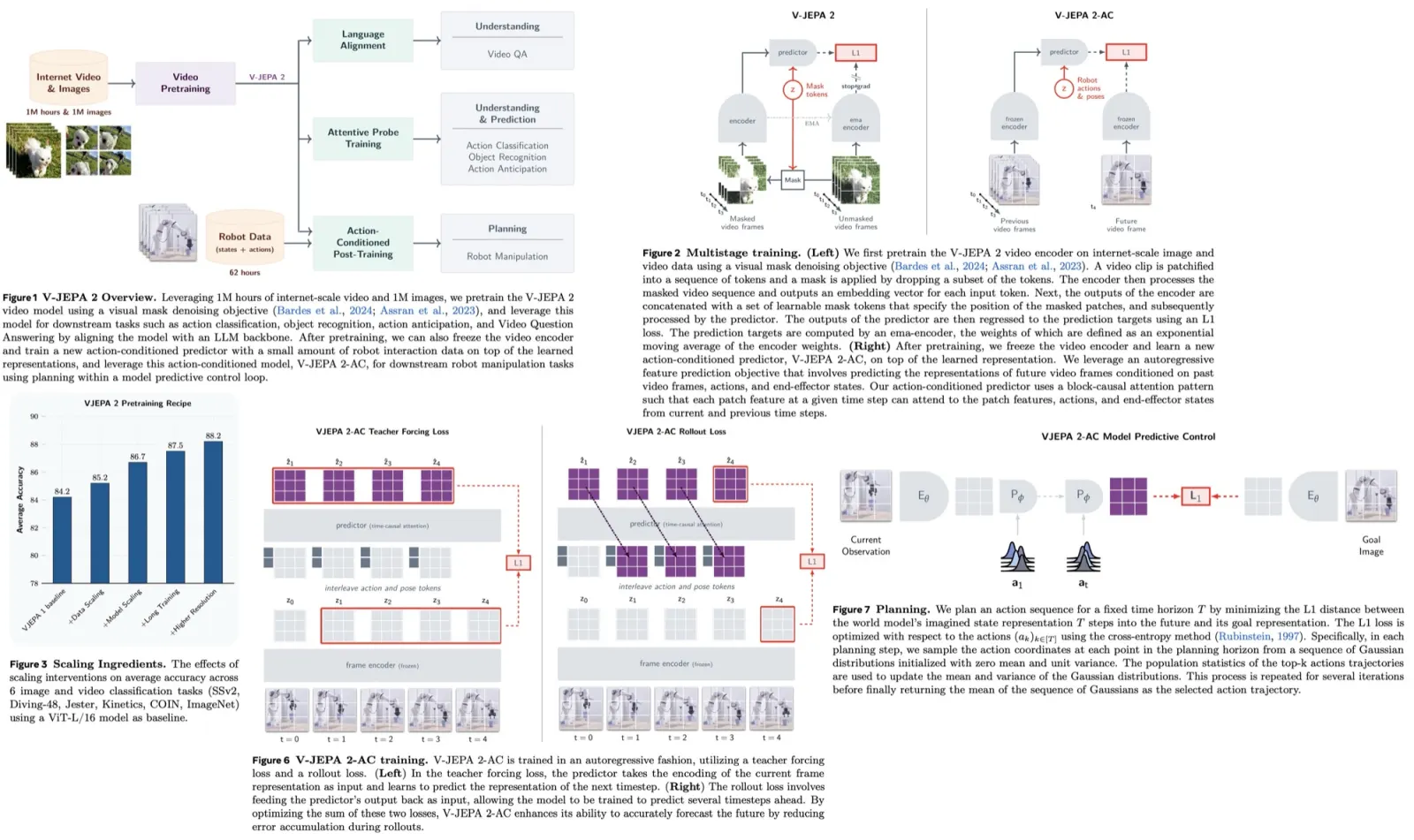
Paper Review: V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
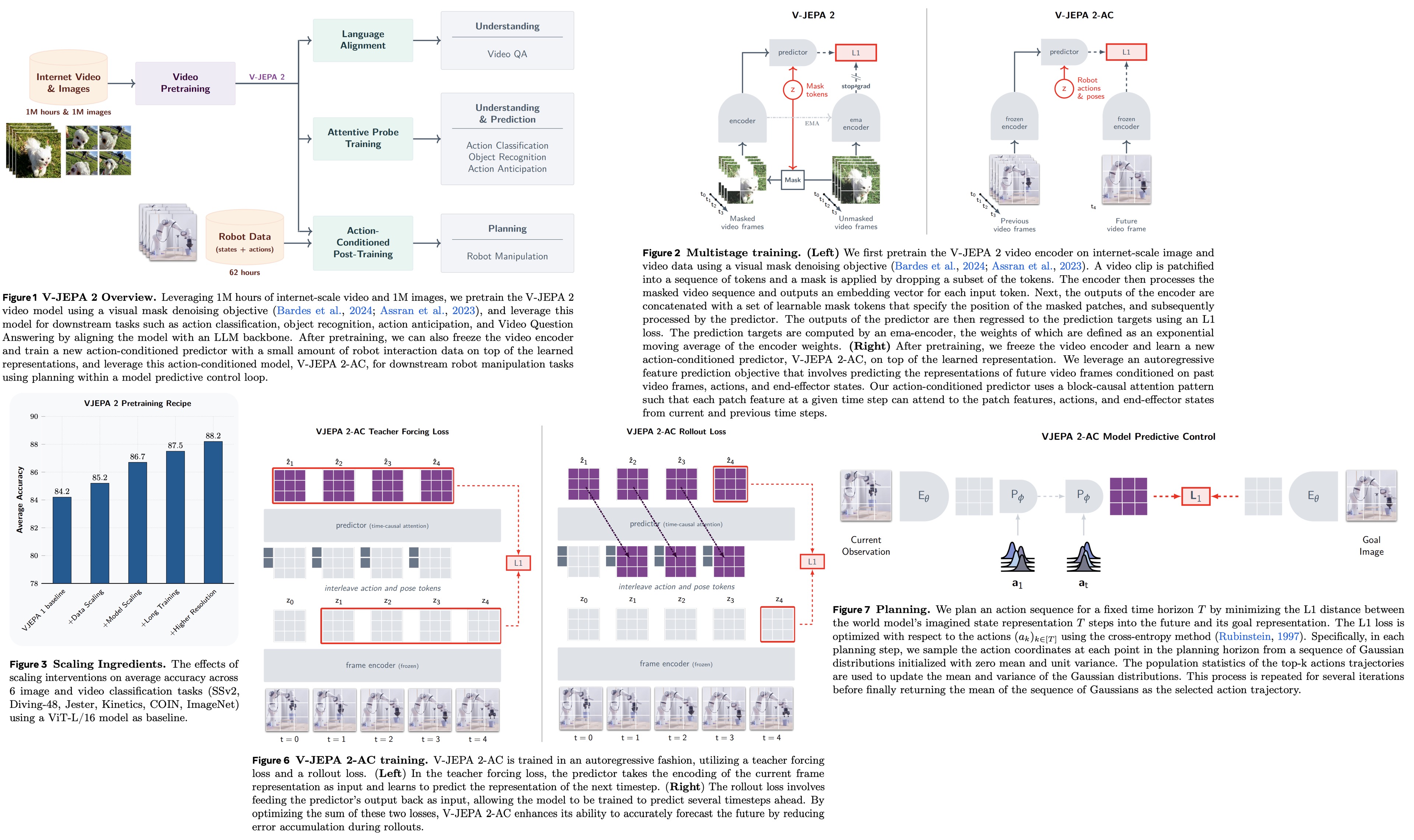
V-JEPA 2 is a self-supervised AI model trained on over 1 million hours of internet video and a small amount of robot trajectory data. It achieves 77.3% top-1 accuracy on motion understanding (Something-Something v2), 39.7% recall@5 on human action anticipation (Epic-Kitchens-100), and state-of-the-art video question answering performance after alignment with a large language model. Post-training on less than 62 hours of robot video enables V-JEPA 2-AC to perform zero-shot