Paper Review: Video-T1: Test-Time Scaling for Video Generation
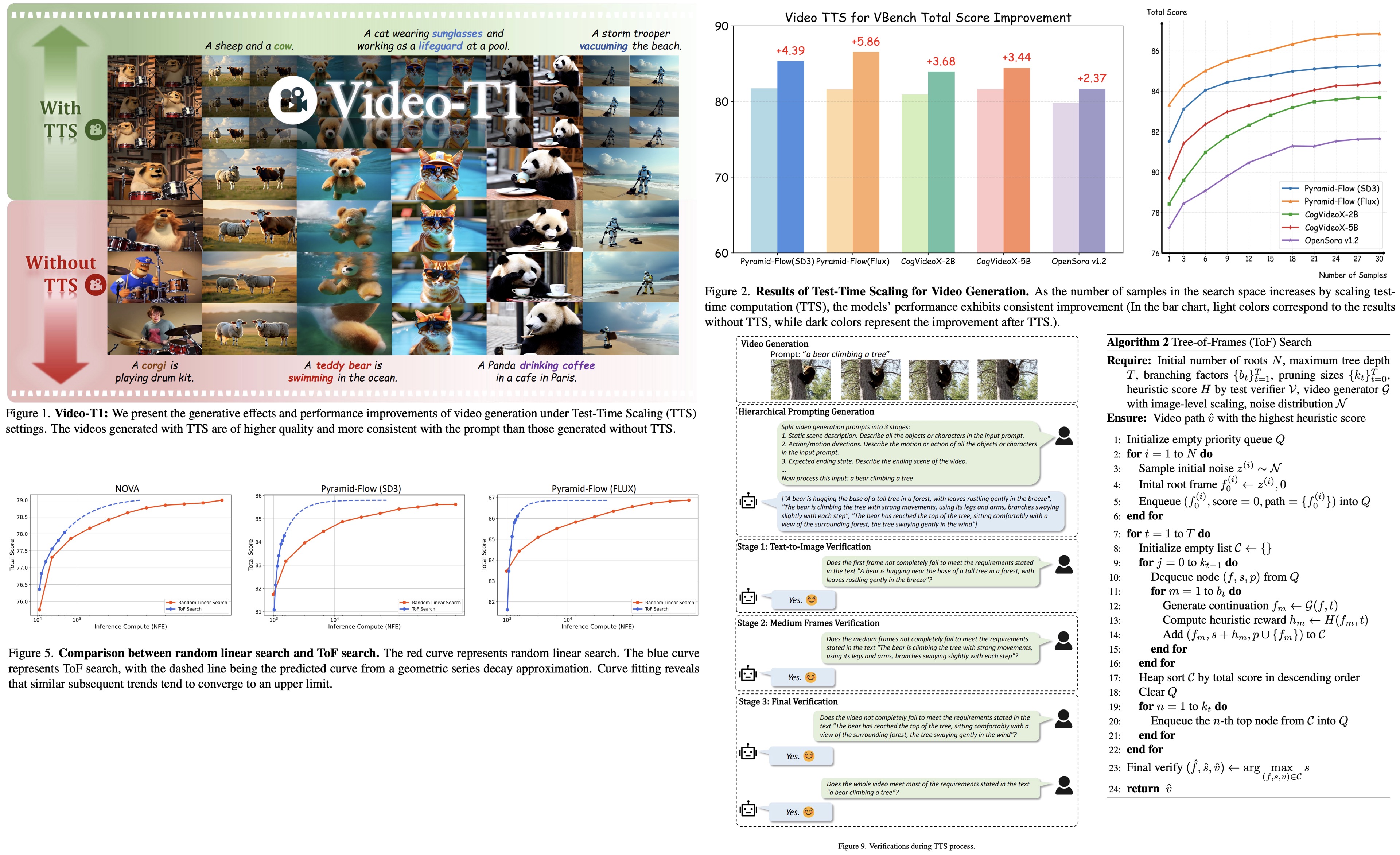
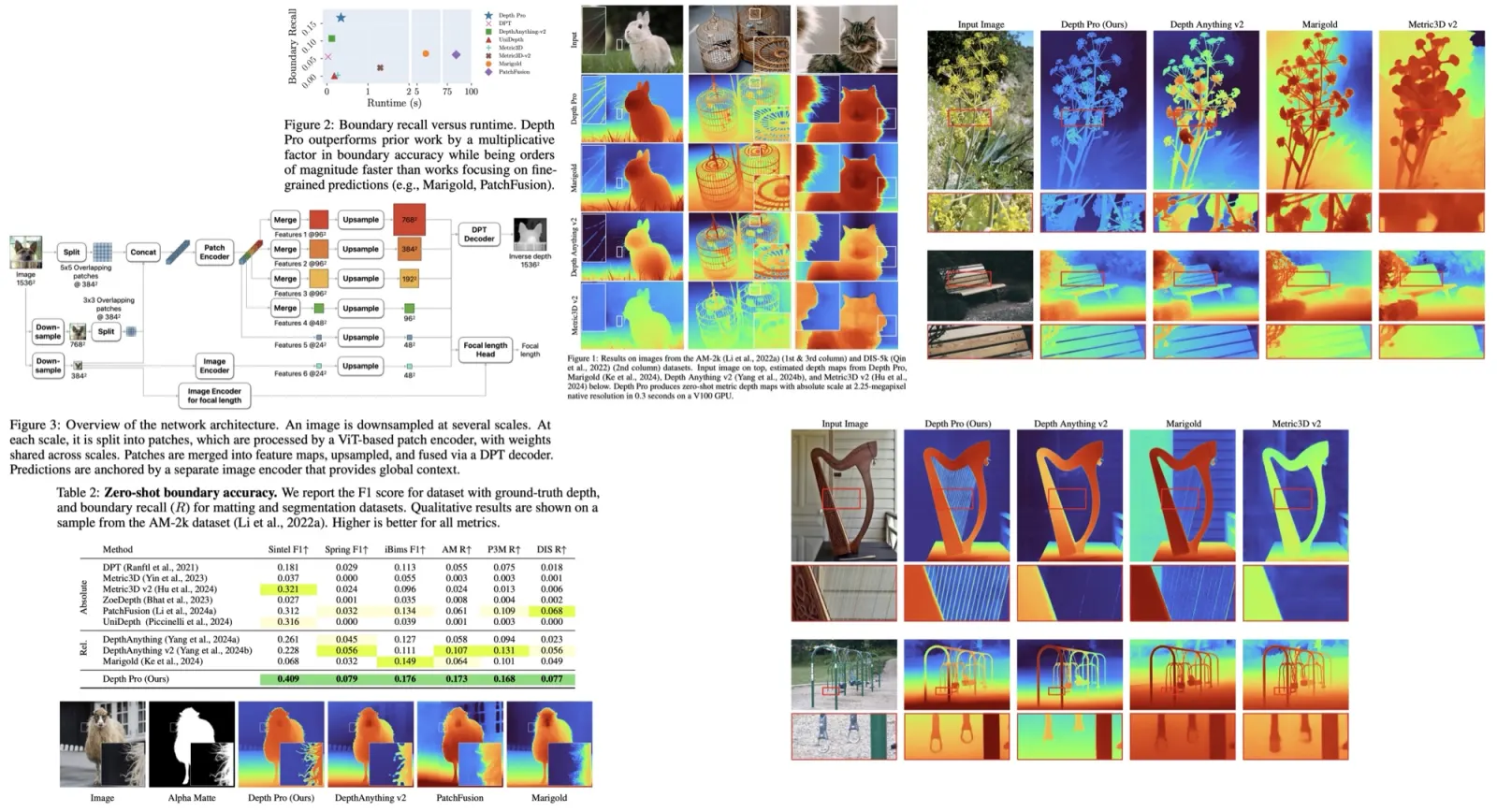
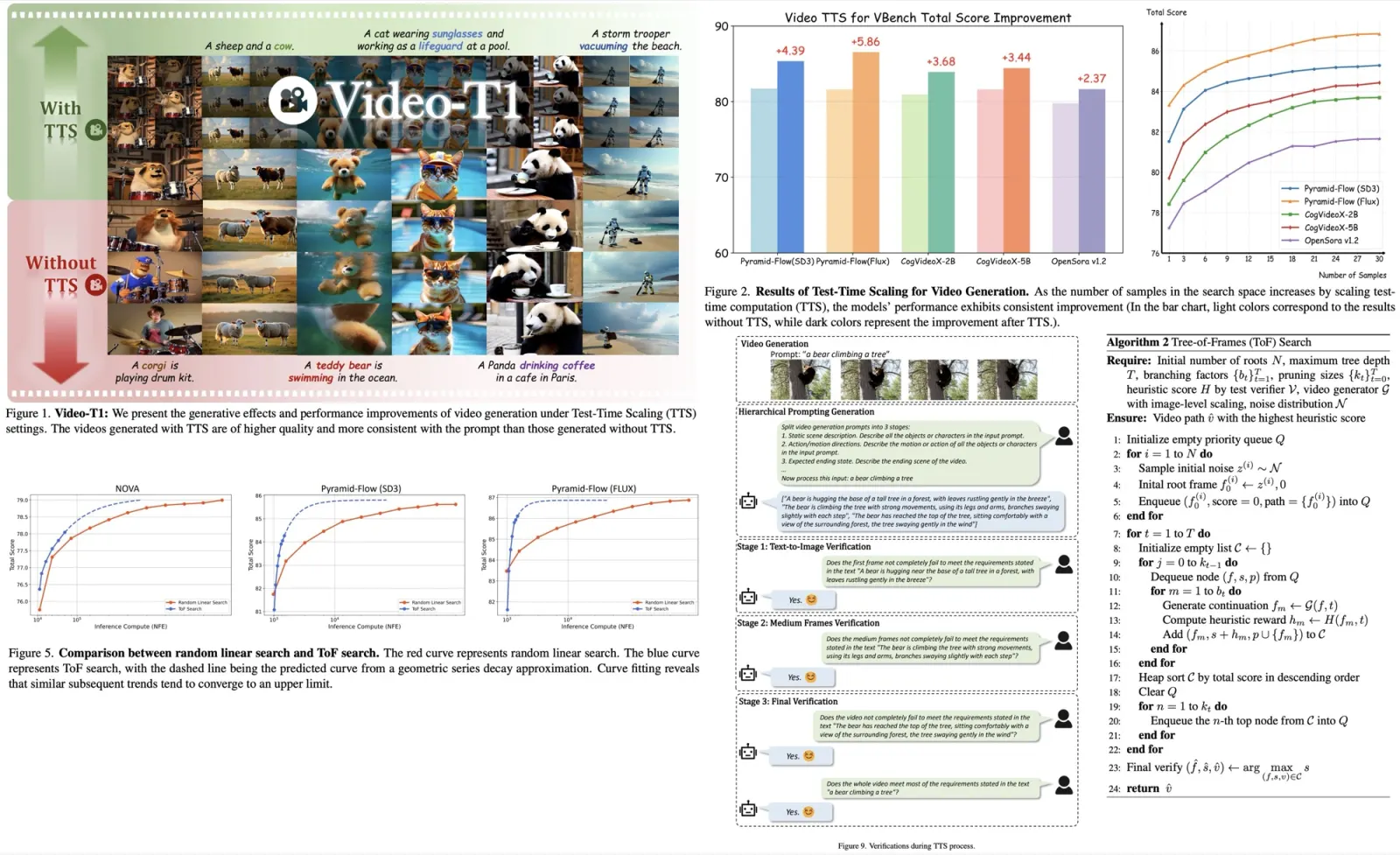
The authors explore using Test-Time Scaling to improve text-to-video generation by increasing inference-time computation instead of training costs. They frame video generation as a search problem, guided by verifiers and heuristics. There are two strategies: linear search with more noise samples and Tree-of-Frames, an autoregressive method that adaptively expands and prunes frame branches. The experiments demonstrate that higher test-time compute consistently enhances video quality.
