Paper Review: SLiMe: Segment Like Me

Large vision-language models like Stable Diffusion have made advances in tasks like image editing and 3D shape generation. A new method, SLiMe, has been proposed to use these models for image segmentation with as little as one annotated sample. The process involves extracting attention maps from the SD model, including a new “weighted accumulated self-attention map”. Using these attention maps, the text embeddings of the SD model are optimized to learn a single segmented region from the training image. This allows SLiMe to segment images at the desired granularity using just one example during inference. Additionally, using few-shot learning enhances SLiMe’s performance. Experimental results reveal that SLiMe surpasses other one-shot and few-shot segmentation techniques.
Background
Latent diffusion models
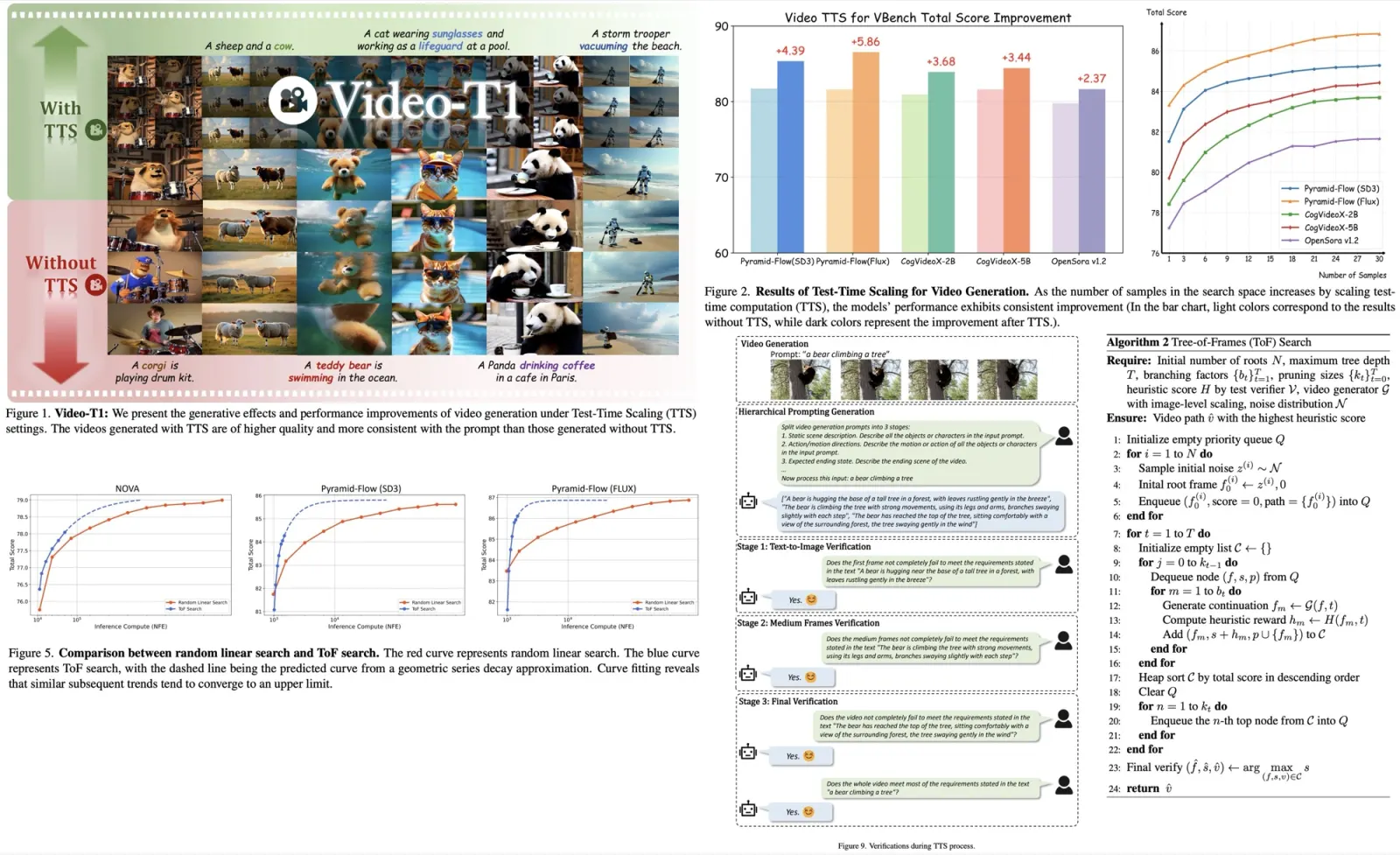
Latent Diffusion Models are a type of generative model that compresses input random variables into a latent space characterized by a Diffusion Model. An LDM uses an autoencoder trained on a vast collection of images. The encoder generates an image embedding, and the decoder aims to reverse map this embedding back into the image space. The autoencoder can be either a discrete or a continuous generative model optimized using KL-divergence loss.
