Paper Review: Real-World Super-Resolution of Face-Images from Surveillance Cameras

I think that it is crucial for people to know how good are the technologies concerning surveillance. Most SR methods are trained on LR (low resolution) data, which is downsampled from HR (high resolution) data using bicubic interpolation, but real-life LR images are usually different, so models work worse on them. In this paper, the authors do the following:
- use blur kernels, noise, and JPEG compression artifacts to generate LR images similar to the original ones
- use ESRGAN, replacing VGG-loss with LPIPS-loss and adding PatchGAN
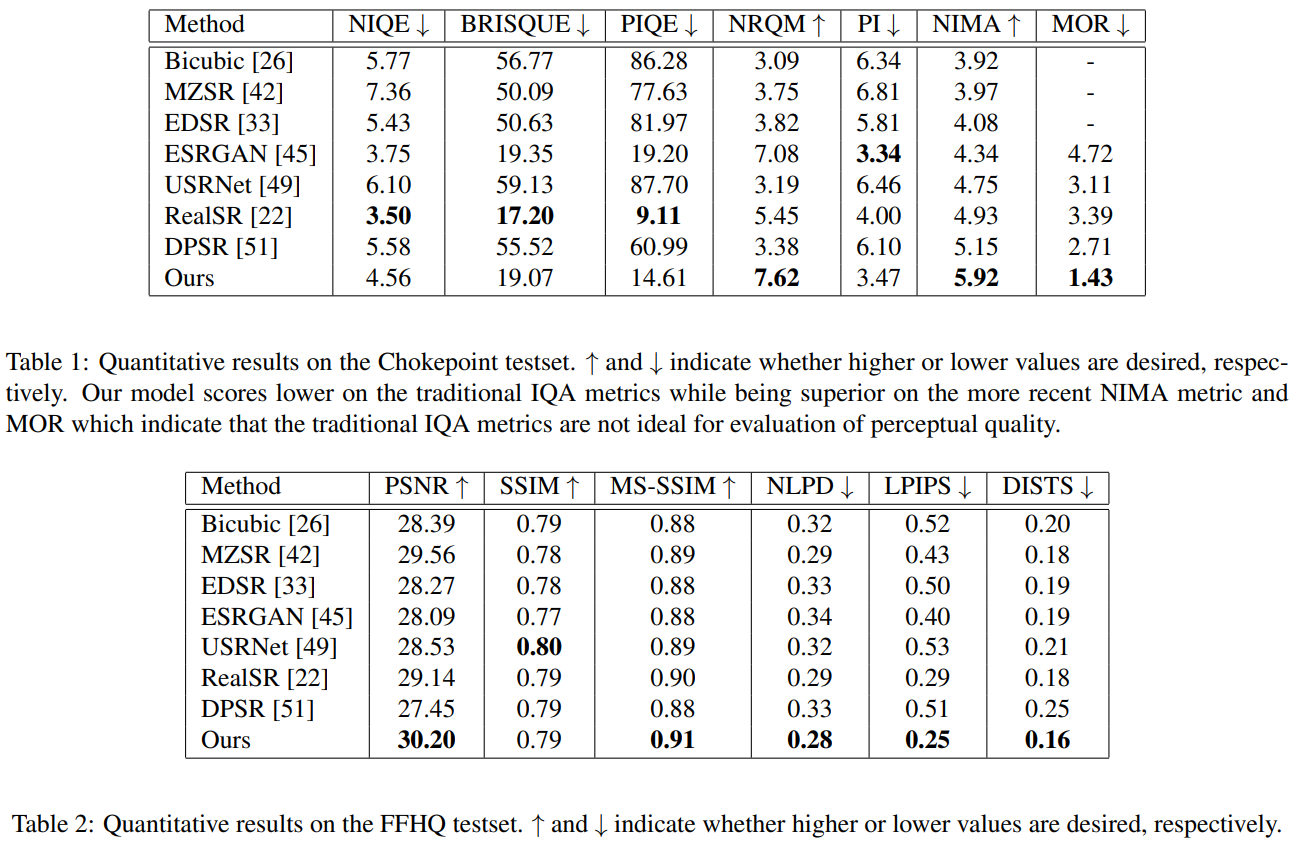
- show that NIMA metric better correlates with human perception (mean opinion rank) than traditional Image Quality Assessment methods
Novel Image Degradation
Usually, LR image is a result of a downscaling operation using some kernel and a scaling factor. The authors suggest using blur kernel, noise, and compression artifacts.
- blur kernel: unsupervised, using KernelGAN
- noise: take an area with a weak background (not sure what is it) and subtract the mean
- compression artifacts: JPEG compression with strength 30
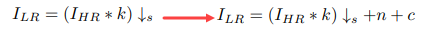
Model
Backbone: ESRGAN with x4 upscaling
Exchange VGG-128 discriminator with PatchGAN discriminator to reduce the number of artifacts
Replace VGG loss with LPIPS-loss for the generator to produce less noise and richer textures. This works because VGG is mainly for classification, but LPIPS is trained to score image patches based on human perceptual similarity judgments.
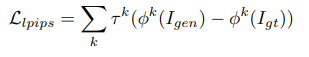
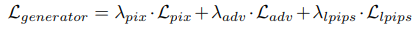
Examples of the results


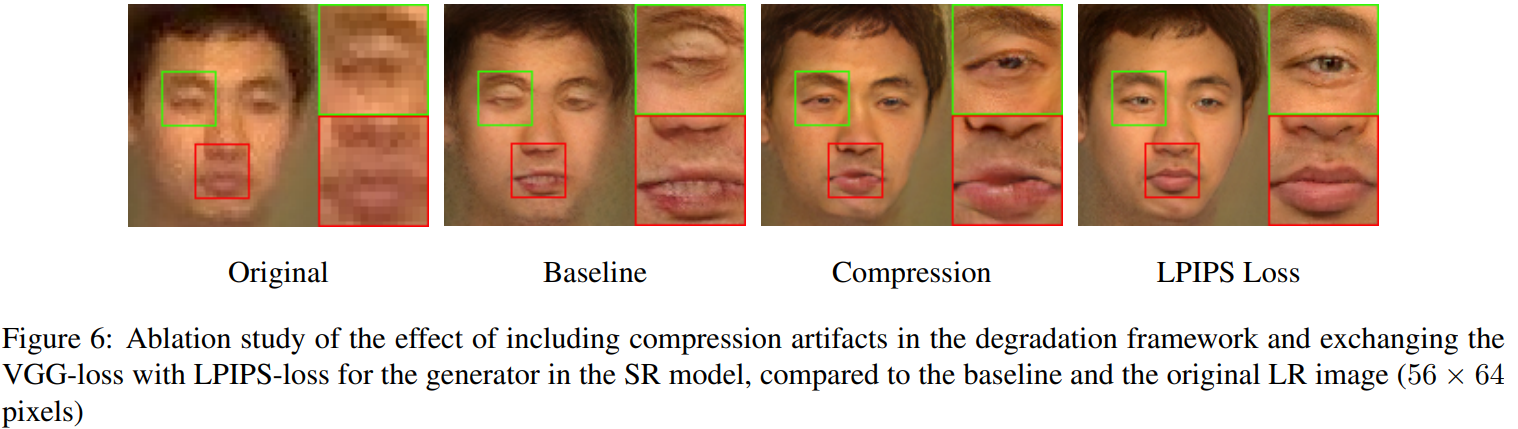

Some of experiments weren’t clearly described and they “played” with the datasets. But I liked that they described the failure cases. In general this was an interesting paper
paperreview deeplearning superresolution cv