The approach
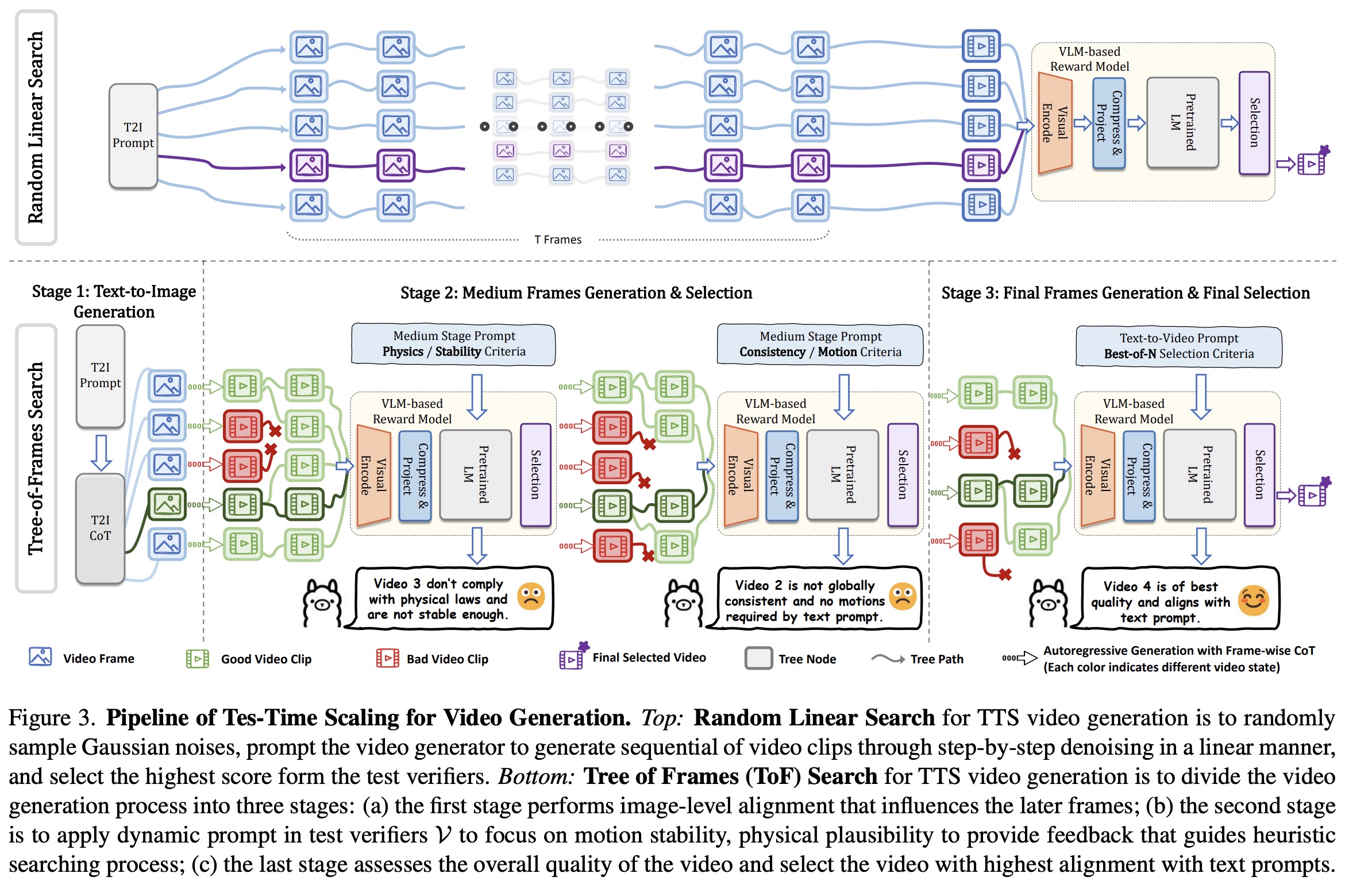
How to Scale Video Generation at Test Time
Test-Time Scaling in video generation faces unique challenges compared to LLMs, such as the need for both spatial quality and temporal consistency, due to the nature of video as a sequence of frames, and the use of multi-step diffusion models that complicated direct scaling. To address this, video generation is reinterpreted as a path-search problem: finding optimal trajectories from Gaussian noise to high-quality videos by increasing computation at inference.
The framework consists of three components:
- Video Generator produces videos from text prompts using diffusion.
- Test Verifier evaluates video quality with respect to the text prompt.
- Heuristic Search Algorithm guides the search through initial noise samples to select the best video path.
Random Linear Search

Random linear search is a simple TTS method where multiple Gaussian noise samples are fully denoised into video sequences, and the best one is selected based on verifier scores. It scales linearly with the number of samples.
This approach treats each sample as an independent degenerate tree (each non-leaf node has exactly one child) of T steps, forming a forest of N trees. While easy to implement, it has two key limitations: inefficiency due to exhaustive traversal without optimization and lack of interaction between samples, leading to more randomness and slower scaling.
Tree-of-Frames Search

Instead of fully generating and evaluating entire videos from multiple noise samples, ToF uses autoregressive, stage-wise generation guided by test verifiers, reducing computational costs while improving video quality. It consists of three stages:
- Initial frame generation with a focus on strong alignment with the text prompt (e.g., color, layout).
- Intermediate frame generation taking into account subject consistency, motion stability, and realism.
- Evaluation of the overall quality and prompt alignment.