robotic planning for picking and placing objects using image goals, without task-specific data, training, or rewards. The work demonstrates how large-scale video pretraining, combined with minimal interaction data, can produce a generalizable world model for physical planning.
V-JEPA 2: Scaling Self-Supervised Video Pretraining
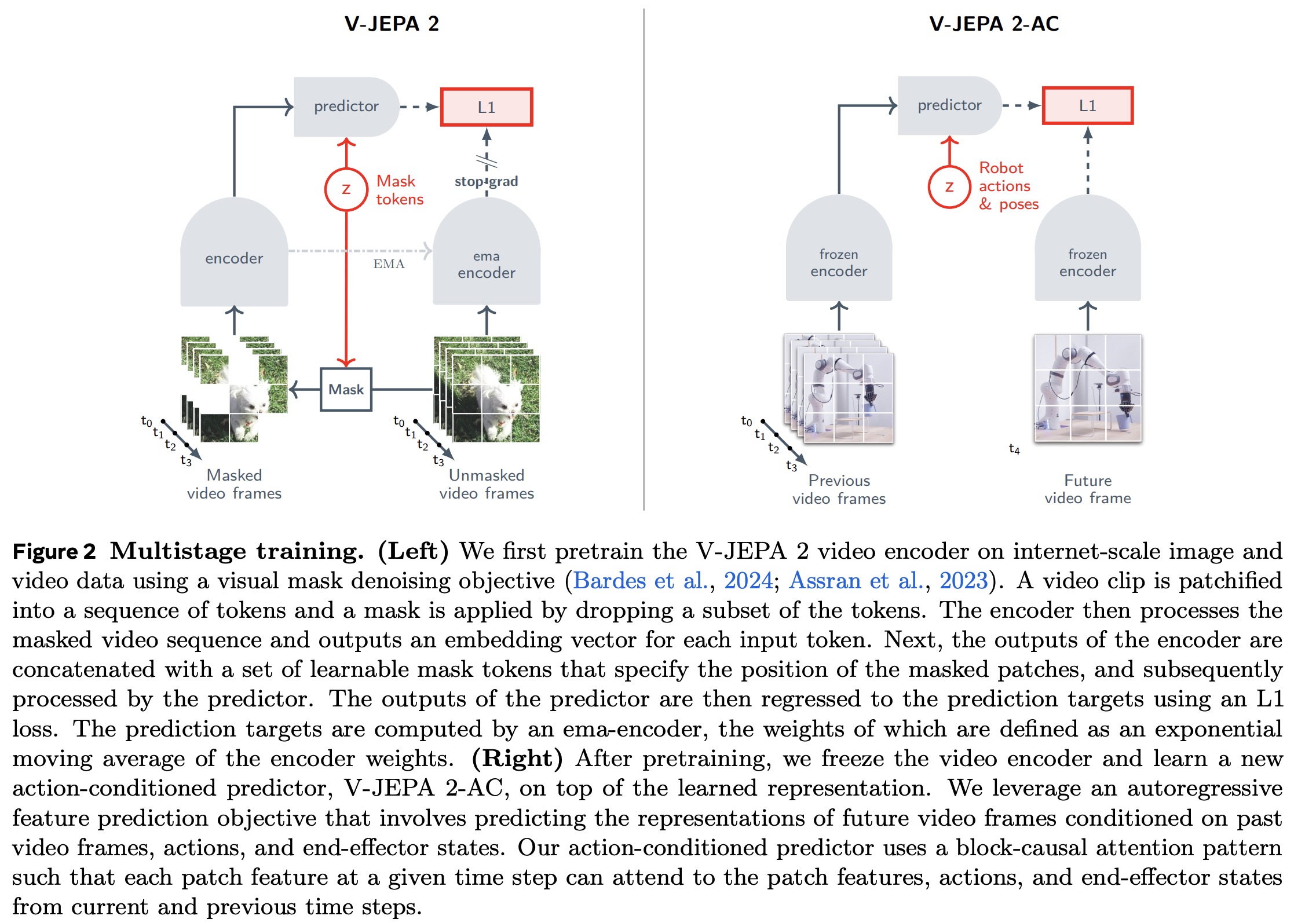
V-JEPA learns by predicting the representation of masked parts of a video from the unmasked parts. It uses an encoder (a vision transformer with 3D rotary position embeddings) to extract video representations and a predictor to estimate masked patch