Top-10 ML papers I read in 2025

This year, I wrote 30+ paper reviews. That was not a planned goal - it just happened while I was reading really interesting papers. A lot of research, unsurprisingly, went into LLMs: reasoning, training recipes, evaluation, and scaling laws. But not everything interesting this year was an LLM. There were strong papers on vision, agents, time series, evaluation benchmarks, and even re-thinking how we train “old” models like BERT.
I want to highlight ten papers that I was personally interested in — papers that introduced a particularly exciting idea, or simply felt like a glimpse into where the field is going next. This is a subjective list. It reflects my interests, my biases, and the kinds of questions I keep asking myself as an ML engineer.
I don’t include top LLMs, as their papers are usually technical reports with minimal detail.
DeepSeek-R1: Reasoning Without the Usual Crutches
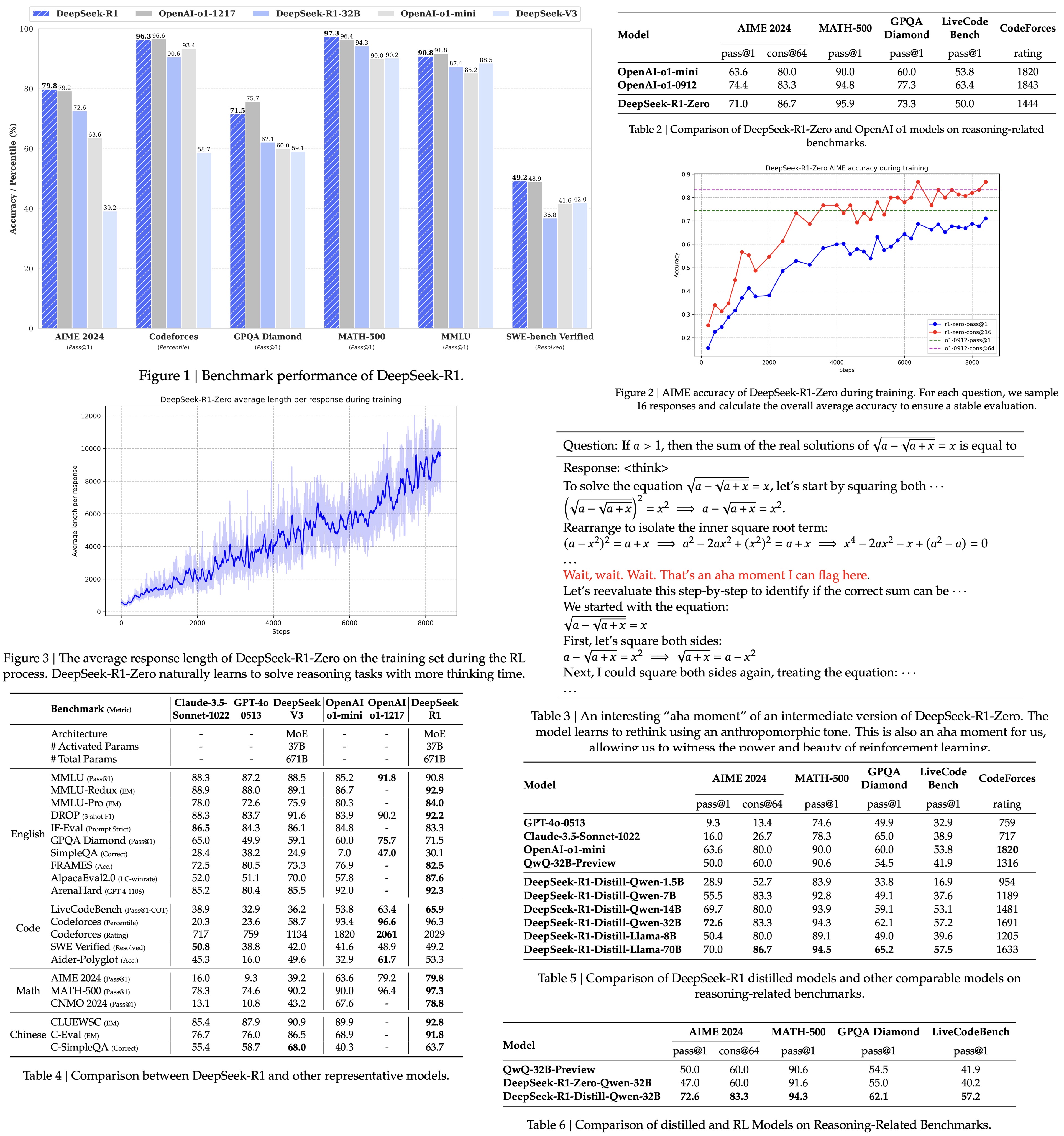
DeepSeek-R1 is one of the most interesting reasoning papers of the year because it challenged an assumption many had already accepted: that strong reasoning requires heavyweight tricks like supervised chain-of-thought or expensive human-annotated reasoning traces. It offered pure reinforcement learning instead. The model is pushed to reason better without being explicitly shown how to reason. This demonstrated that reasoning can emerge as a behavior, not just as imitation. This paper started a shift to investing more in RL and reward design for LLMs.