In text-conditioned LDMs, the DM is conditioned on text. A natural language prompt is tokenized and then transformed into a text embedding via a text encoder. This embedding serves as one of the inputs for the DM. To train the text-conditioned LDM, time-dependent noise is added to the image embedding, and an objective function is used to optimize the parameters for noise prediction and elimination.
The authors employ Stable Diffusion for its ability to establish rich semantic connections between text and image embeddings. SD’s autoencoder also transforms the input image into a semantically meaningful latent vector that captures both global and local information, enhancing the relationship between text and image.
Attention modules

DM used in SD incorporates a UNet structure with ResNet blocks and two types of attention modules: self-attention and cross-attention. The self-attention module calculates relationships within the image embedding, helping to highlight areas in the image that share a similar semantic context. As you move away from a specific pixel, the intensity of this semantic relationship diminishes.
Cross-attention, on the other hand, calculates relationships between text and image embeddings. Each text token generates an attention map that highlights relevant pixels in the image embedding. For example, if the text input is “a bear,” the attention map will emphasize the pixels corresponding to the bear in the generated image.
Method
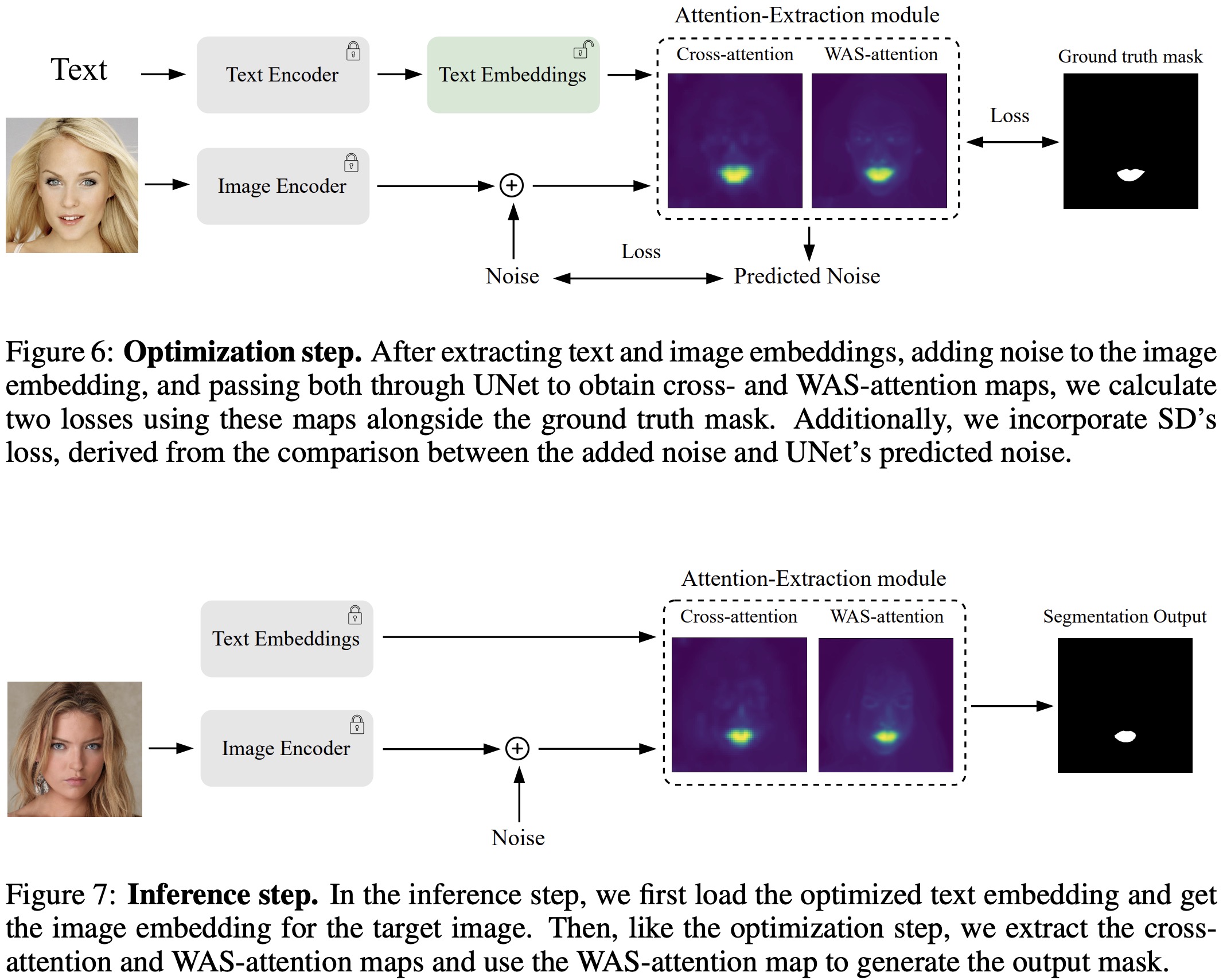
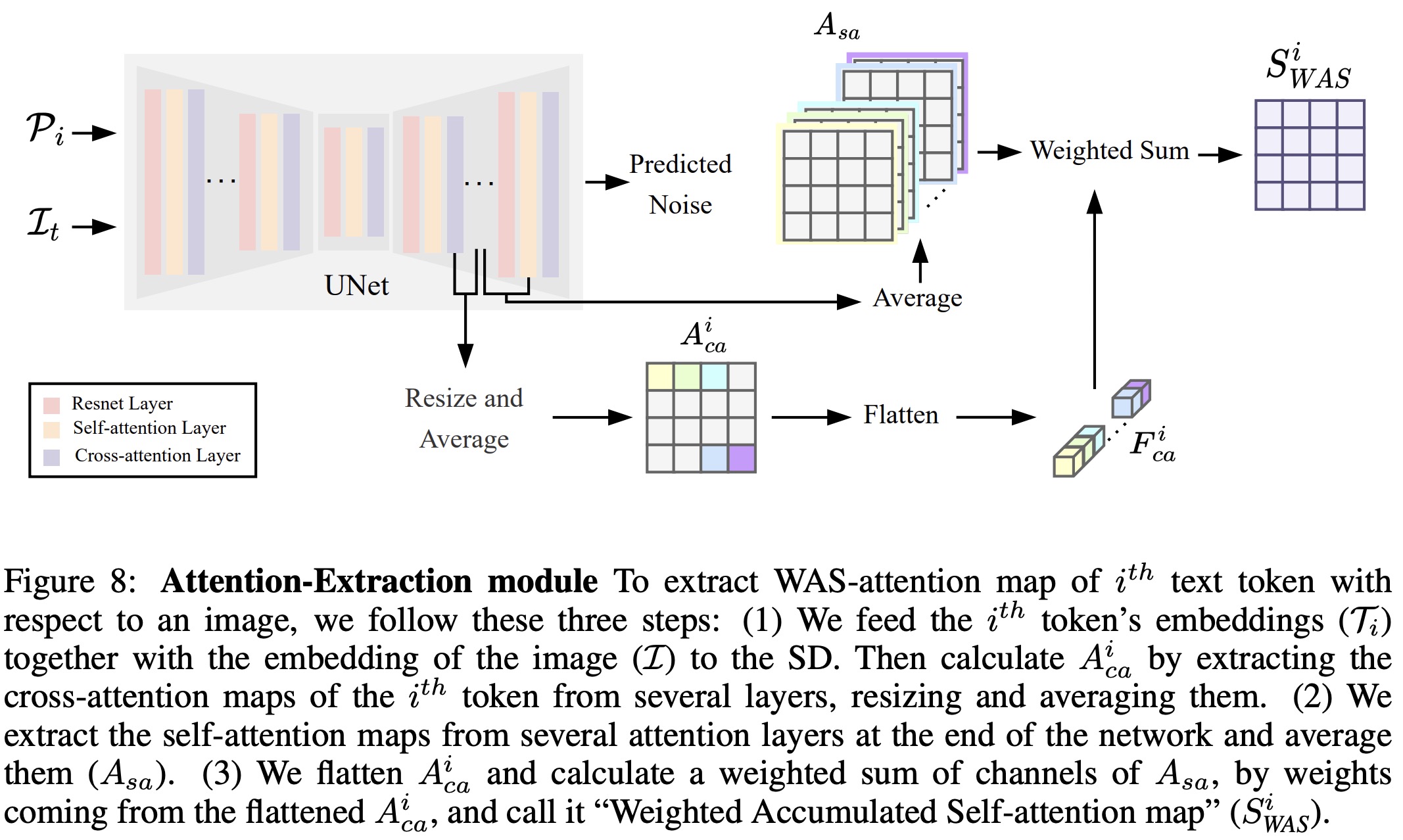
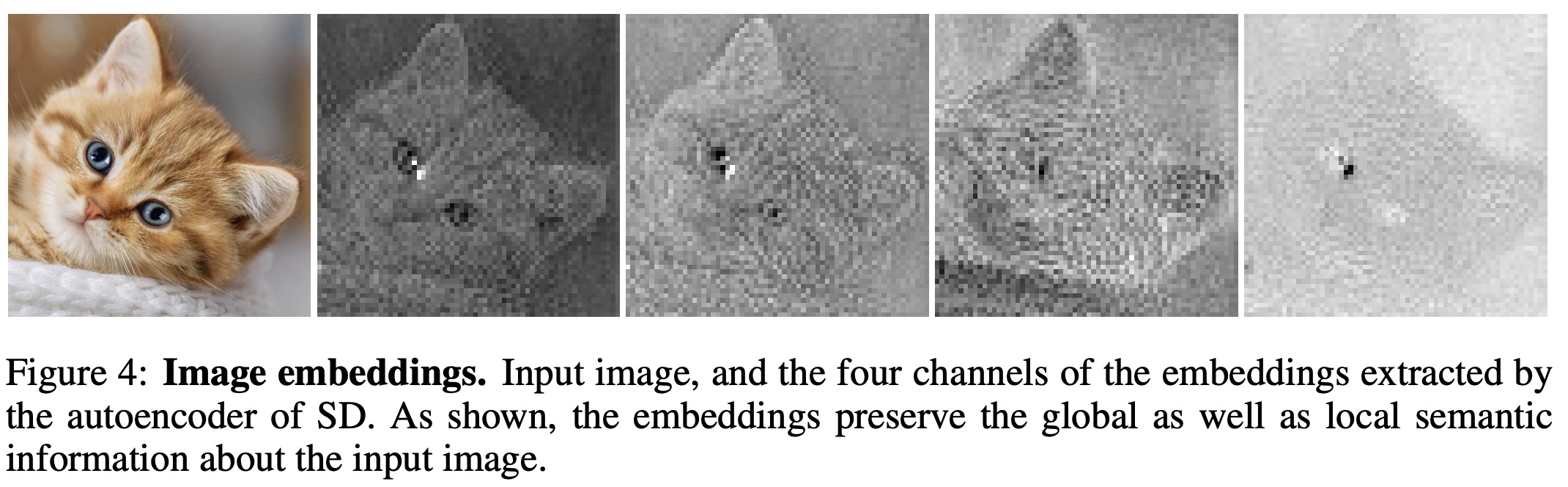
Optimizing text embeddings
The optimization process for text embeddings in SD begins with an empty text input and a segmentation mask for an image. The text input is tokenized and processed through SD’s text encoder to create text embeddings. These embeddings, along with the image embeddings and Gaussian noise, are then fed into a UNet structure to produce denoised image embeddings.
To optimize the text embeddings for segmentation, normalized cross-attention and self-attention maps are extracted from various layers within the model. The cross-attention maps are focused on highlighting specific classes in the segmentation mask, while self-attention maps provide richer semantic information and more accurate segmentation boundaries. These maps are averaged and resized for uniformity.