representations. Training minimizes the L1 loss between the predicted and actual representations of masked patches, using stop-gradient and exponential moving average to avoid collapse.
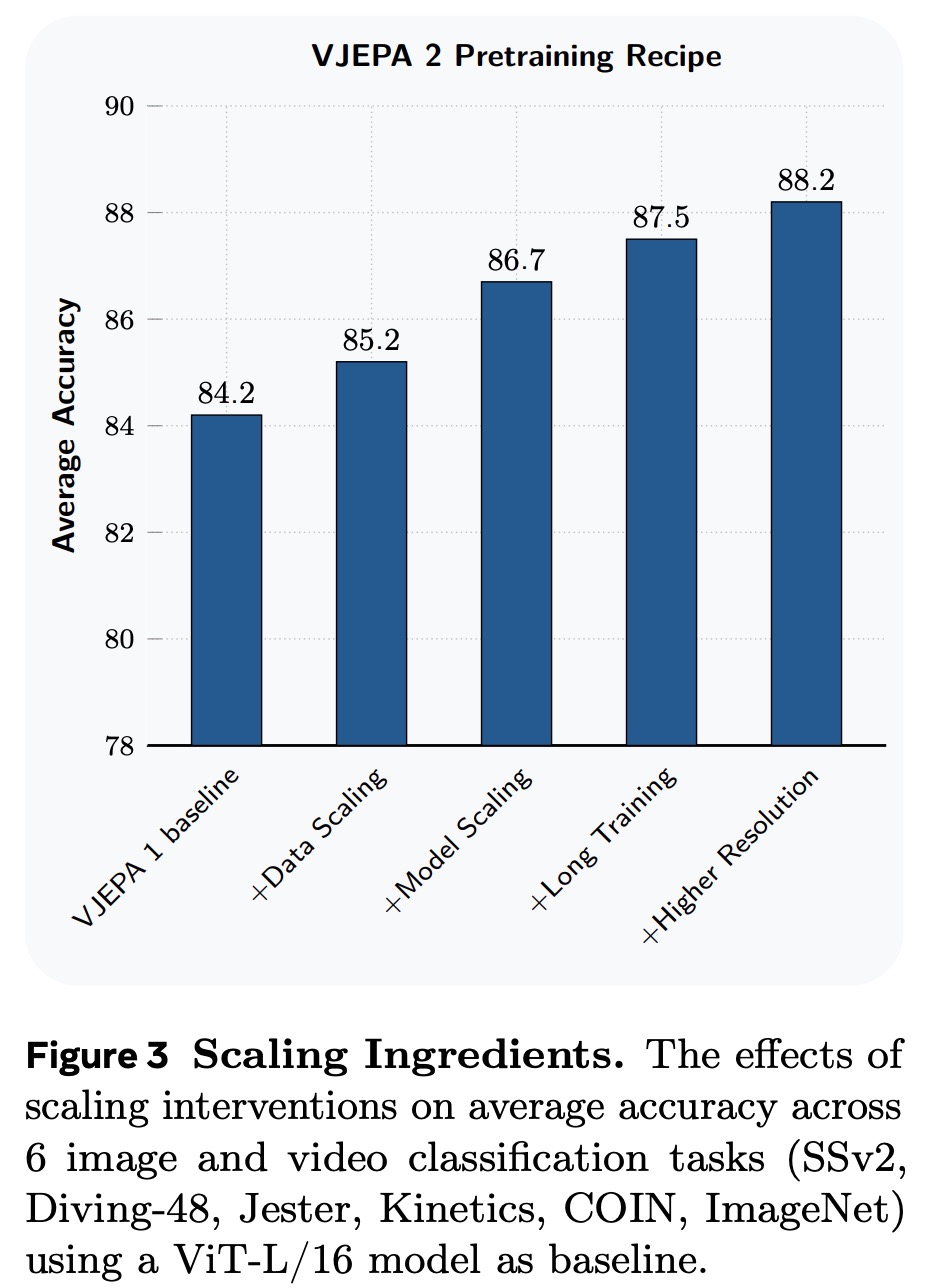
V-JEPA 2 scales this approach through larger datasets (22 million videos), larger models (up to 1 billion parameters, ViT-g), longer training (252k iterations with a warmup-constant-decay schedule), and higher-resolution video clips. Performance is evaluated by freezing the encoder and training small probes on six motion and appearance classification tasks, focusing on average accuracy across these benchmarks.