And, yes, it was published this year. Not an eternity ago - less than 12 months back.
GSPO: New Policy Optimization for LLMs
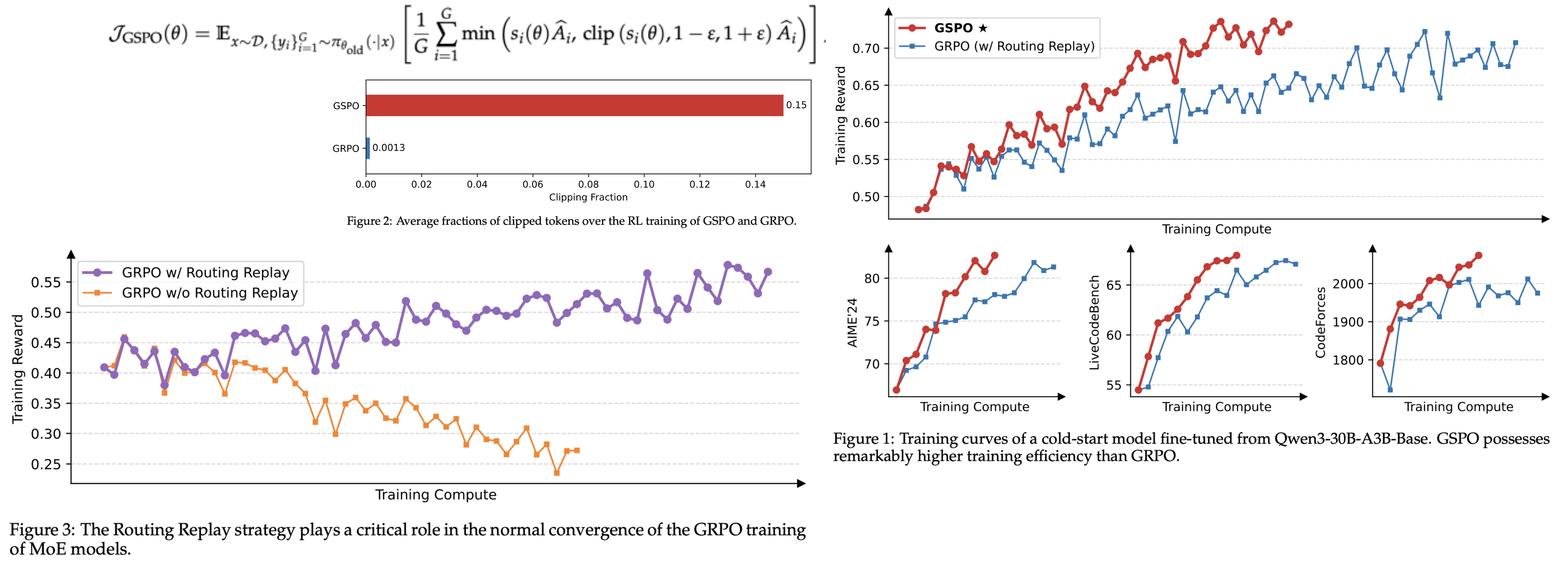
GSPO (Group Sequence Policy Optimization) was used in Qwen3 and contributed “remarkable improvements” to it. It used sequence-level importance ratios instead of token-level, provided more stable training, and simplified the design of RL infrastructure. It removed the need for a separate critic model by using group-based relative rewards, which further reduces the hardware requirements for training cutting-edge AI. What makes GSPO interesting is that it aligns the optimization objective with how we actually evaluate language models, reducing a class of failure modes that many pipelines quietly struggle with today.