A multi-objective loss function is used to train the text embeddings, consisting of cross-entropy loss for the attention maps, MSE loss for the refined attention map, and an additional MSE loss related to the added noise in the model.
Inference
During the inference stage, the goal is to segment a test image with the same level of detail as was achieved during training. The test image is first encoded into SD’s latent space, and standard Gaussian noise is added, maintaining consistency with the training phase. Optimized text embeddings are then used alongside the encoded image to generate cross-attention and self-attention maps using a forward pass through the UNet model. WAS-attention maps are extracted for each text embedding index, and the first K of these maps are selected, corresponding to K classes. These maps are resized and stacked to match the dimensions of the input image. Finally, a segmentation mask is created using an argmax operation across the channels. This inference process can be applied to multiple test images without the need for retraining.
Experiments
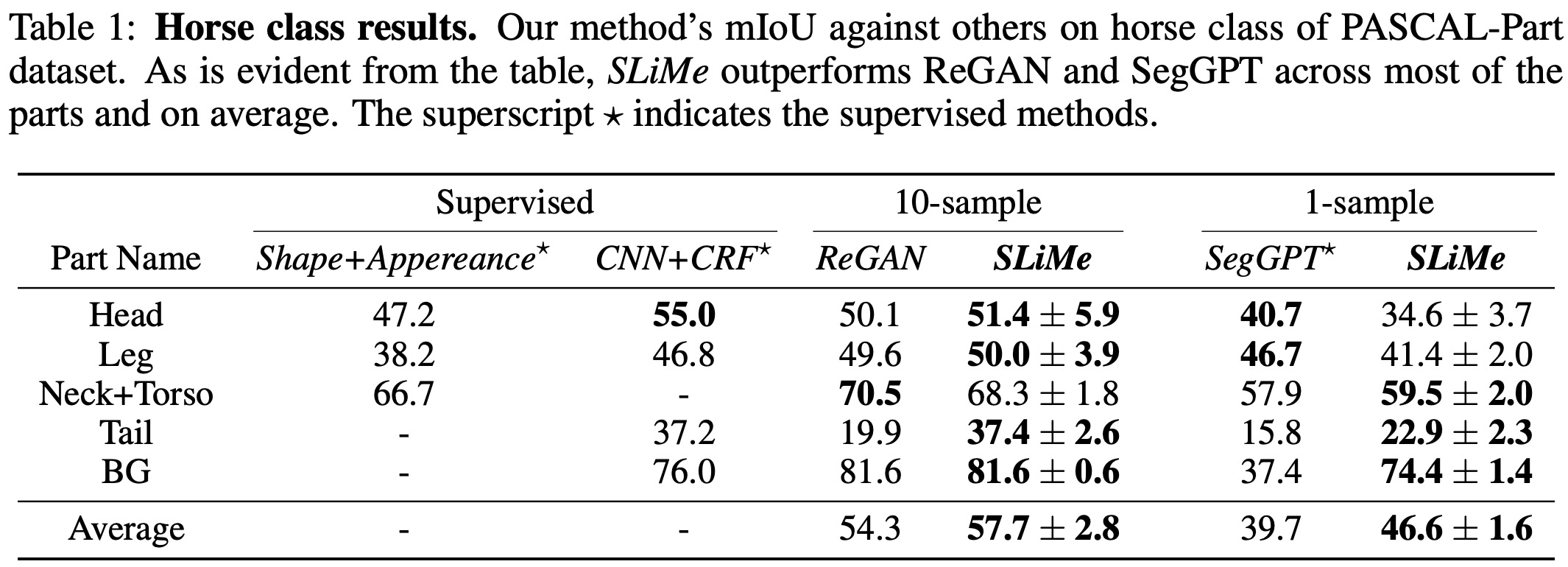
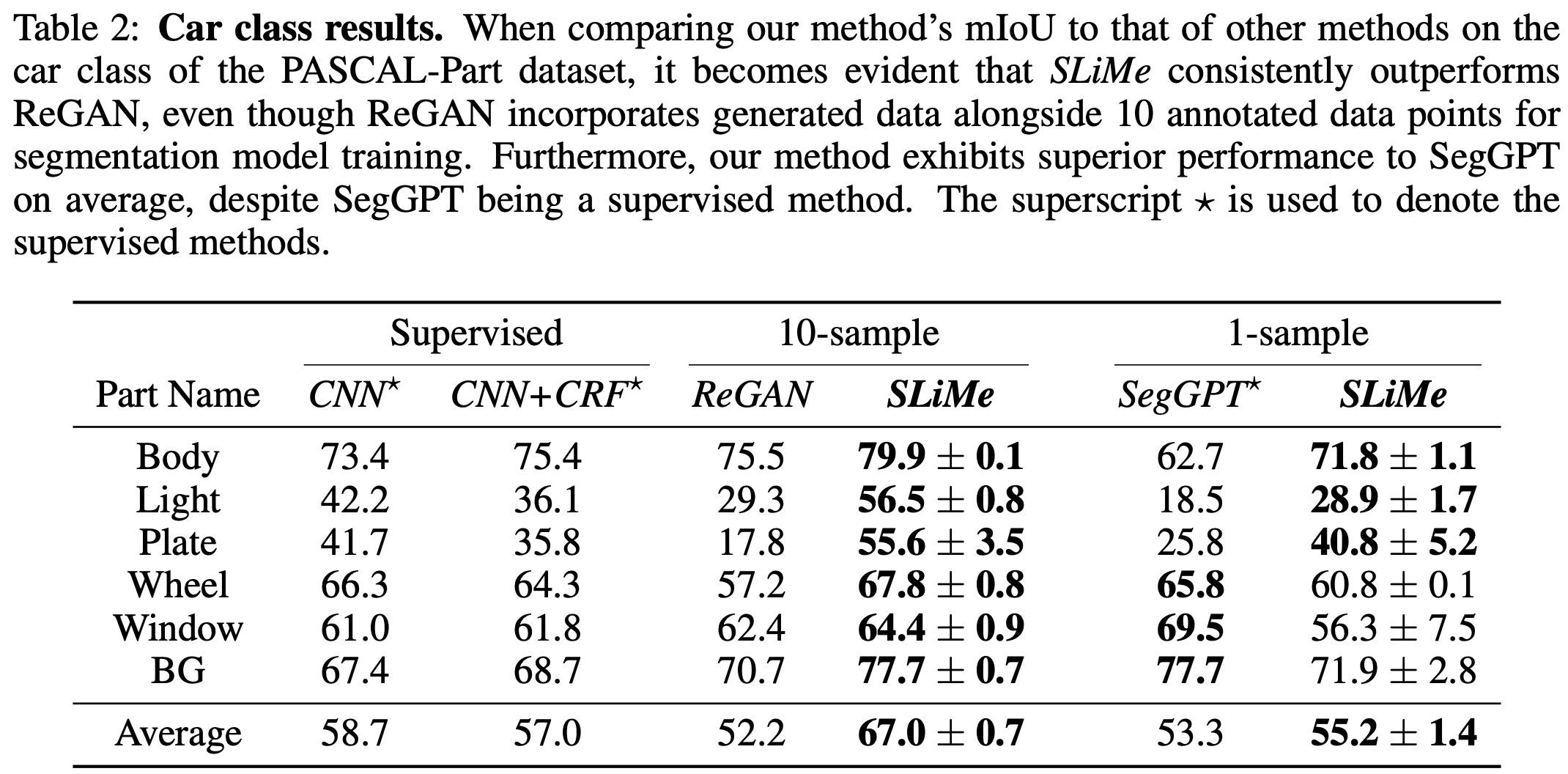




The PASCAL-PART dataset is designed for object parsing and semantic part segmentation, covering 20 object categories. SLiMe consistently outperformed both ReGAN and SegGPT in multiple settings. Specifically, SLiMe performed better than ReGAN for all segments except the horse’s neck+torso, and it outperformed SegGPT for most parts in a 1-sample setting. Similar results were observed for the car class. Notably, while SegGPT requires a significant training set, SLiMe is a genuine one-shot method, requiring just a single training sample.