V-JEPA 2-AC: Learning an Action-Conditioned World Model
V-JEPA 2 is extended for planning by adding an action-conditioned predictor trained on a small set of robot interaction data from the Droid dataset. This predictor learns to model the causal effects of actions using data from the teleoperated Franka Panda robot arms. The resulting model, V-JEPA 2-AC, builds on the frozen V-JEPA 2 encoder and enables model-predictive control for planning actions in new environments.
Action-Conditioned World Model Training
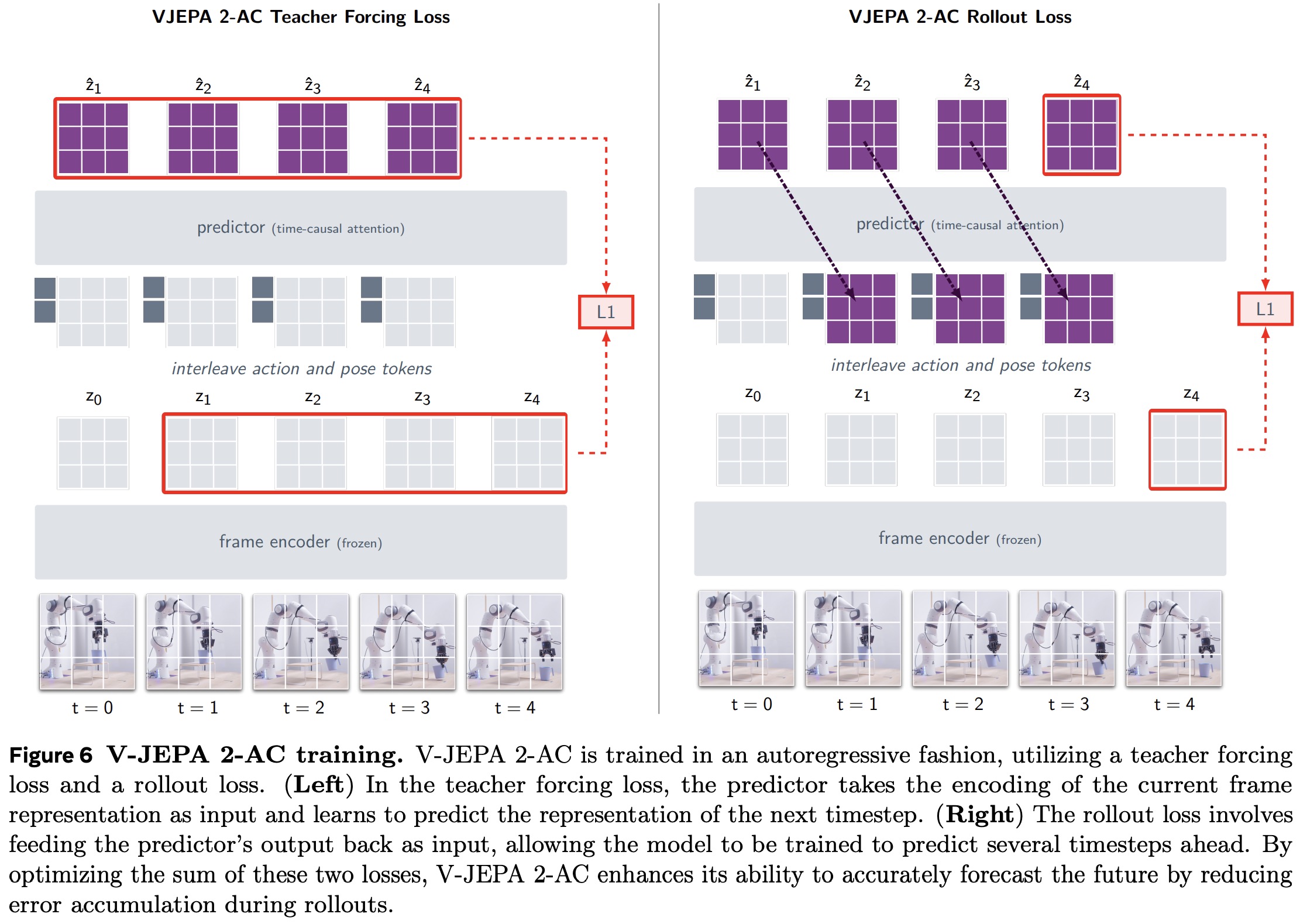
V-JEPA 2-AC is trained as a latent world model for controlling a robotic arm through closed-loop model-predictive control. It learns from about 62 hours of unlabeled video from the Droid dataset, where each frame includes a 7D end-effector state (position, orientation, gripper state). Control actions are defined as changes in end-effector state between frames. Video clips are 4 seconds long, at 256×256 resolution and 4 fps, yielding 16-frame sequences. The model predicts future video representations conditioned on control actions and proprioception.