Lumine: Generalist Agents in Open 3D Worlds
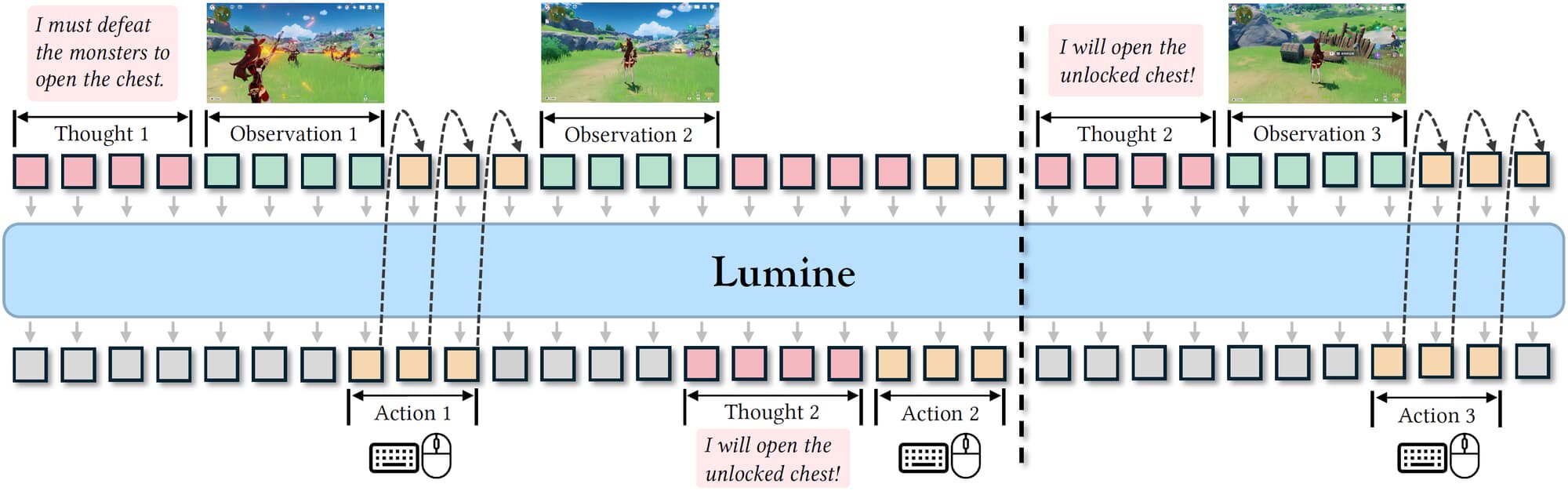
I didn’t write a review on Lumine, but this is a fascinating research. The paper presents an open recipe for training agents that can act, explore, and generalize in large 3D environments - open-ended worlds. The emphasis is on generalist behavior: navigation, interaction, adaptation. It blew my mind that this agent can play Genshin Impact and other games with reasonable efficiency.
SAM-3: Segment Anything Grows Up
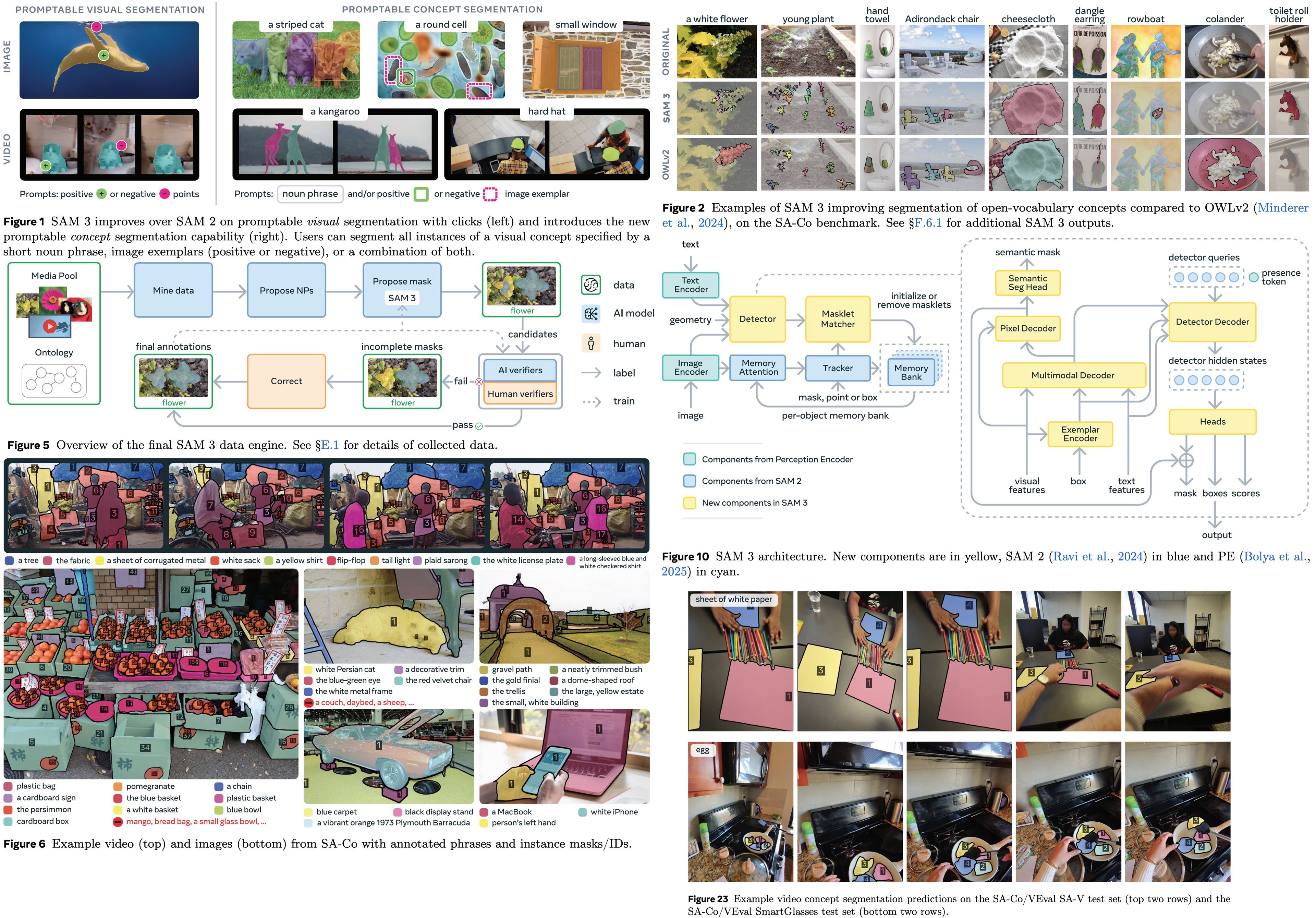
SAM-3 continues the evolution of the Segment Anything line and reflects a deeper understanding of what segmentation models are actually used for