Paper Review: Transformer Reasoning Network for Image-Text Matching and Retrieval
Paper link Code link (PyTorch, there are pre-trained models)
A new approach for image-text matching: at first, images and texts go into separate inputs, but later transformer layers share weights. This allows to extract better features and reach new SOTA results on COCO for this task.
The architecture is Faster-RCNN Bottom-Up + BERT.
I’m not sure if it is really novel and good - it seems authors simply combined two big pre-trained models, added some tricks, and got a marginal improvement. Still, the concept is quite interesting.
The usual approaches to image-text matching consist of using separate models to extract the image and text features. The embeddings are projected into a common representation space so that they can be compared, for example, by cosine similarity.
But usually, features extracted by CNN capture only capture global summarized features of the image, ignoring important localized details. They can’t understand what the object is, so it is difficult to compare it to the text query.
Some approaches try to learn a scoring function measuring the affinity between an image and a caption. But the downside is that they can’t produce separate features for images and texts - only for the pair. So it isn’t feasible to use this approach in the real-time ranking.
Authors suggest an architecture where images and texts are processed at first, and then their representations are combined.
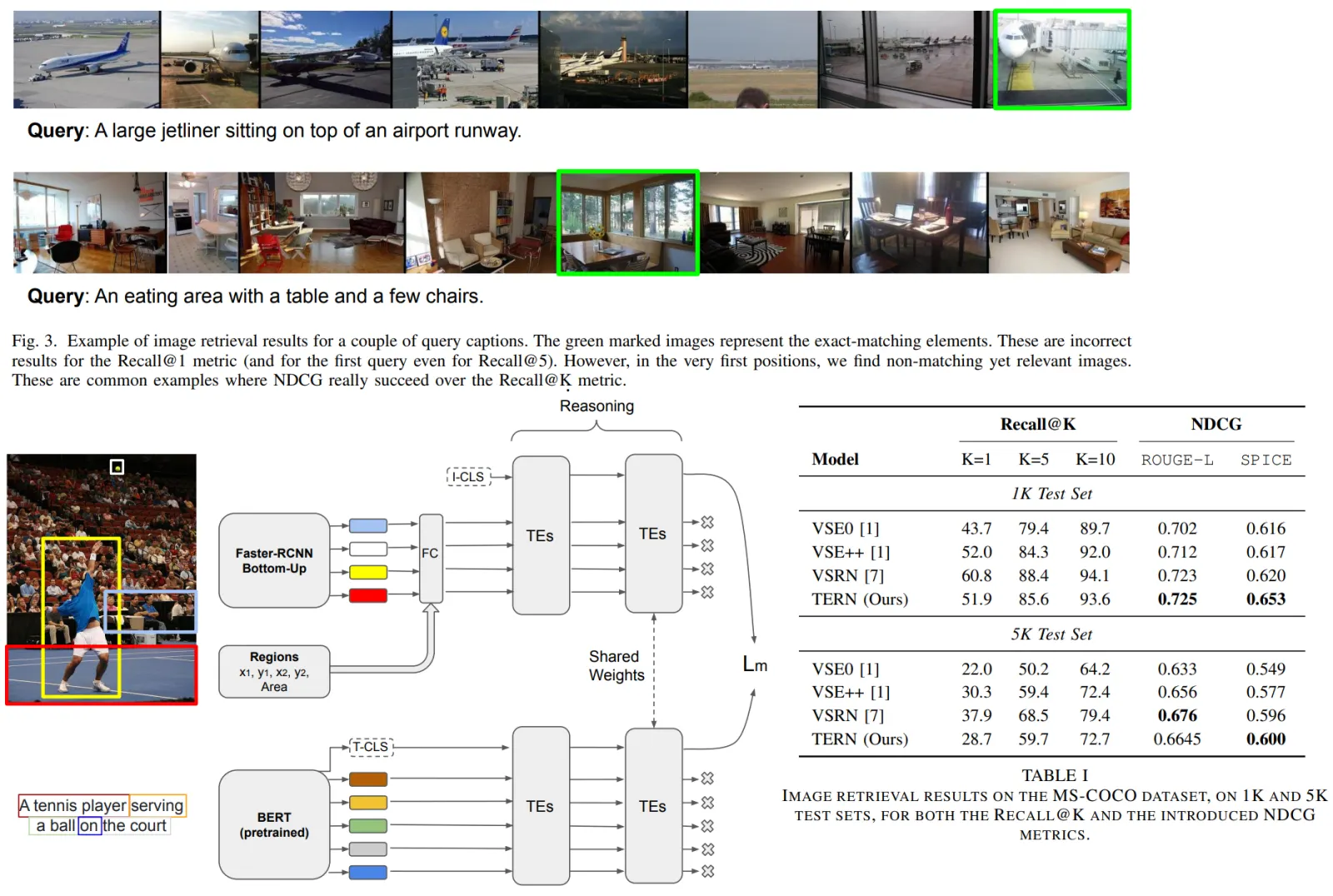
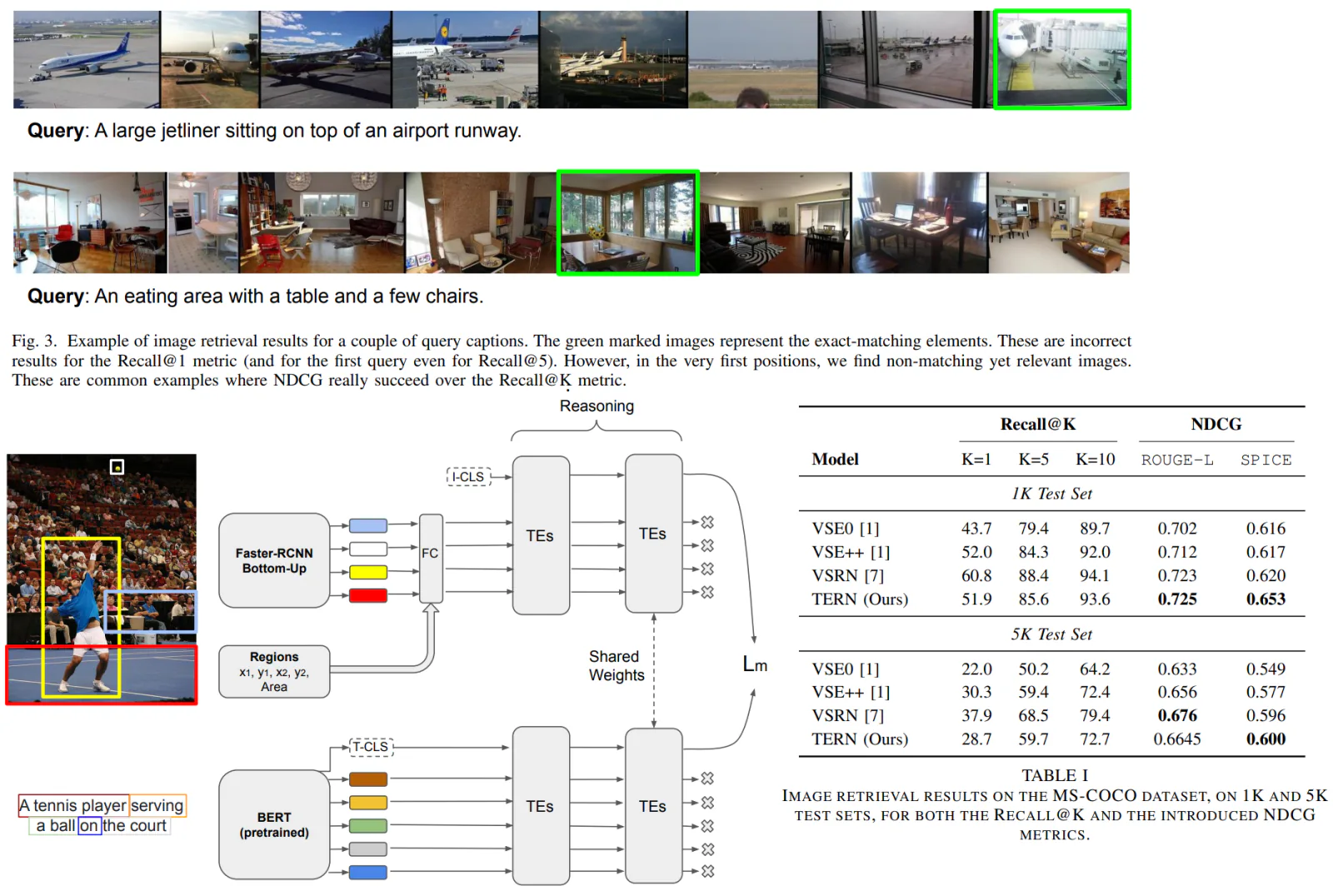
A common metric for this task is Recall@K, but authors think it is too rigid, so they offer to use NDCG.