The frozen V-JEPA 2 encoder generates per-frame feature maps (16×16×1408), which are combined with action and end-effector state tokens. A 300M parameter transformer predictor with 24 layers and 16 heads predicts future feature maps autoregressively. The predictor uses 3D rotary position embeddings for video patches and temporal rotary embeddings for actions and poses, with block-causal attention to model causal dependencies over time. Training minimizes a combination of teacher-forcing loss (predicting the next frame representation) and a rollout loss (multi-step prediction). The model learns to predict future visual states from actions without task labels, rewards, or success indicators, allowing planning to be based solely on raw video and control signals.
Inferring Actions by Planning
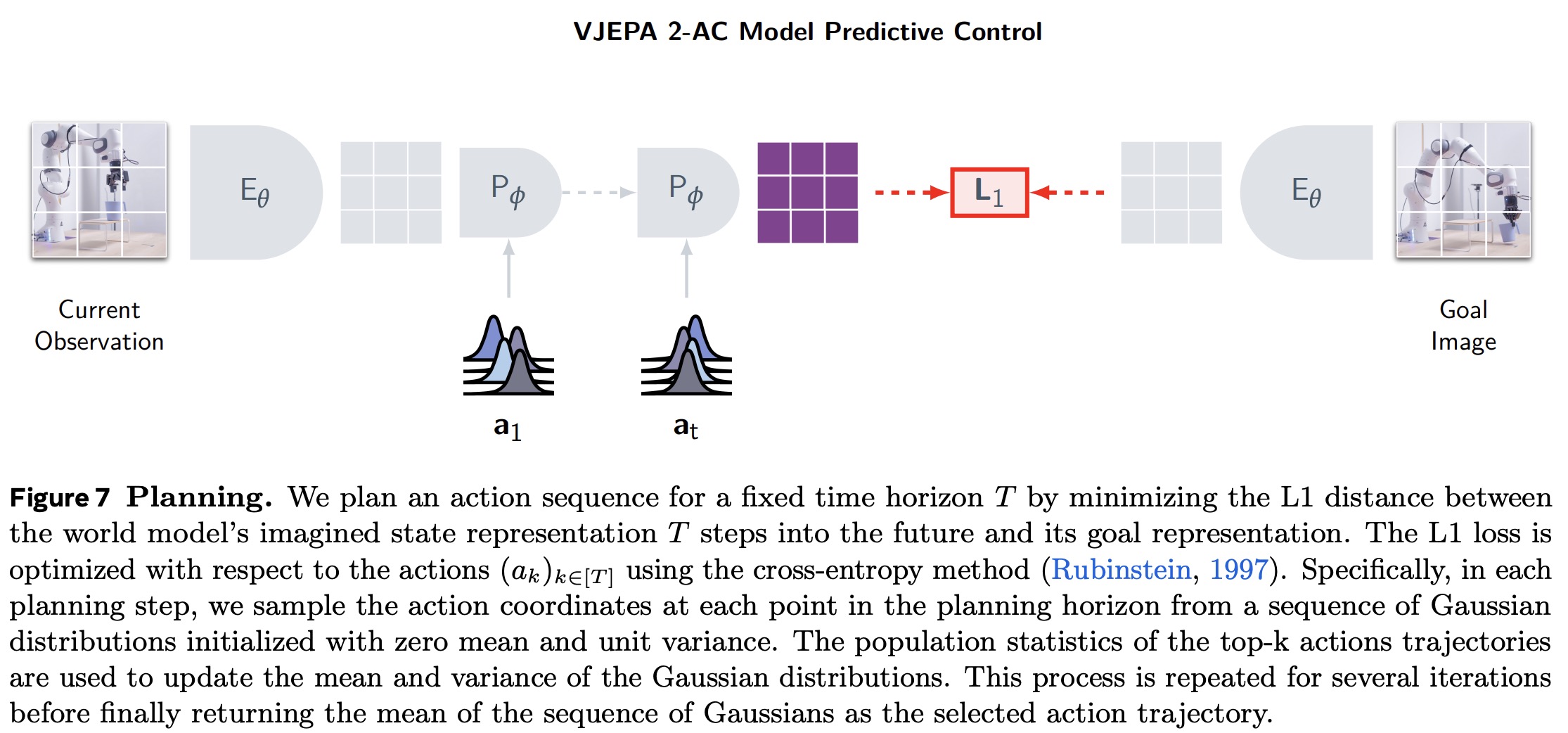
V-JEPA 2-AC is used for planning by minimizing a goal-conditioned energy function. At each time step, the model plans a sequence of actions over a fixed horizon that drives the predicted future state close to a goal image. The current frame and goal image are encoded into feature maps, and the model predicts how the state evolves given candidate action sequences. The energy function is the L1 distance between the predicted future state and the goal representation. The optimal action sequence minimizes this distance and is found using the Cross-Entropy Method. Only the first action is executed before re-planning in a receding horizon control loop.