in real systems. The main impact is the transition from class-agnostic segmentation to semantically-aware segmentation. And users can prompt it not just with simple points, boxes, or nouns, but also with complex semantic concepts.
Chronos-2: Time Series Without task-specific training
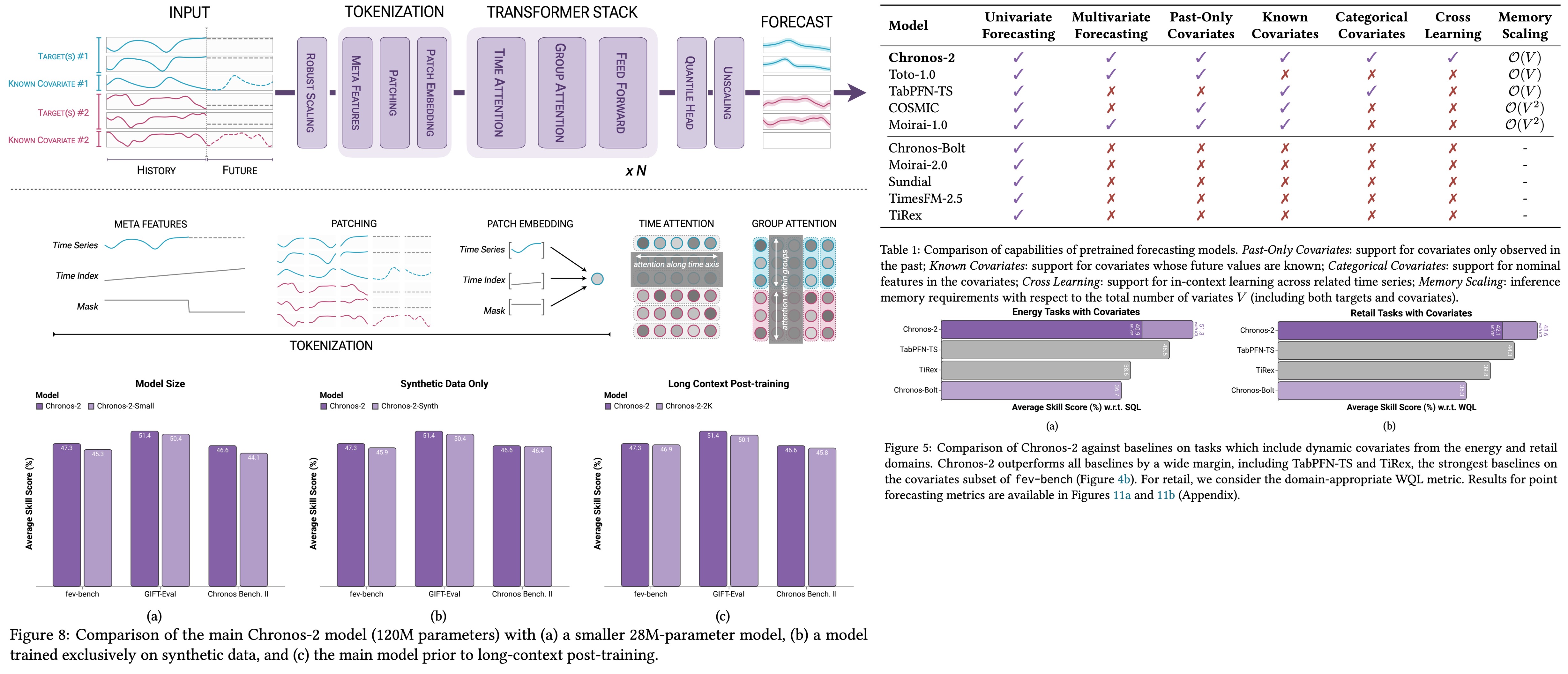
Chronos-2 treats time series forecasting as a sequence modeling problem, it builds on foundation-model ideas and shows that with the right training setup, you can get strong performance across diverse time series tasks without hand-crafted features or manual seasonality modeling. Chronos-2 suggests that we can have universal zero-shot time series forecasting.