ToF uses three core techniques:
- Image-level alignment: Frames are evaluated progressively during denoising, enabling early rejection of low-quality candidates and focusing compute on promising ones.
- Hierarchical prompting: Different prompts are extracted at different stages to ensure temporal coherence and semantic alignment.
- Heuristic pruning: A dynamic search tree is built from noise samples, expanding and pruning branches at each step based on quality scores.
Though worst-case time complexity remains the same, selective branching reduces it significantly (O(TN) -> O(N + T)).
Experiments
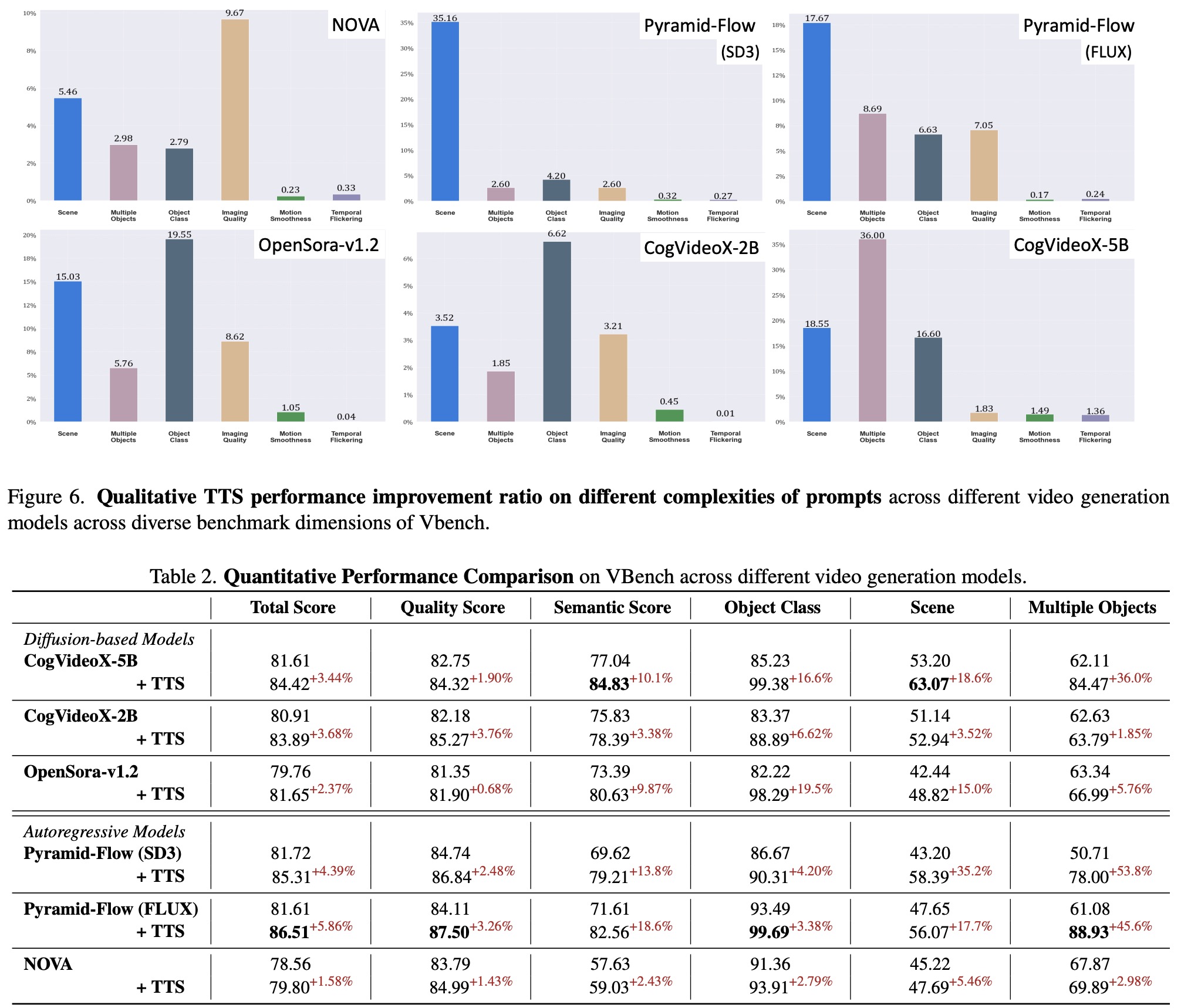
Test-Time Scaling consistently improves video generation quality across various models and verifiers. Performance increases with higher inference budgets, though gains eventually plateau. Different verifiers emphasize different aspects of video quality, and combining multiple verifiers further boosts results by reducing bias.