The main contributions are the following:
- TERN Architecture
- NDCG metric
- show SOTA result on a benchmark
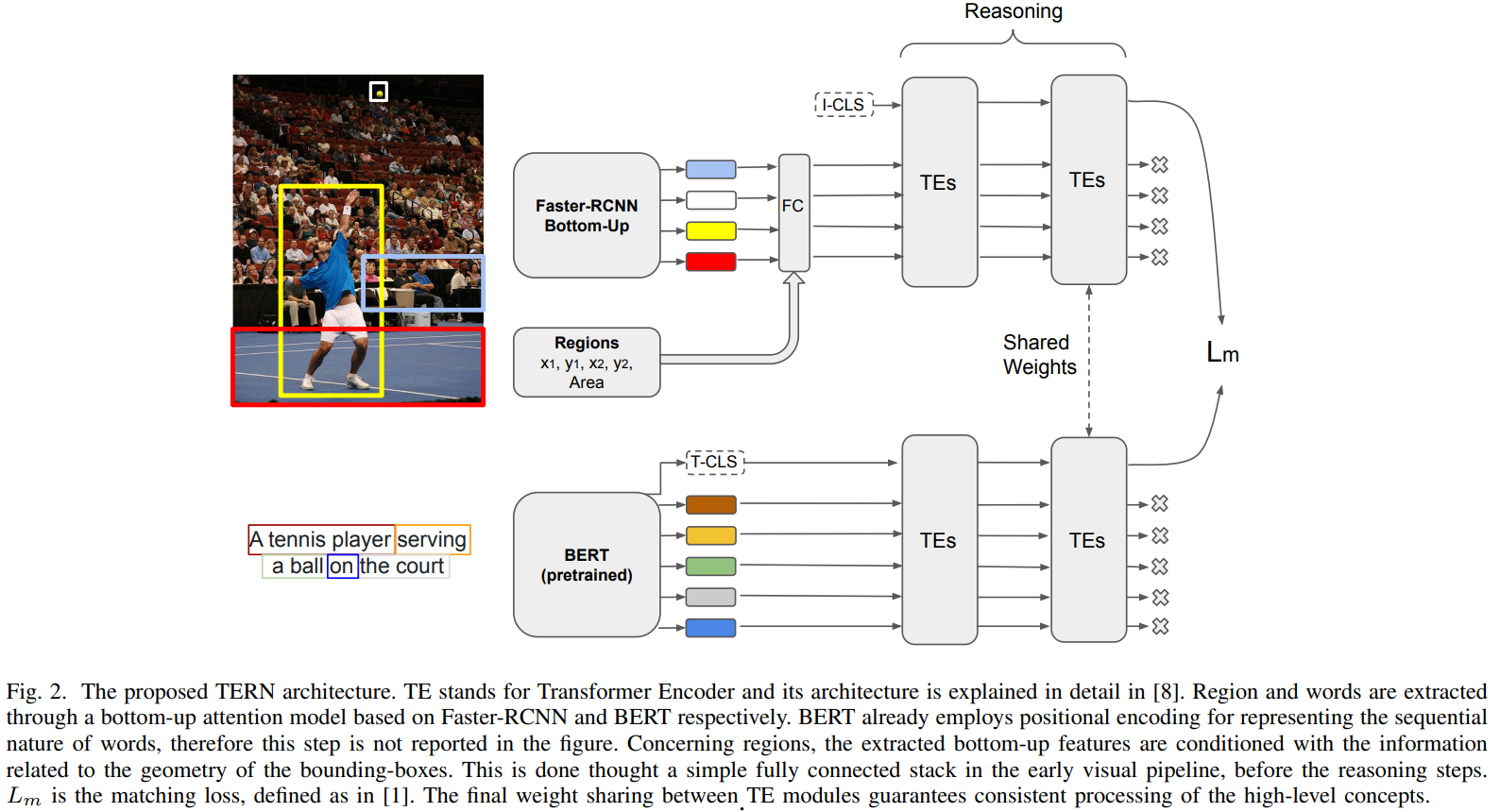
The Architecture
Two inputs:
- extract word embeddings from text using BERT
- extract image regions from Faster-RCNN with Resnet-101 backbone. Add geometry of bounding boxes
The aim is to produce representations of regions and words so that they can be used in downstream tasks. Authors use ideas from BERT: they add a special token (I-CLS, T-CLS) at the beginning of regions set and words sequence.