NeoBERT: Modernizing BERT
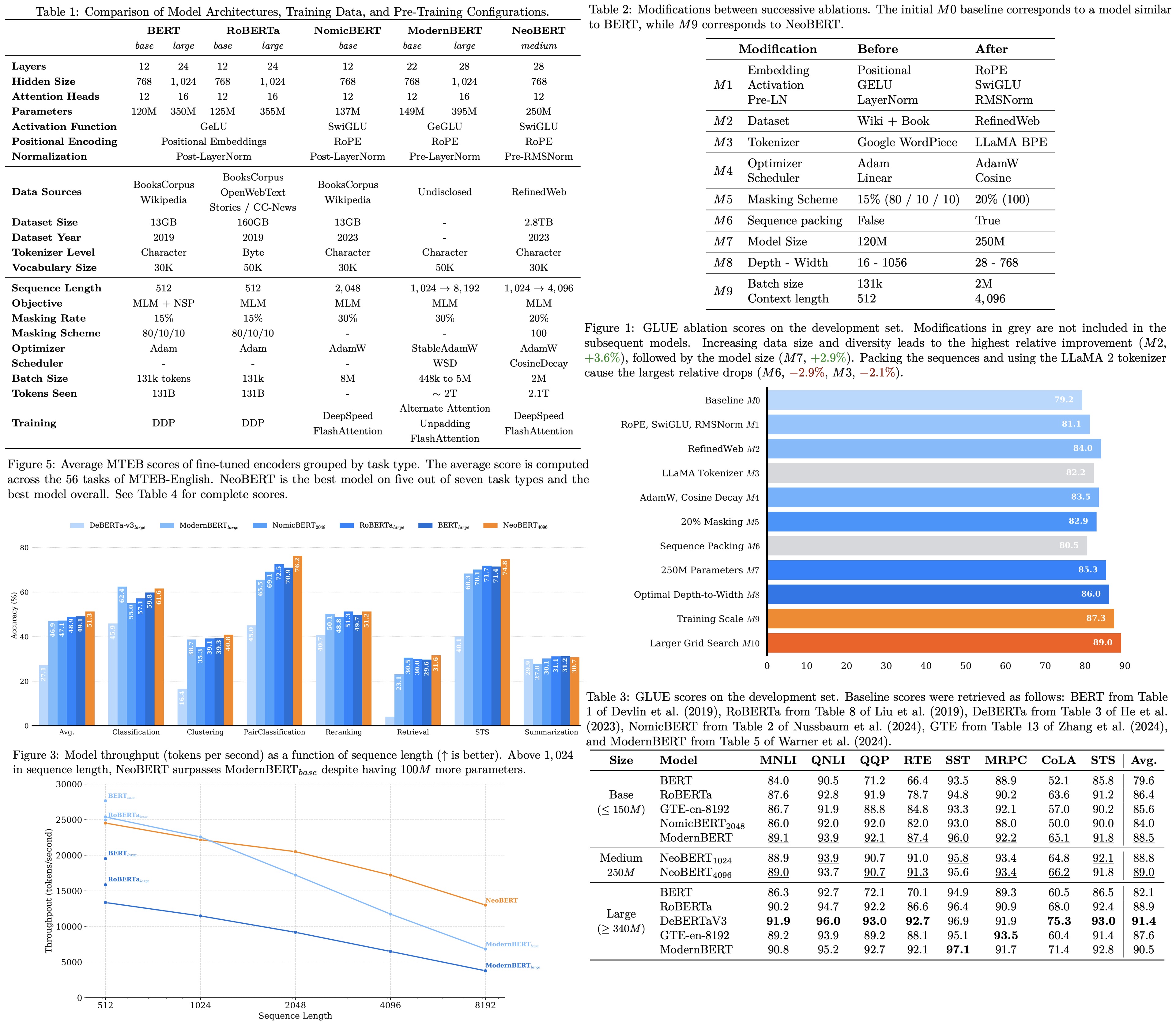
NeoBERT raised an interesting question: what if we trained BERT properly, using everything we’ve learned up to now? The paper revisits BERT with modern training techniques — better tokenization, better objectives, better optimization — and shows that you can still squeeze meaningful gains from it. What’s more interesting, it gets high scores on the MTEB benchmark, showing that its embeddings can rival modern models.