Planning: Zero-shot Robot Control
V-JEPA 2-AC is evaluated on single-goal reaching and prehensile manipulation tasks using visual planning from goal images. In single-goal reaching, the model controls a robotic arm to move its end-effector to a target position based on a goal image. It consistently reduces position error to under 4 cm, showing smooth, locally convex energy landscapes that support effective planning without precise sensing.
For object manipulation, tasks include grasping, reaching while holding an object, and pick-and-place. The model uses one or more goal images and plans actions to achieve sub-goals sequentially. Success rates depend on object type, with challenges such as accurately grasping a cup’s rim or adjusting gripper width for a box. V-JEPA 2-AC achieves the highest success across these tasks, demonstrating its ability to compose basic skills like grasping and placing.
Compared to Cosmos (a diffusion-based action-conditioned model), V-JEPA 2-AC delivers higher success rates in all tasks and is significantly faster at planning, requiring about 16 seconds per action versus Cosmos’s 4 minutes. The model’s efficiency and effectiveness highlight the potential of latent planning with self-supervised world models for robotic manipulation.
Limitations
V-JEPA 2-AC’s performance is sensitive to camera positioning because it learns action coordinates from monocular RGB input without explicit calibration. When the robot base isn’t visible, inferring action axes becomes ambiguous, causing model errors. The team manually adjusted camera positions to find a setup that worked reliably.
Long-horizon planning is challenging due to error accumulation in autoregressive predictions and the exponential growth of the action search space, making it computationally difficult.
The model currently relies on image goals for planning, as in prior work, but real-world applications could benefit from specifying goals using language. Future work aims to align these world models with language models for more flexible, natural task specification.
Understanding: Probe-based Classification
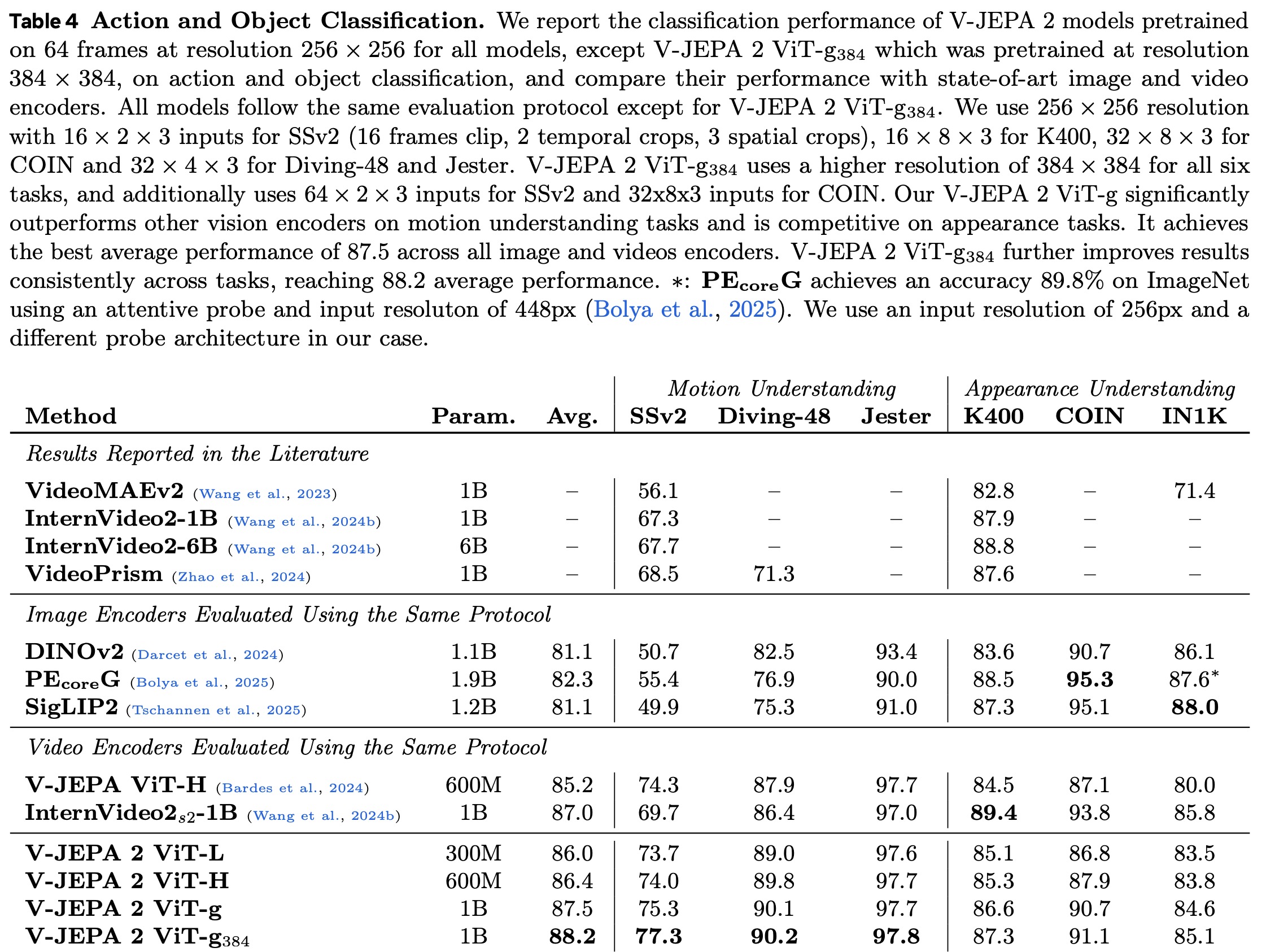
V-JEPA 2 was evaluated on both motion and appearance understanding tasks to assess the strength of its learned representations. Motion tasks require understanding gestures and movements across frames, while appearance tasks focus on recognizing objects, actions, and scenes from single frames.