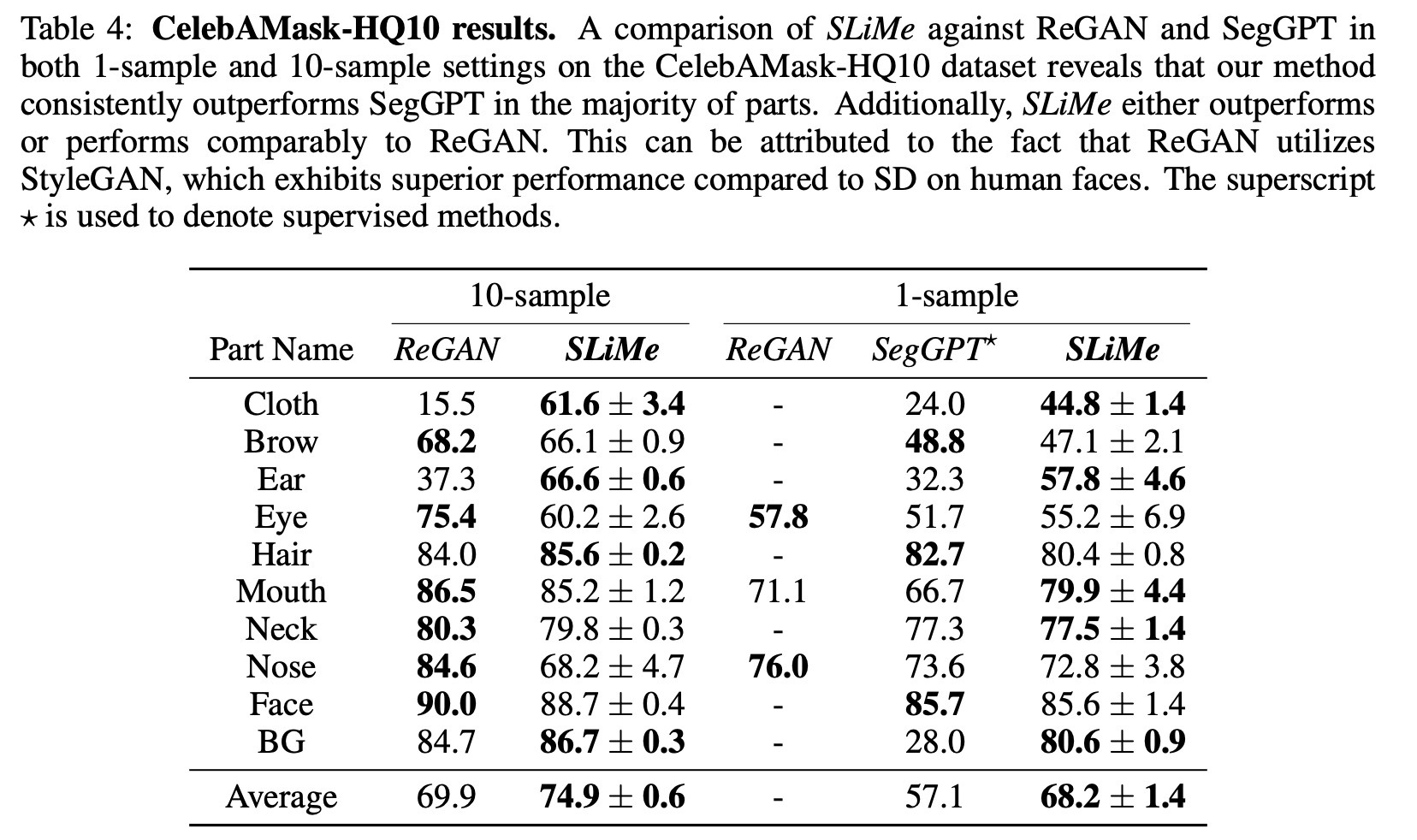
The CelebAMask-HQ dataset, designed for facial segmentation in computer vision, contains over 30,000 high-resolution celebrity images annotated for 19 facial attributes. The SegDDPM method offers few-shot segmentation using UNet features within a trained DDPM. Comparing SLiMe with SegDDPM on CelebAMask-HQ19, it was found that SLiMe performs better on average. When assessing against ReGAN using CelebAMask-HQ10, SLiMe exceeded ReGAN’s performance on average for certain settings and segments. The variances in performance are attributed to ReGAN’s use of StyleGAN, which excels in human face rendering. Unlike ReGAN, SLiMe offers more general applicability without needing class-specific pre-training, exemplified by its ability to segment objects like turtles.
paperreview deeplearning cv imagesegmentation fewshotlearning