AlphaEvolve: Search Meets Learning
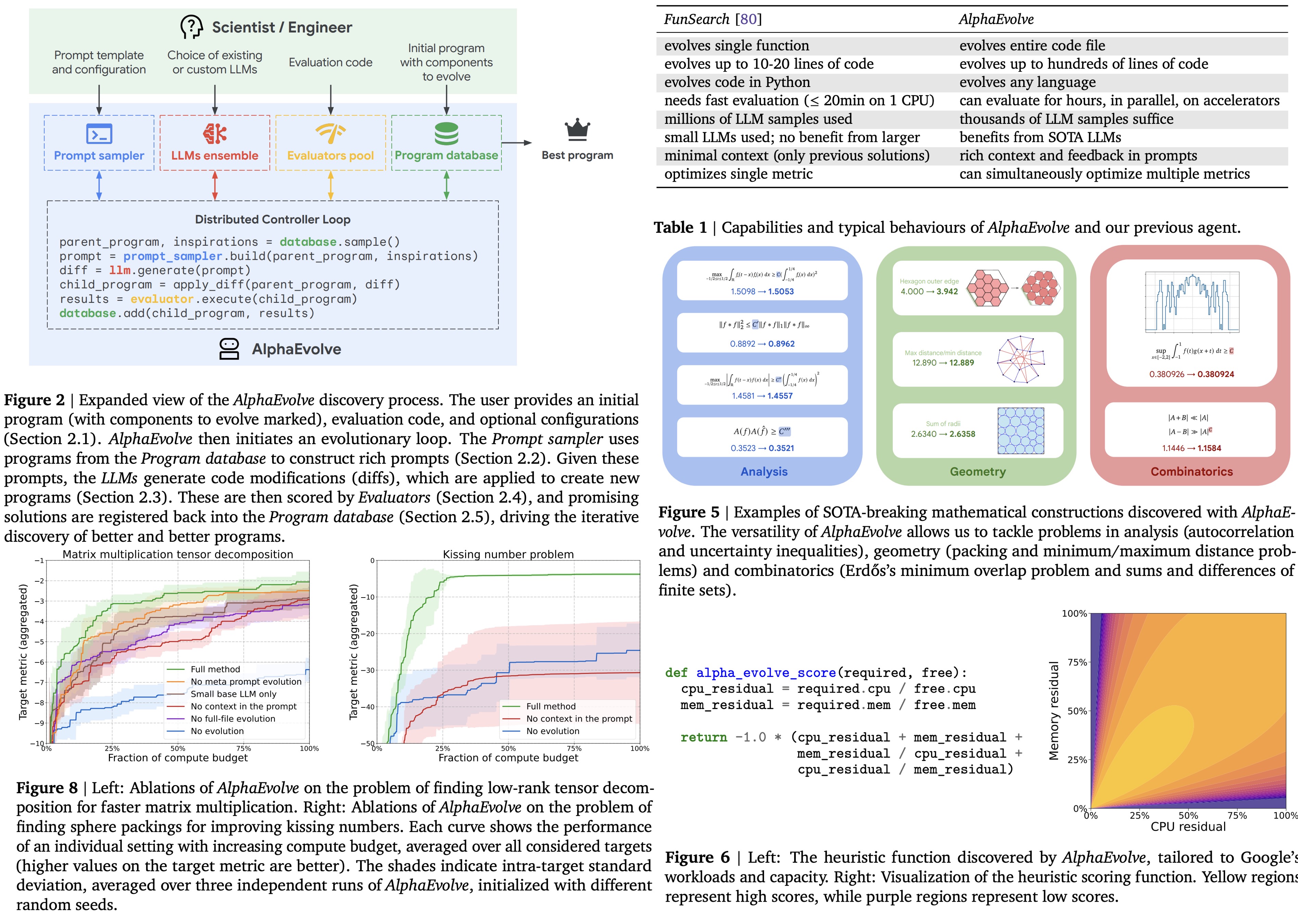
AlphaEvolve explores the space between evolutionary algorithms and modern learning systems. It shows how structured evolution can guide discovery in complex optimization spaces: it proposes solutions, evaluates them objectively and iteratively refines them.
