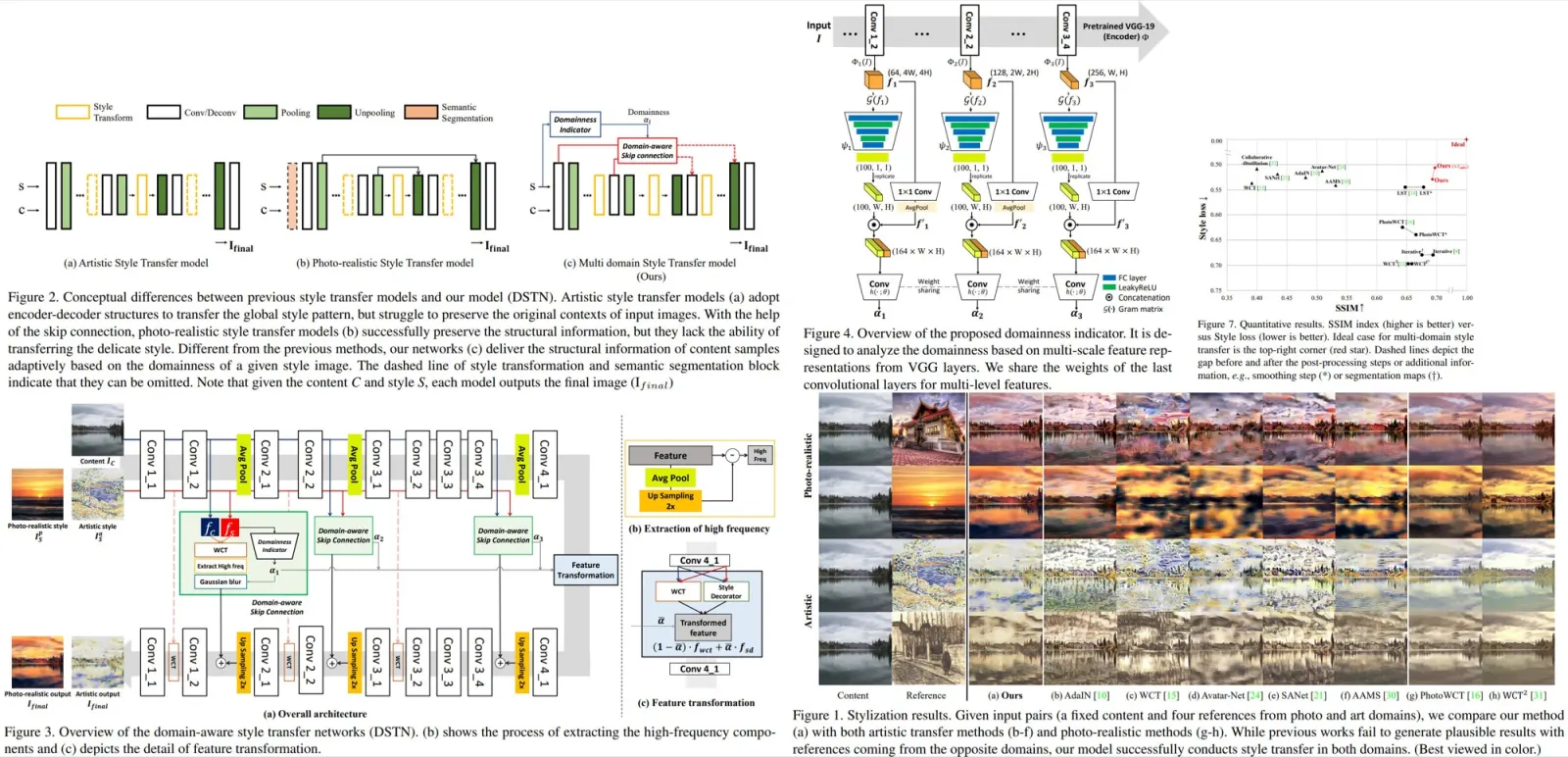
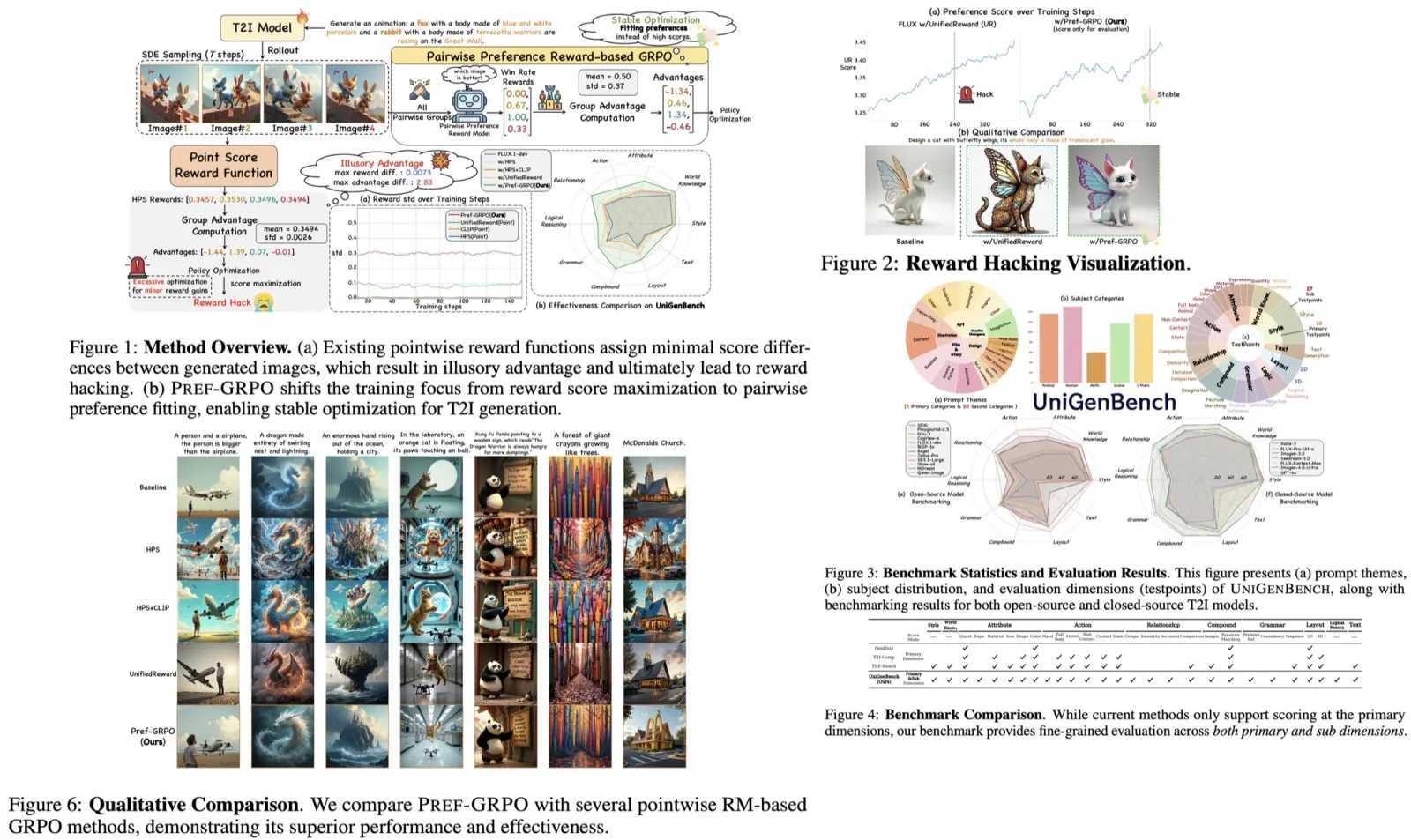
Results show that Pref-GRPO achieves clear gains over reward-maximization baselines, including a 5.84% overall improvement on UniGenBench, with large boosts in text rendering and logical reasoning. It also improves image quality while avoiding common reward hacking issues, such as oversaturation from HPS or darkening from UR. Unlike score-maximization methods that show inflated scores but degraded visuals, Pref-GRPO yields gradual but stable improvements in quality.
Closed-source models like GPT-4o and Imagen-4.0-Ultra remain strongest, especially in logical reasoning, text rendering, and relationships, while open-source models such as Qwen-Image and HiDream are narrowing the gap, excelling in action, layout, and attributes but still lagging in difficult areas like grammar and compound reasoning.
paperreview deeplearning imagegeneration cv rl