Larger models benefit more from TTS due to their greater capacity to explore the search space, while smaller models show limited improvement. Tree-of-Frames proves significantly more efficient than random linear search.
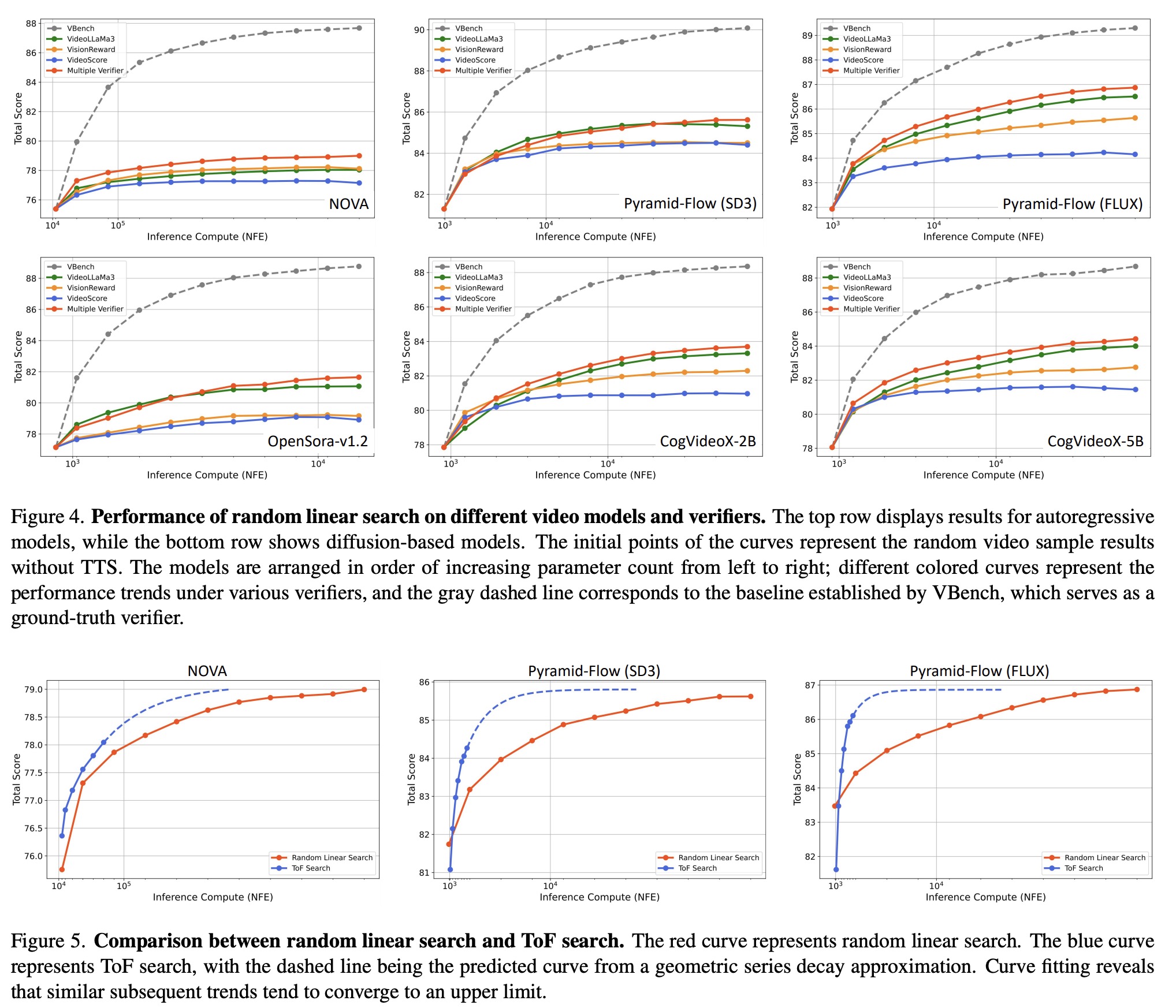
TTS enhances performance across most evaluation dimensions - especially for common, easily assessable prompts like scenes, objects, and image quality. However, improvements are challenging for complex temporal properties like motion smoothness and flickering, which remain challenging for current models.
paperreview deeplearning cv