SWE-rebench: Scalable and continuously updated benchmark

Instead of synthetic tasks or cherry-picked prompts, SWE-rebench evaluates models on real software engineering problems: fixing bugs in real repositories, under realistic constraints. The result is a benchmark that exposes just how brittle some “coding-capable” models still are.
DINOv3: Self-Supervised Vision Keeps Scaling
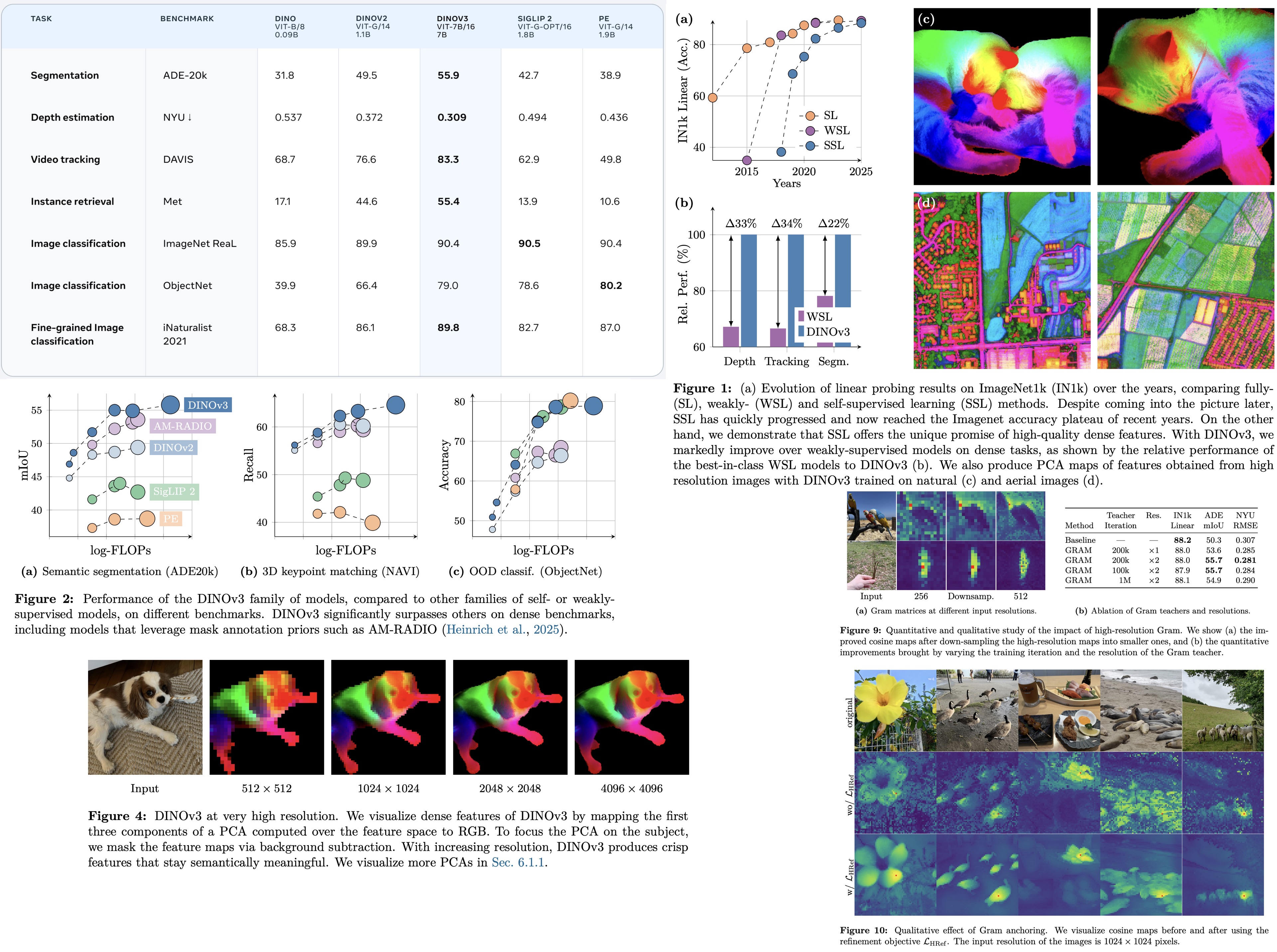
The paper refines the DINO approach with better training recipes and larger models, producing representations that transfer well across tasks without supervision. What stands out is how general these representations are: they feel less like features and more like visual understanding.