In the last layers of TERN, the representations should be comparable, so we can use shared weights.
The Loss
Hinge-based triplet ranking loss
They use standard cosine similarity; hard negatives are mined from the mini-batch for performance.
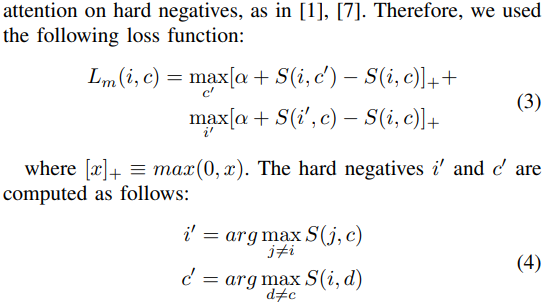
The Experiments
The dataset used is MS-COCO. 113287 train, 5000 valid, 5000 test.
Metrics are ROGUE-L and SPICE. ROGUE-L operates on the longest common sub-sequences; SPICE has some robustness to synonyms and is more sensitive to high-level features of the text and semantic dependencies between words and concepts.
Training
Word embeddings are extracted using BERT from Hugging Face; the dimension is 768.
Image embeddings are extracted using pre-trained models from this repo: https://github.com/peteanderson80/bottom-up-attention dimension is 2048.
For experiments, only the top 36 detections for each image were used, but the approach could use a variable-length set of regions by masking attention weights.
Training is done for 30 epochs with Adam, batch size 90. Nothing said about the speed of training or inference.
The results are quite good.
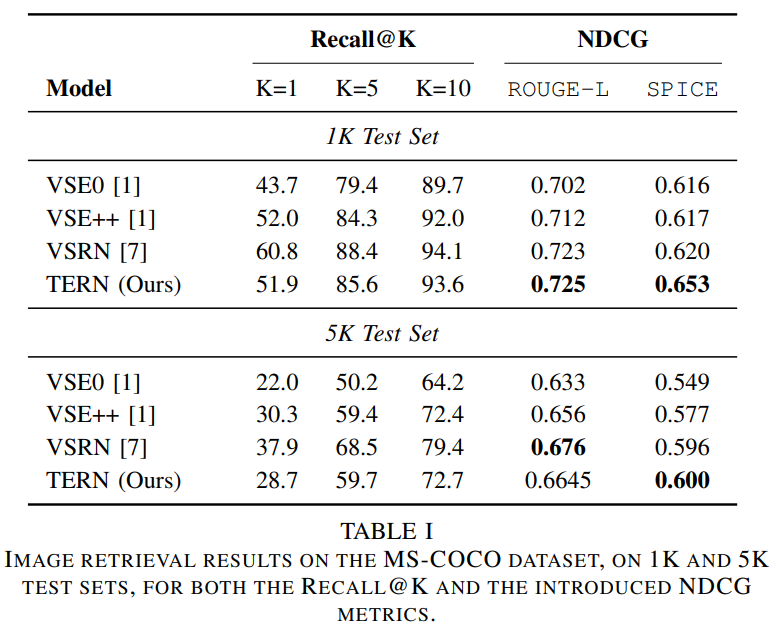
TERN is worse than VSRN in Recall@K but better in NDCG; this means the model is better in cases when users ask for relevant but not exactly matching images.
paperreview transformer cv imagetextmatching multimodal