Using a frozen encoder and a 4-layer attentive probe for classification, V-JEPA 2 outperformed other state-of-the-art encoders on motion tasks, achieving 75.3% top-1 accuracy on Something-Something v2 compared to 69.7% for InternVideo and 55.4% for PECoreG. It was also competitive on appearance tasks, scoring 84.6% on ImageNet, a 4.6-point improvement over its predecessor. Overall, V-JEPA 2 achieved the best average performance across all six tasks.
Prediction: Probe-based Action Anticipation

V-JEPA 2 was tested on action anticipation using the Epic-Kitchens-100 benchmark, where the goal is to predict the next action (verb and noun) from video context ending 1 second before the action starts. V-JEPA 2 uses a frozen encoder and a predictor to generate future frame representations, which are combined and passed through an attentive probe that predicts action, verb, and noun categories using focal loss.
Results show that V-JEPA 2’s performance improves with model size and resolution. The ViT-L model (300M parameters) achieves 32.7 recall-at-5, while ViT-g (1B parameters) reaches 38.0. The higher-resolution ViT-g384 (384×384) improves further to 39.7 recall-at-5, outperforming PlausiVL (8B parameters) by 12.1 points and achieving a 44% relative improvement.
The model generates coherent alternative predictions in ambiguous contexts but has limitations: it struggles at longer anticipation times, is trained only on kitchen data with a fixed action set, and can fail to predict the exact verb, noun, or both in some cases.
Understanding: Video Question Answering
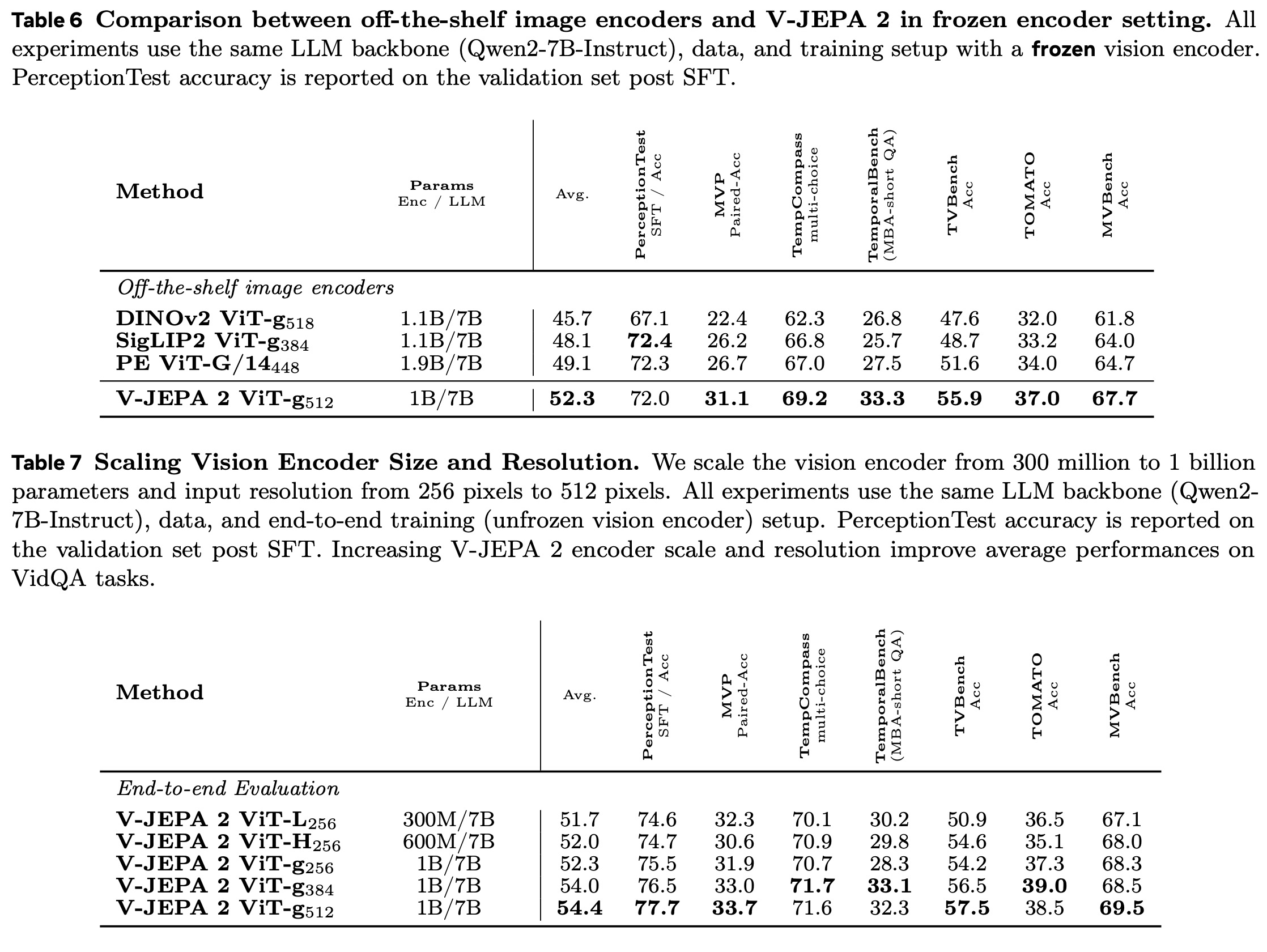
V-JEPA 2 was used as the visual encoder in a multimodal large language model for open-language video question answering. Unlike previous approaches that rely on image encoders pretrained with language supervision, V-JEPA 2 is the first video encoder pretrained without language data to be used in this setting. The MLLM aligns V-JEPA 2’s video representations with a large language model using non-tokenized early fusion.
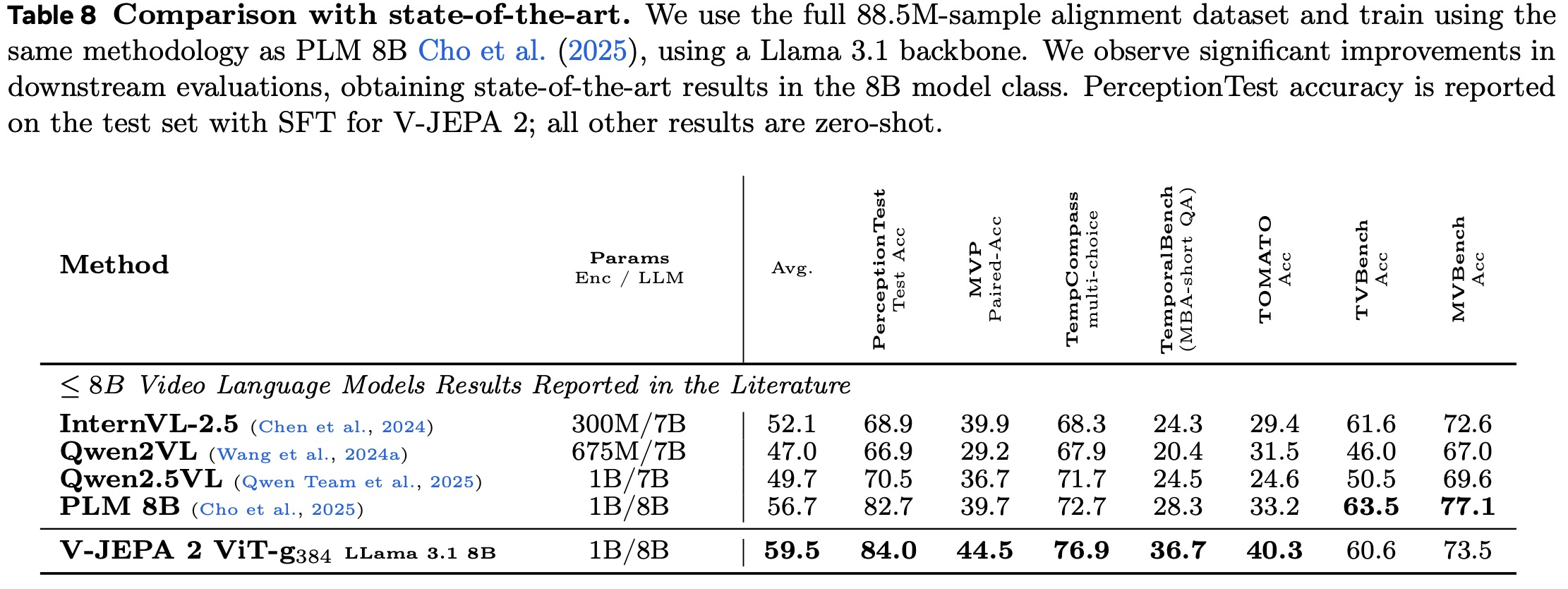
The model was trained on up to 88.5 million image- and video-text pairs. In controlled experiments with 18 million samples, V-JEPA 2 achieved competitive VidQA performance compared to other state-of-the-art encoders. Scaling the encoder size, input resolution, and alignment data further improved results, with V-JEPA 2 achieving state-of-the-art performance on several VidQA benchmarks.
paperreview deeplearning cv selfsupervised