Dragon Hatchling: Small Models, Real Capabilities
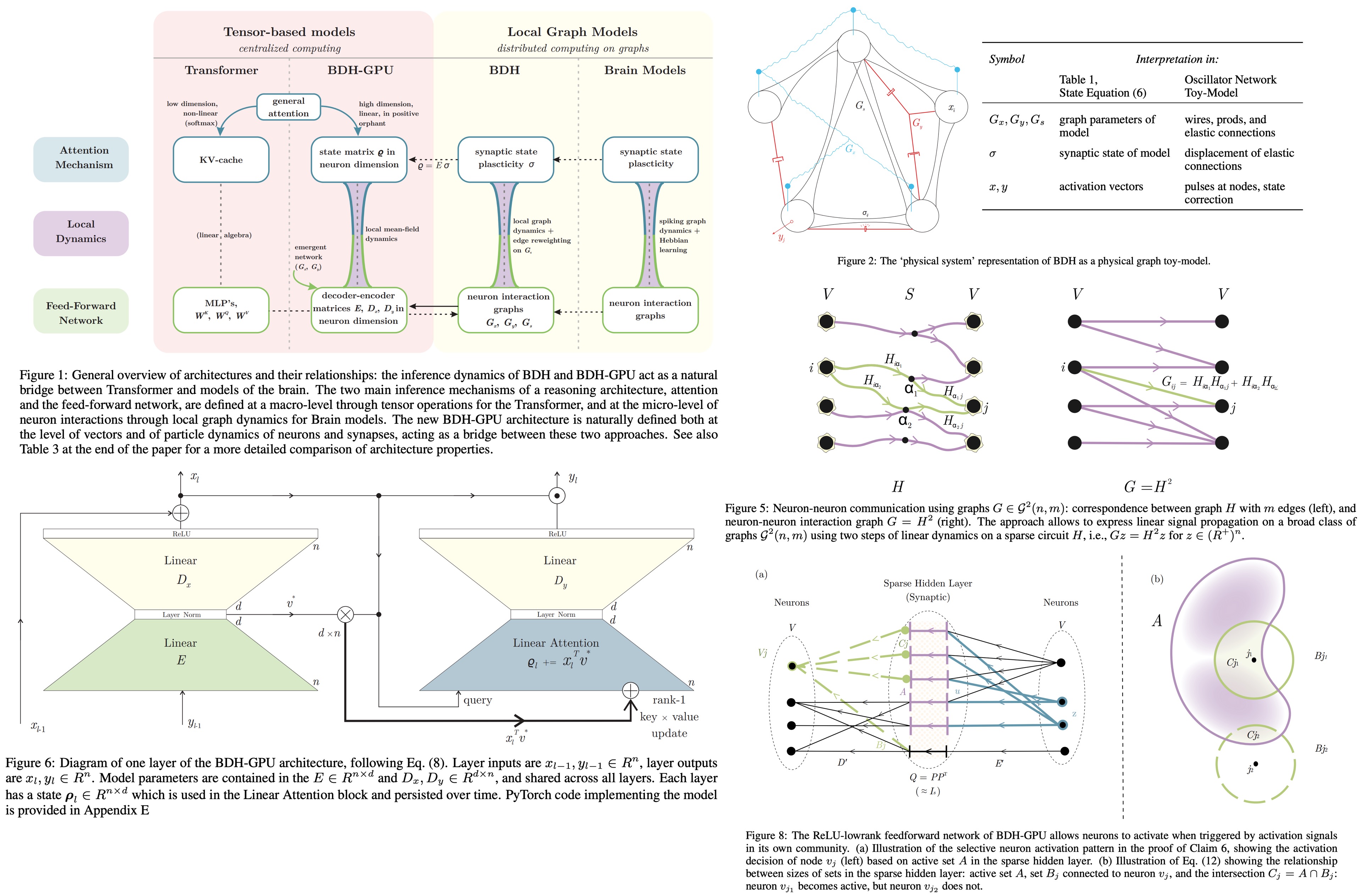
Dragon Hatchling focuses on small models that punch above their weight. Instead of assuming scale solves everything, the paper explores how careful training, curriculum design, and architectural choices can produce compact models with surprisingly strong reasoning and generalization abilities. Dragon Hatchling is a biologically inspired LLM built as a scale-free graph of locally interacting neuron-like units.
Closing Thoughts
This was an interesting year for ML research. We saw noticeable progress in LLMs, vision models, agents, and time series. There were many incremental improvements, but also some breakthroughs. LLMs dominate the research, but there are other interesting papers that combine different things: learning and search, vision and language, agents and environments.
This year was again about showing what foundation models can do, maybe the next one will be about figuring out how to make them reliable, grounded, and genuinely useful.
paperreview deeplearning blogpost